 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Data Augmentation for Translation Suggestion
Oct 12, 2022

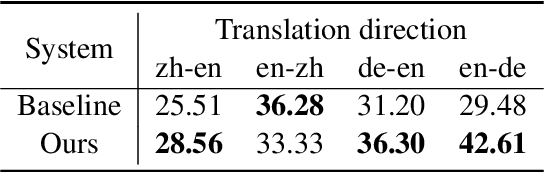

Translation suggestion (TS) models are used to automatically provide alternative suggestions for incorrect spans in sentences generated by machine translation. This paper introduces the system used in our submission to the WMT'22 Translation Suggestion shared task. Our system is based on the ensemble of different translation architectures, including Transformer, SA-Transformer, and DynamicConv. We use three strategies to construct synthetic data from parallel corpora to compensate for the lack of supervised data. In addition, we introduce a multi-phase pre-training strategy, adding an additional pre-training phase with in-domain data. We rank second and third on the English-German and English-Chinese bidirectional tasks, respectively.
Cross-Align: Modeling Deep Cross-lingual Interactions for Word Alignment
Oct 09, 2022



Word alignment which aims to extract lexicon translation equivalents between source and target sentences, serves as a fundamental tool for natural language processing. Recent studies in this area have yielded substantial improvements by generating alignments from contextualized embeddings of the pre-trained multilingual language models. However, we find that the existing approaches capture few interactions between the input sentence pairs, which degrades the word alignment quality severely, especially for the ambiguous words in the monolingual context. To remedy this problem, we propose Cross-Align to model deep interactions between the input sentence pairs, in which the source and target sentences are encoded separately with the shared self-attention modules in the shallow layers, while cross-lingual interactions are explicitly constructed by the cross-attention modules in the upper layers. Besides, to train our model effectively, we propose a two-stage training framework, where the model is trained with a simple Translation Language Modeling (TLM) objective in the first stage and then finetuned with a self-supervised alignment objective in the second stage. Experiments show that the proposed Cross-Align achieves the state-of-the-art (SOTA) performance on four out of five language pairs.
Generating Authentic Adversarial Examples beyond Meaning-preserving with Doubly Round-trip Translation
Apr 19, 2022



Generating adversarial examples for Neural Machine Translation (NMT) with single Round-Trip Translation (RTT) has achieved promising results by releasing the meaning-preserving restriction. However, a potential pitfall for this approach is that we cannot decide whether the generated examples are adversarial to the target NMT model or the auxiliary backward one, as the reconstruction error through the RTT can be related to either. To remedy this problem, we propose a new criterion for NMT adversarial examples based on the Doubly Round-Trip Translation (DRTT). Specifically, apart from the source-target-source RTT, we also consider the target-source-target one, which is utilized to pick out the authentic adversarial examples for the target NMT model. Additionally, to enhance the robustness of the NMT model, we introduce the masked language models to construct bilingual adversarial pairs based on DRTT, which are used to train the NMT model directly. Extensive experiments on both the clean and noisy test sets (including the artificial and natural noise) show that our approach substantially improves the robustness of NMT models.