 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudience-Centric Natural Language Generation via Style Infusion
Jan 24, 2023Adopting contextually appropriate, audience-tailored linguistic styles is critical to the success of user-centric language generation systems (e.g., chatbots, computer-aided writing, dialog systems). While existing approaches demonstrate textual style transfer with large volumes of parallel or non-parallel data, we argue that grounding style on audience-independent external factors is innately limiting for two reasons. First, it is difficult to collect large volumes of audience-specific stylistic data. Second, some stylistic objectives (e.g., persuasiveness, memorability, empathy) are hard to define without audience feedback. In this paper, we propose the novel task of style infusion - infusing the stylistic preferences of audiences in pretrained language generation models. Since humans are better at pairwise comparisons than direct scoring - i.e., is Sample-A more persuasive/polite/empathic than Sample-B - we leverage limited pairwise human judgments to bootstrap a style analysis model and augment our seed set of judgments. We then infuse the learned textual style in a GPT-2 based text generator while balancing fluency and style adoption. With quantitative and qualitative assessments, we show that our infusion approach can generate compelling stylized examples with generic text prompts. The code and data are accessible at https://github.com/CrowdDynamicsLab/StyleInfusion.
Sparsity-aware neural user behavior modeling in online interaction platforms
Feb 28, 2022


Modern online platforms offer users an opportunity to participate in a variety of content-creation, social networking, and shopping activities. With the rapid proliferation of such online services, learning data-driven user behavior models is indispensable to enable personalized user experiences. Recently, representation learning has emerged as an effective strategy for user modeling, powered by neural networks trained over large volumes of interaction data. Despite their enormous potential, we encounter the unique challenge of data sparsity for a vast majority of entities, e.g., sparsity in ground-truth labels for entities and in entity-level interactions (cold-start users, items in the long-tail, and ephemeral groups). In this dissertation, we develop generalizable neural representation learning frameworks for user behavior modeling designed to address different sparsity challenges across applications. Our problem settings span transductive and inductive learning scenarios, where transductive learning models entities seen during training and inductive learning targets entities that are only observed during inference. We leverage different facets of information reflecting user behavior (e.g., interconnectivity in social networks, temporal and attributed interaction information) to enable personalized inference at scale. Our proposed models are complementary to concurrent advances in neural architectural choices and are adaptive to the rapid addition of new applications in online platforms.
Beyond Localized Graph Neural Networks: An Attributed Motif Regularization Framework
Sep 11, 2020
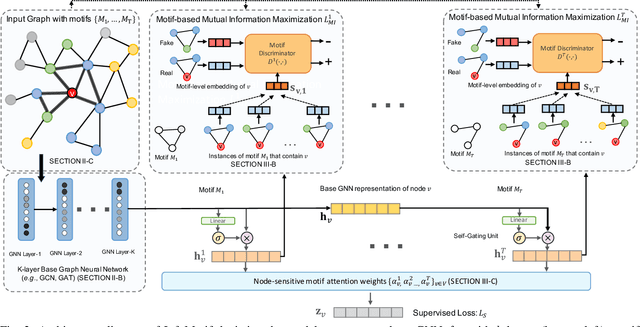
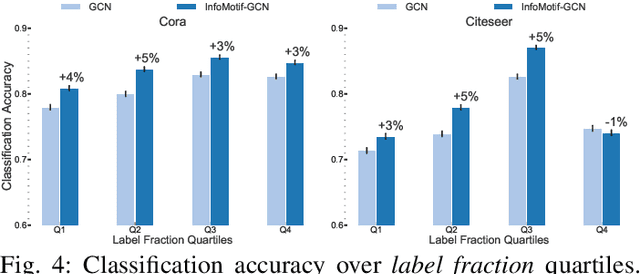
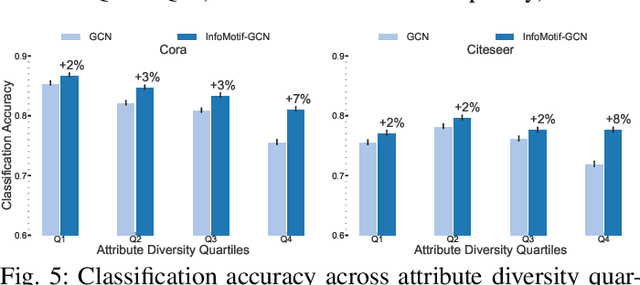
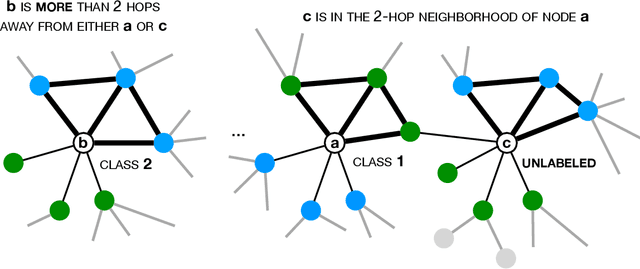
We present InfoMotif, a new semi-supervised, motif-regularized, learning framework over graphs. We overcome two key limitations of message passing in popular graph neural networks (GNNs): localization (a k-layer GNN cannot utilize features outside the k-hop neighborhood of the labeled training nodes) and over-smoothed (structurally indistinguishable) representations. We propose the concept of attributed structural roles of nodes based on their occurrence in different network motifs, independent of network proximity. Two nodes share attributed structural roles if they participate in topologically similar motif instances over co-varying sets of attributes. Further, InfoMotif achieves architecture independence by regularizing the node representations of arbitrary GNNs via mutual information maximization. Our training curriculum dynamically prioritizes multiple motifs in the learning process without relying on distributional assumptions in the underlying graph or the learning task. We integrate three state-of-the-art GNNs in our framework, to show significant gains (3-10% accuracy) across six diverse, real-world datasets. We see stronger gains for nodes with sparse training labels and diverse attributes in local neighborhood structures.
GroupIM: A Mutual Information Maximization Framework for Neural Group Recommendation
Jun 09, 2020



We study the problem of making item recommendations to ephemeral groups, which comprise users with limited or no historical activities together. Existing studies target persistent groups with substantial activity history, while ephemeral groups lack historical interactions. To overcome group interaction sparsity, we propose data-driven regularization strategies to exploit both the preference covariance amongst users who are in the same group, as well as the contextual relevance of users' individual preferences to each group. We make two contributions. First, we present a recommender architecture-agnostic framework GroupIM that can integrate arbitrary neural preference encoders and aggregators for ephemeral group recommendation. Second, we regularize the user-group latent space to overcome group interaction sparsity by: maximizing mutual information between representations of groups and group members; and dynamically prioritizing the preferences of highly informative members through contextual preference weighting. Our experimental results on several real-world datasets indicate significant performance improvements (31-62% relative NDCG@20) over state-of-the-art group recommendation techniques.
Inf-VAE: A Variational Autoencoder Framework to Integrate Homophily and Influence in Diffusion Prediction
Jan 01, 2020
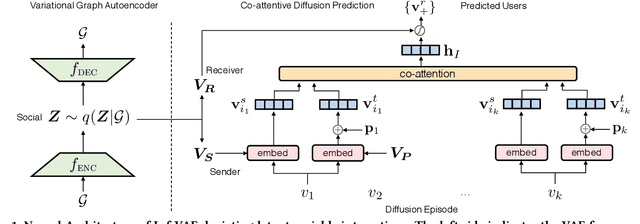
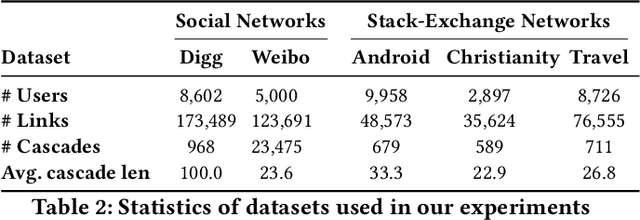
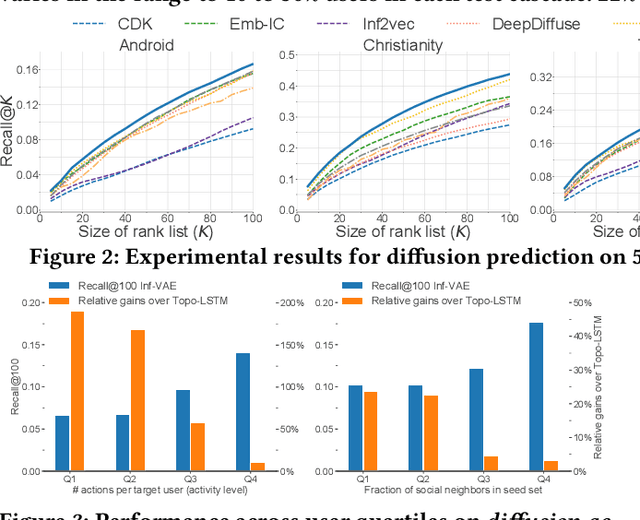
Recent years have witnessed tremendous interest in understanding and predicting information spread on social media platforms such as Twitter, Facebook, etc. Existing diffusion prediction methods primarily exploit the sequential order of influenced users by projecting diffusion cascades onto their local social neighborhoods. However, this fails to capture global social structures that do not explicitly manifest in any of the cascades, resulting in poor performance for inactive users with limited historical activities. In this paper, we present a novel variational autoencoder framework (Inf-VAE) to jointly embed homophily and influence through proximity-preserving social and position-encoded temporal latent variables. To model social homophily, Inf-VAE utilizes powerful graph neural network architectures to learn social variables that selectively exploit the social connections of users. Given a sequence of seed user activations, Inf-VAE uses a novel expressive co-attentive fusion network that jointly attends over their social and temporal variables to predict the set of all influenced users. Our experimental results on multiple real-world social network datasets, including Digg, Weibo, and Stack-Exchanges demonstrate significant gains (22% MAP@10) for Inf-VAE over state-of-the-art diffusion prediction models; we achieve massive gains for users with sparse activities, and users who lack direct social neighbors in seed sets.
Dynamic Graph Representation Learning via Self-Attention Networks
Dec 22, 2018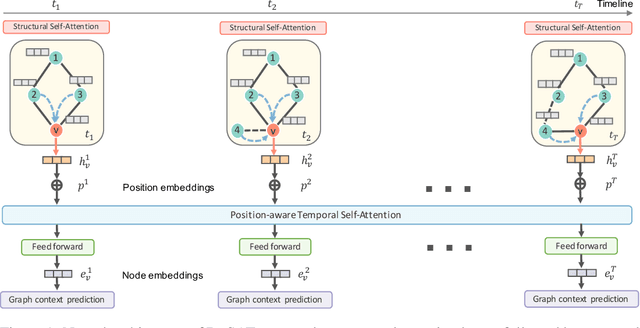
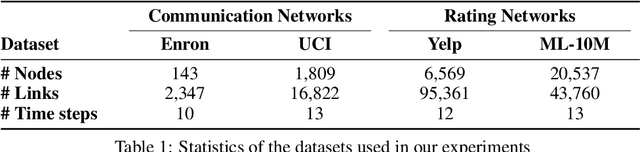
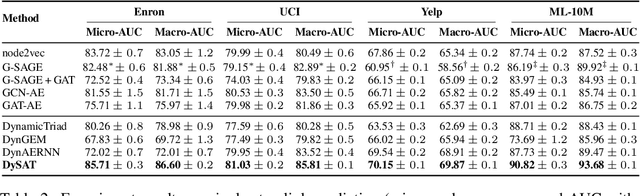

Learning latent representations of nodes in graphs is an important and ubiquitous task with widespread applications such as link prediction, node classification, and graph visualization. Previous methods on graph representation learning mainly focus on static graphs, however, many real-world graphs are dynamic and evolve over time. In this paper, we present Dynamic Self-Attention Network (DySAT), a novel neural architecture that operates on dynamic graphs and learns node representations that capture both structural properties and temporal evolutionary patterns. Specifically, DySAT computes node representations by jointly employing self-attention layers along two dimensions: structural neighborhood and temporal dynamics. We conduct link prediction experiments on two classes of graphs: communication networks and bipartite rating networks. Our experimental results show that DySAT has a significant performance gain over several different state-of-the-art graph embedding baselines.
Motif-based Convolutional Neural Network on Graphs
Feb 05, 2018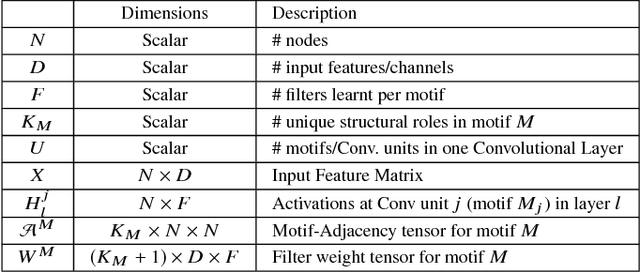
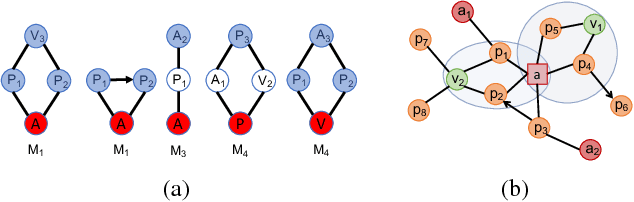
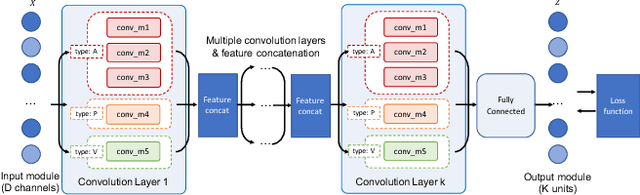
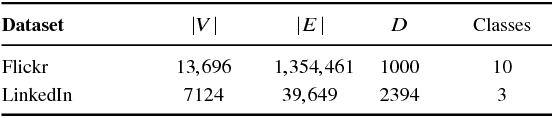
This paper introduces a generalization of Convolutional Neural Networks (CNNs) to graphs with irregular linkage structures, especially heterogeneous graphs with typed nodes and schemas. We propose a novel spatial convolution operation to model the key properties of local connectivity and translation invariance, using high-order connection patterns or motifs. We develop a novel deep architecture Motif-CNN that employs an attention model to combine the features extracted from multiple patterns, thus effectively capturing high-order structural and feature information. Our experiments on semi-supervised node classification on real-world social networks and multiple representative heterogeneous graph datasets indicate significant gains of 6-21% over existing graph CNNs and other state-of-the-art techniques.