 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Mysteries of CoT-Augmented Distillation
Paper and Code
Jun 20, 2024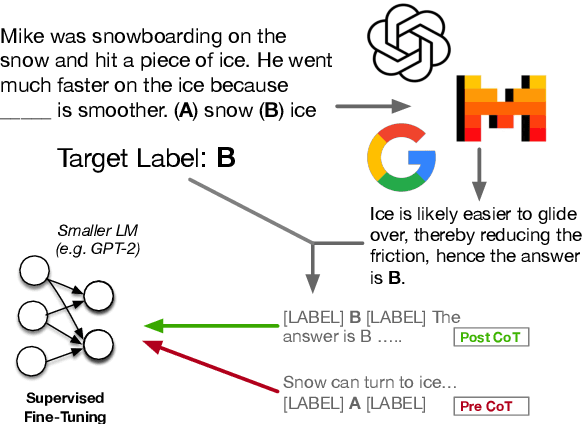
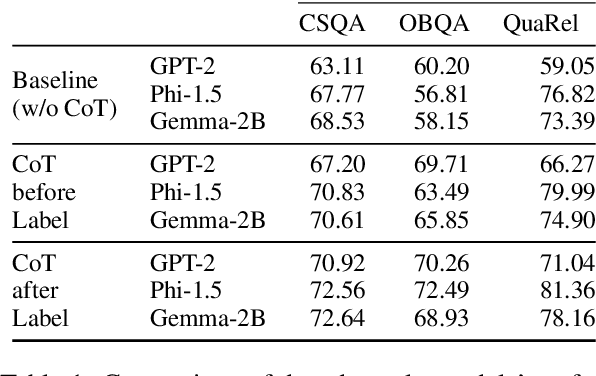
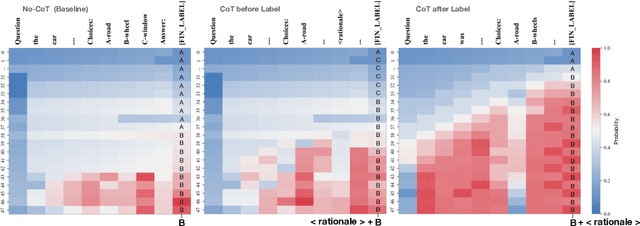
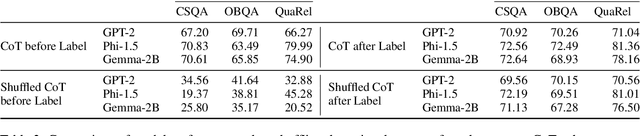
Eliciting "chain of thought" (CoT) rationales -- sequences of token that convey a "reasoning" process -- has been shown to consistently improve LLM performance on tasks like question answering. More recent efforts have shown that such rationales can also be used for model distillation: Including CoT sequences (elicited from a large "teacher" model) in addition to target labels when fine-tuning a small student model yields (often substantial) improvements. In this work we ask: Why and how does this additional training signal help in model distillation? We perform ablations to interrogate this, and report some potentially surprising results. Specifically: (1) Placing CoT sequences after labels (rather than before) realizes consistently better downstream performance -- this means that no student "reasoning" is necessary at test time to realize gains. (2) When rationales are appended in this way, they need not be coherent reasoning sequences to yield improvements; performance increases are robust to permutations of CoT tokens, for example. In fact, (3) a small number of key tokens are sufficient to achieve improvements equivalent to those observed when full rationales are used in model distillation.