 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo Move or Not to Move: Constraint-based Planning Enables Zero-Shot Generalization for Interactive Navigation
Feb 23, 2026Visual navigation typically assumes the existence of at least one obstacle-free path between start and goal, which must be discovered/planned by the robot. However, in real-world scenarios, such as home environments and warehouses, clutter can block all routes. Targeted at such cases, we introduce the Lifelong Interactive Navigation problem, where a mobile robot with manipulation abilities can move clutter to forge its own path to complete sequential object- placement tasks - each involving placing an given object (eg. Alarm clock, Pillow) onto a target object (eg. Dining table, Desk, Bed). To address this lifelong setting - where effects of environment changes accumulate and have long-term effects - we propose an LLM-driven, constraint-based planning framework with active perception. Our framework allows the LLM to reason over a structured scene graph of discovered objects and obstacles, deciding which object to move, where to place it, and where to look next to discover task-relevant information. This coupling of reasoning and active perception allows the agent to explore the regions expected to contribute to task completion rather than exhaustively mapping the environment. A standard motion planner then executes the corresponding navigate-pick-place, or detour sequence, ensuring reliable low-level control. Evaluated in physics-enabled ProcTHOR-10k simulator, our approach outperforms non-learning and learning-based baselines. We further demonstrate our approach qualitatively on real-world hardware.
VLAD-Grasp: Zero-shot Grasp Detection via Vision-Language Models
Nov 08, 2025Robotic grasping is a fundamental capability for autonomous manipulation; however, most existing methods rely on large-scale expert annotations and necessitate retraining to handle new objects. We present VLAD-Grasp, a Vision-Language model Assisted zero-shot approach for Detecting grasps. From a single RGB-D image, our method (1) prompts a large vision-language model to generate a goal image where a straight rod "impales" the object, representing an antipodal grasp, (2) predicts depth and segmentation to lift this generated image into 3D, and (3) aligns generated and observed object point clouds via principal component analysis and correspondence-free optimization to recover an executable grasp pose. Unlike prior work, our approach is training-free and does not rely on curated grasp datasets. Despite this, VLAD-Grasp achieves performance that is competitive with or superior to that of state-of-the-art supervised models on the Cornell and Jacquard datasets. We further demonstrate zero-shot generalization to novel real-world objects on a Franka Research 3 robot, highlighting vision-language foundation models as powerful priors for robotic manipulation.
Structural Concept Learning via Graph Attention for Multi-Level Rearrangement Planning
Sep 05, 2023
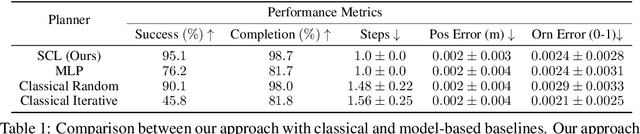
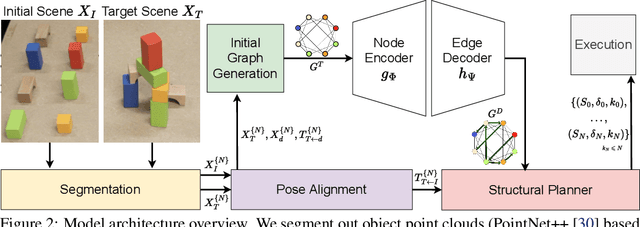
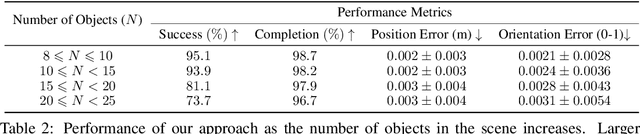
Robotic manipulation tasks, such as object rearrangement, play a crucial role in enabling robots to interact with complex and arbitrary environments. Existing work focuses primarily on single-level rearrangement planning and, even if multiple levels exist, dependency relations among substructures are geometrically simpler, like tower stacking. We propose Structural Concept Learning (SCL), a deep learning approach that leverages graph attention networks to perform multi-level object rearrangement planning for scenes with structural dependency hierarchies. It is trained on a self-generated simulation data set with intuitive structures, works for unseen scenes with an arbitrary number of objects and higher complexity of structures, infers independent substructures to allow for task parallelization over multiple manipulators, and generalizes to the real world. We compare our method with a range of classical and model-based baselines to show that our method leverages its scene understanding to achieve better performance, flexibility, and efficiency. The dataset, supplementary details, videos, and code implementation are available at: https://manavkulshrestha.github.io/scl
PROVES: Establishing Image Provenance using Semantic Signatures
Oct 21, 2021
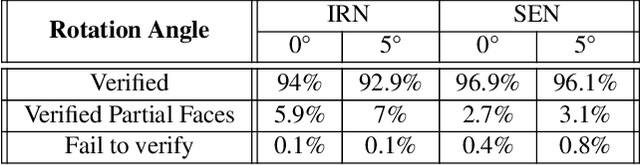
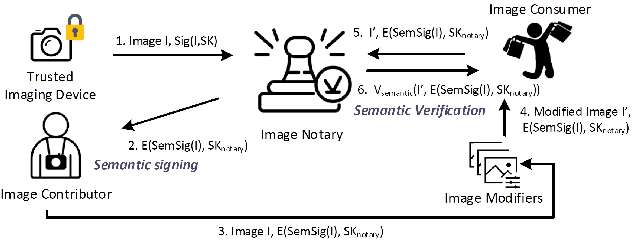
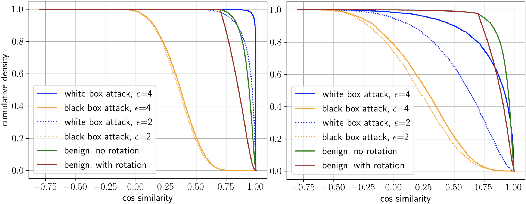
Modern AI tools, such as generative adversarial networks, have transformed our ability to create and modify visual data with photorealistic results. However, one of the deleterious side-effects of these advances is the emergence of nefarious uses in manipulating information in visual data, such as through the use of deep fakes. We propose a novel architecture for preserving the provenance of semantic information in images to make them less susceptible to deep fake attacks. Our architecture includes semantic signing and verification steps. We apply this architecture to verifying two types of semantic information: individual identities (faces) and whether the photo was taken indoors or outdoors. Verification accounts for a collection of common image transformation, such as translation, scaling, cropping, and small rotations, and rejects adversarial transformations, such as adversarially perturbed or, in the case of face verification, swapped faces. Experiments demonstrate that in the case of provenance of faces in an image, our approach is robust to black-box adversarial transformations (which are rejected) as well as benign transformations (which are accepted), with few false negatives and false positives. Background verification, on the other hand, is susceptible to black-box adversarial examples, but becomes significantly more robust after adversarial training.