 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-trained Neural Recommenders: A Transferable Zero-Shot Framework for Recommendation Systems
Paper and Code
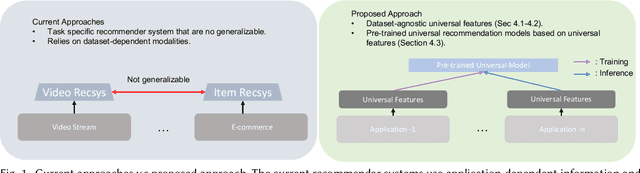
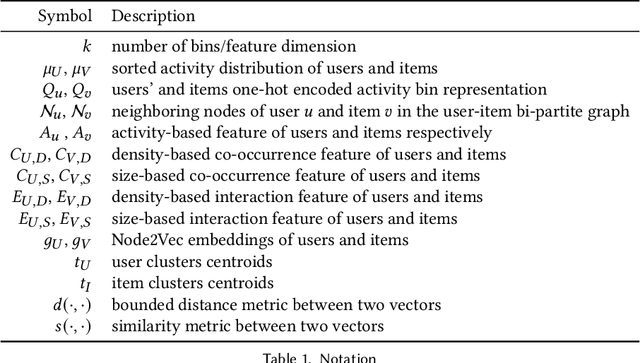
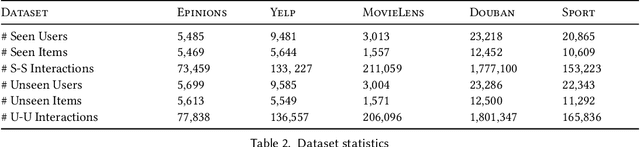
Modern neural collaborative filtering techniques are critical to the success of e-commerce, social media, and content-sharing platforms. However, despite technical advances -- for every new application domain, we need to train an NCF model from scratch. In contrast, pre-trained vision and language models are routinely applied to diverse applications directly (zero-shot) or with limited fine-tuning. Inspired by the impact of pre-trained models, we explore the possibility of pre-trained recommender models that support building recommender systems in new domains, with minimal or no retraining, without the use of any auxiliary user or item information. Zero-shot recommendation without auxiliary information is challenging because we cannot form associations between users and items across datasets when there are no overlapping users or items. Our fundamental insight is that the statistical characteristics of the user-item interaction matrix are universally available across different domains and datasets. Thus, we use the statistical characteristics of the user-item interaction matrix to identify dataset-independent representations for users and items. We show how to learn universal (i.e., supporting zero-shot adaptation without user or item auxiliary information) representations for nodes and edges from the bipartite user-item interaction graph. We learn representations by exploiting the statistical properties of the interaction data, including user and item marginals, and the size and density distributions of their clusters.