Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCognitive resilience: Unraveling the proficiency of image-captioning models to interpret masked visual content
Paper and Code
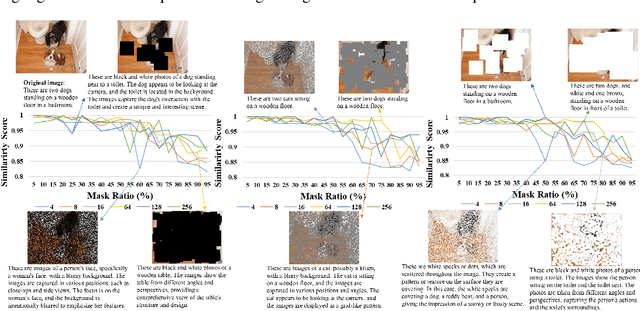
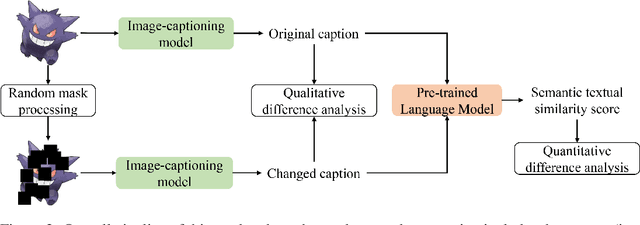
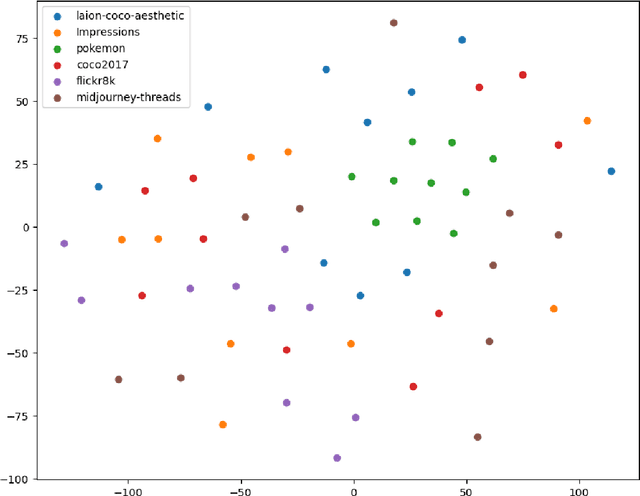

This study explores the ability of Image Captioning (IC) models to decode masked visual content sourced from diverse datasets. Our findings reveal the IC model's capability to generate captions from masked images, closely resembling the original content. Notably, even in the presence of masks, the model adeptly crafts descriptive textual information that goes beyond what is observable in the original image-generated captions. While the decoding performance of the IC model experiences a decline with an increase in the masked region's area, the model still performs well when important regions of the image are not masked at high coverage.
* Accepted as tiny paper in ICLR 2024
View paper on