 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS^2-Transformer for Mask-Aware Hyperspectral Image Reconstruction
Paper and Code
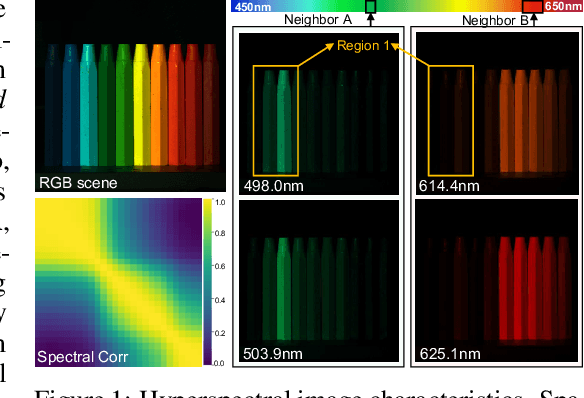
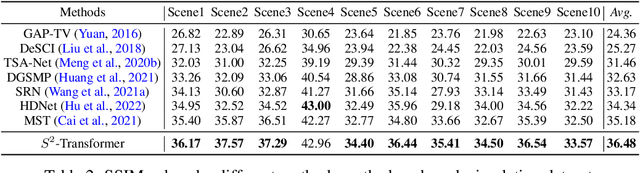
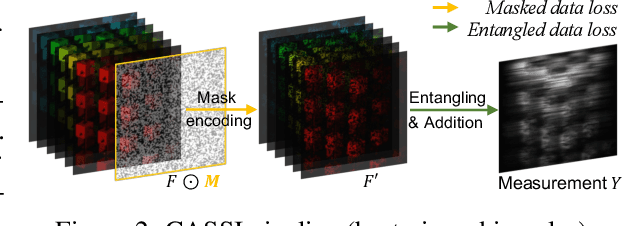
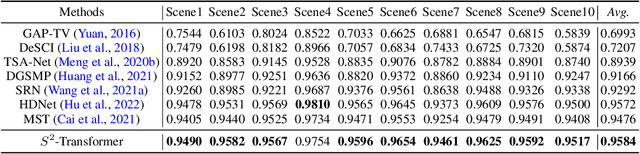
The technology of hyperspectral imaging (HSI) records the visual information upon long-range-distributed spectral wavelengths. A representative hyperspectral image acquisition procedure conducts a 3D-to-2D encoding by the coded aperture snapshot spectral imager (CASSI), and requires a software decoder for the 3D signal reconstruction. Based on this encoding procedure, two major challenges stand in the way of a high-fidelity reconstruction: (i) To obtain 2D measurements, CASSI dislocates multiple channels by disperser-titling and squeezes them onto the same spatial region, yielding an entangled data loss. (ii) The physical coded aperture (mask) will lead to a masked data loss by selectively blocking the pixel-wise light exposure. To tackle these challenges, we propose a spatial-spectral (S2-) transformer architecture with a mask-aware learning strategy. Firstly, we simultaneously leverage spatial and spectral attention modelings to disentangle the blended information in the 2D measurement along both two dimensions. A series of Transformer structures across spatial & spectral clues are systematically designed, which considers the information inter-dependency between the two-fold cues. Secondly, the masked pixels will induce higher prediction difficulty and should be treated differently from unmasked ones. Thereby, we adaptively prioritize the loss penalty attributing to the mask structure by inferring the difficulty-level upon the mask-aware prediction. Our proposed method not only sets a new state-of-the-art quantitatively, but also yields a better perceptual quality upon structured areas.