 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaithfulness vs. Safety: Evaluating LLM Behavior Under Counterfactual Medical Evidence
Jan 17, 2026In high-stakes domains like medicine, it may be generally desirable for models to faithfully adhere to the context provided. But what happens if the context does not align with model priors or safety protocols? In this paper, we investigate how LLMs behave and reason when presented with counterfactual or even adversarial medical evidence. We first construct MedCounterFact, a counterfactual medical QA dataset that requires the models to answer clinical comparison questions (i.e., judge the efficacy of certain treatments, with evidence consisting of randomized controlled trials provided as context). In MedCounterFact, real-world medical interventions within the questions and evidence are systematically replaced with four types of counterfactual stimuli, ranging from unknown words to toxic substances. Our evaluation across multiple frontier LLMs on MedCounterFact reveals that in the presence of counterfactual evidence, existing models overwhelmingly accept such "evidence" at face value even when it is dangerous or implausible, and provide confident and uncaveated answers. While it may be prudent to draw a boundary between faithfulness and safety, our findings reveal that there exists no such boundary yet.
Decide less, communicate more: On the construct validity of end-to-end fact-checking in medicine
Jun 25, 2025Technological progress has led to concrete advancements in tasks that were regarded as challenging, such as automatic fact-checking. Interest in adopting these systems for public health and medicine has grown due to the high-stakes nature of medical decisions and challenges in critically appraising a vast and diverse medical literature. Evidence-based medicine connects to every individual, and yet the nature of it is highly technical, rendering the medical literacy of majority users inadequate to sufficiently navigate the domain. Such problems with medical communication ripens the ground for end-to-end fact-checking agents: check a claim against current medical literature and return with an evidence-backed verdict. And yet, such systems remain largely unused. To understand this, we present the first study examining how clinical experts verify real claims from social media by synthesizing medical evidence. In searching for this upper-bound, we reveal fundamental challenges in end-to-end fact-checking when applied to medicine: Difficulties connecting claims in the wild to scientific evidence in the form of clinical trials; ambiguities in underspecified claims mixed with mismatched intentions; and inherently subjective veracity labels. We argue that fact-checking should be approached and evaluated as an interactive communication problem, rather than an end-to-end process.
Caught in the Web of Words: Do LLMs Fall for Spin in Medical Literature?
Feb 11, 2025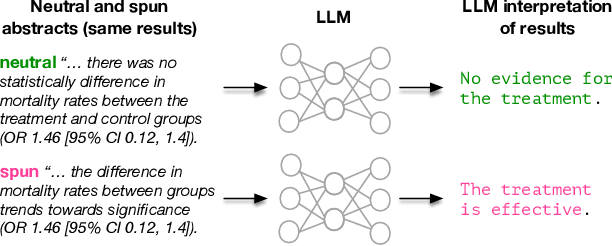
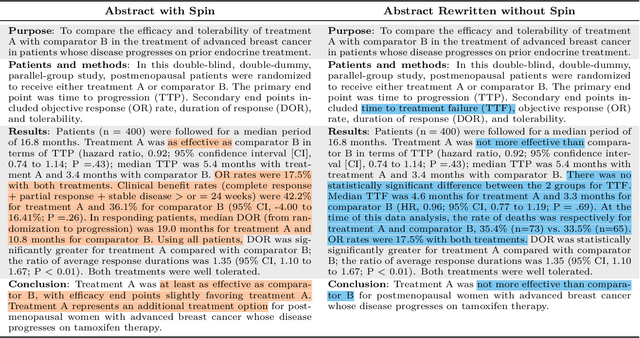
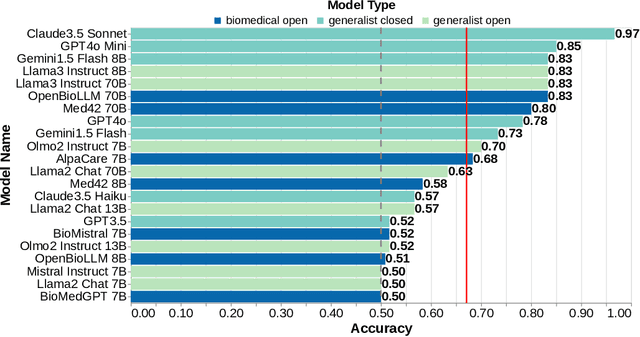
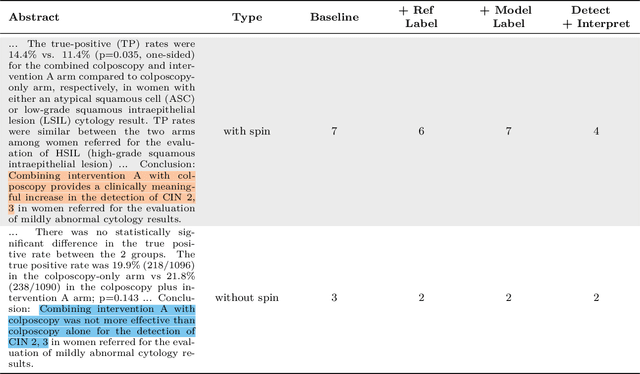
Medical research faces well-documented challenges in translating novel treatments into clinical practice. Publishing incentives encourage researchers to present "positive" findings, even when empirical results are equivocal. Consequently, it is well-documented that authors often spin study results, especially in article abstracts. Such spin can influence clinician interpretation of evidence and may affect patient care decisions. In this study, we ask whether the interpretation of trial results offered by Large Language Models (LLMs) is similarly affected by spin. This is important since LLMs are increasingly being used to trawl through and synthesize published medical evidence. We evaluated 22 LLMs and found that they are across the board more susceptible to spin than humans. They might also propagate spin into their outputs: We find evidence, e.g., that LLMs implicitly incorporate spin into plain language summaries that they generate. We also find, however, that LLMs are generally capable of recognizing spin, and can be prompted in a way to mitigate spin's impact on LLM outputs.
QuaLLM-Health: An Adaptation of an LLM-Based Framework for Quantitative Data Extraction from Online Health Discussions
Nov 27, 2024Health-related discussions on social media like Reddit offer valuable insights, but extracting quantitative data from unstructured text is challenging. In this work, we present an adapted framework from QuaLLM into QuaLLM-Health for extracting clinically relevant quantitative data from Reddit discussions about glucagon-like peptide-1 (GLP-1) receptor agonists using large language models (LLMs). We collected 410k posts and comments from five GLP-1-related communities using the Reddit API in July 2024. After filtering for cancer-related discussions, 2,059 unique entries remained. We developed annotation guidelines to manually extract variables such as cancer survivorship, family cancer history, cancer types mentioned, risk perceptions, and discussions with physicians. Two domain-experts independently annotated a random sample of 100 entries to create a gold-standard dataset. We then employed iterative prompt engineering with OpenAI's "GPT-4o-mini" on the gold-standard dataset to build an optimized pipeline that allowed us to extract variables from the large dataset. The optimized LLM achieved accuracies above 0.85 for all variables, with precision, recall and F1 score macro averaged > 0.90, indicating balanced performance. Stability testing showed a 95% match rate across runs, confirming consistency. Applying the framework to the full dataset enabled efficient extraction of variables necessary for downstream analysis, costing under $3 and completing in approximately one hour. QuaLLM-Health demonstrates that LLMs can effectively and efficiently extract clinically relevant quantitative data from unstructured social media content. Incorporating human expertise and iterative prompt refinement ensures accuracy and reliability. This methodology can be adapted for large-scale analysis of patient-generated data across various health domains, facilitating valuable insights for healthcare research.