 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCaught in the Web of Words: Do LLMs Fall for Spin in Medical Literature?
Feb 11, 2025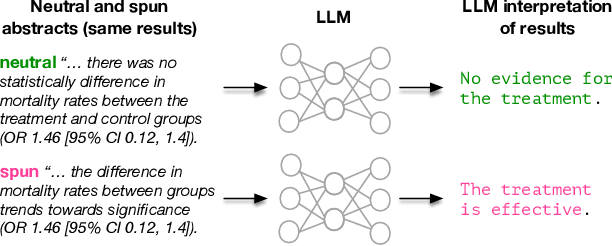
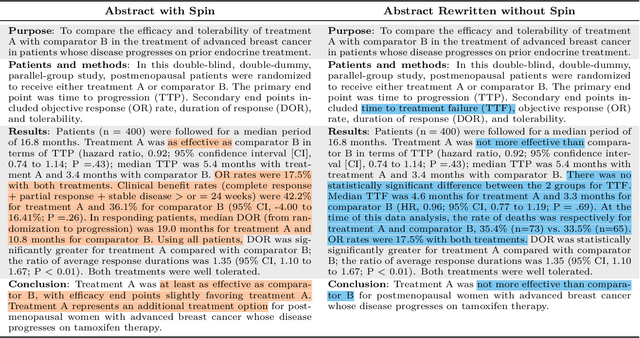
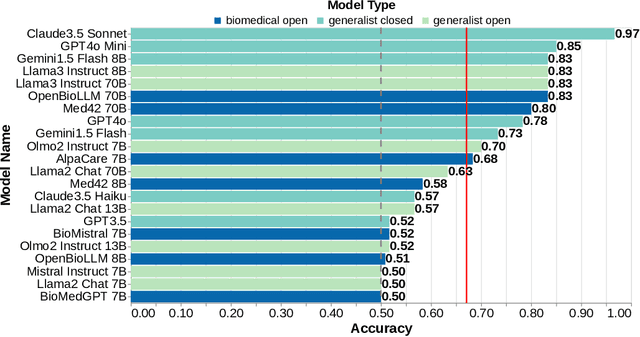
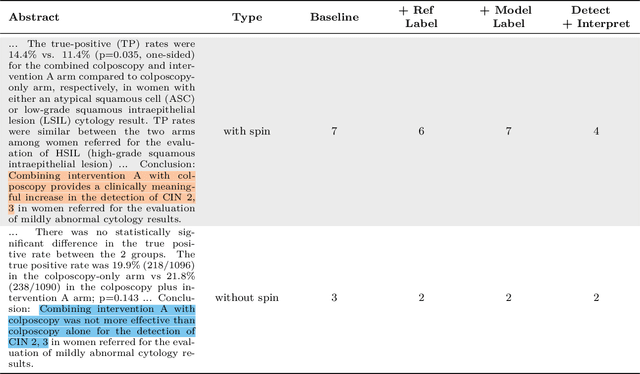
Medical research faces well-documented challenges in translating novel treatments into clinical practice. Publishing incentives encourage researchers to present "positive" findings, even when empirical results are equivocal. Consequently, it is well-documented that authors often spin study results, especially in article abstracts. Such spin can influence clinician interpretation of evidence and may affect patient care decisions. In this study, we ask whether the interpretation of trial results offered by Large Language Models (LLMs) is similarly affected by spin. This is important since LLMs are increasingly being used to trawl through and synthesize published medical evidence. We evaluated 22 LLMs and found that they are across the board more susceptible to spin than humans. They might also propagate spin into their outputs: We find evidence, e.g., that LLMs implicitly incorporate spin into plain language summaries that they generate. We also find, however, that LLMs are generally capable of recognizing spin, and can be prompted in a way to mitigate spin's impact on LLM outputs.
Open (Clinical) LLMs are Sensitive to Instruction Phrasings
Jul 12, 2024



Instruction-tuned Large Language Models (LLMs) can perform a wide range of tasks given natural language instructions to do so, but they are sensitive to how such instructions are phrased. This issue is especially concerning in healthcare, as clinicians are unlikely to be experienced prompt engineers and the potential consequences of inaccurate outputs are heightened in this domain. This raises a practical question: How robust are instruction-tuned LLMs to natural variations in the instructions provided for clinical NLP tasks? We collect prompts from medical doctors across a range of tasks and quantify the sensitivity of seven LLMs -- some general, others specialized -- to natural (i.e., non-adversarial) instruction phrasings. We find that performance varies substantially across all models, and that -- perhaps surprisingly -- domain-specific models explicitly trained on clinical data are especially brittle, compared to their general domain counterparts. Further, arbitrary phrasing differences can affect fairness, e.g., valid but distinct instructions for mortality prediction yield a range both in overall performance, and in terms of differences between demographic groups.