 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInf-VAE: A Variational Autoencoder Framework to Integrate Homophily and Influence in Diffusion Prediction
Paper and Code

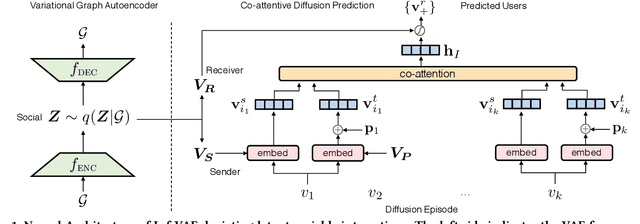
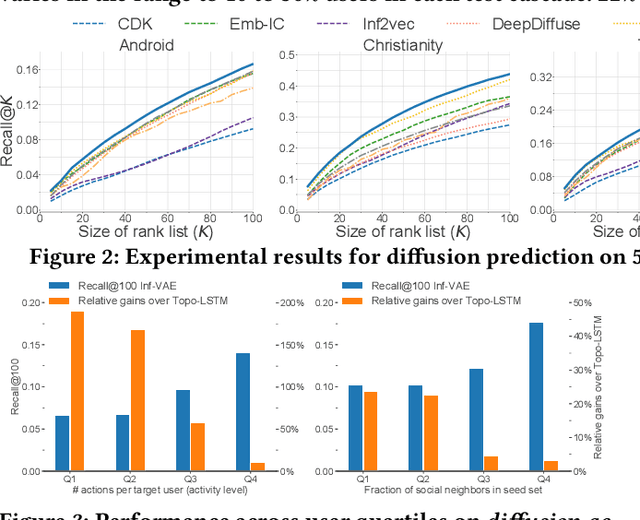
Recent years have witnessed tremendous interest in understanding and predicting information spread on social media platforms such as Twitter, Facebook, etc. Existing diffusion prediction methods primarily exploit the sequential order of influenced users by projecting diffusion cascades onto their local social neighborhoods. However, this fails to capture global social structures that do not explicitly manifest in any of the cascades, resulting in poor performance for inactive users with limited historical activities. In this paper, we present a novel variational autoencoder framework (Inf-VAE) to jointly embed homophily and influence through proximity-preserving social and position-encoded temporal latent variables. To model social homophily, Inf-VAE utilizes powerful graph neural network architectures to learn social variables that selectively exploit the social connections of users. Given a sequence of seed user activations, Inf-VAE uses a novel expressive co-attentive fusion network that jointly attends over their social and temporal variables to predict the set of all influenced users. Our experimental results on multiple real-world social network datasets, including Digg, Weibo, and Stack-Exchanges demonstrate significant gains (22% MAP@10) for Inf-VAE over state-of-the-art diffusion prediction models; we achieve massive gains for users with sparse activities, and users who lack direct social neighbors in seed sets.