 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRectifying Reinforcement Learning for Reward Matching
Paper and Code
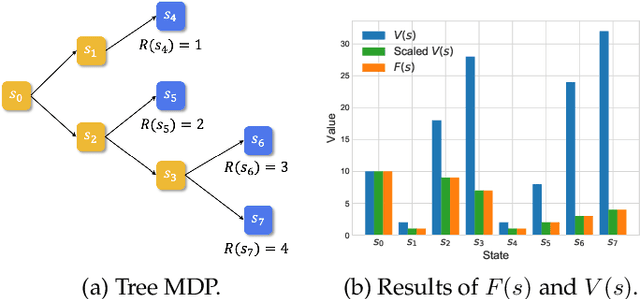
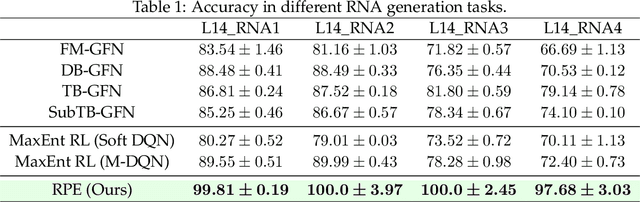
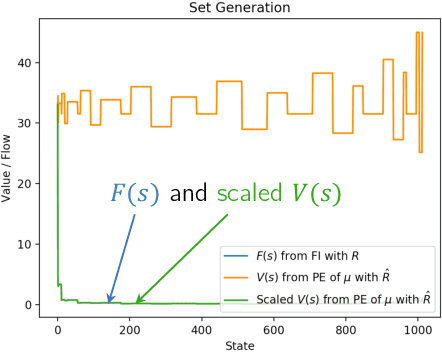
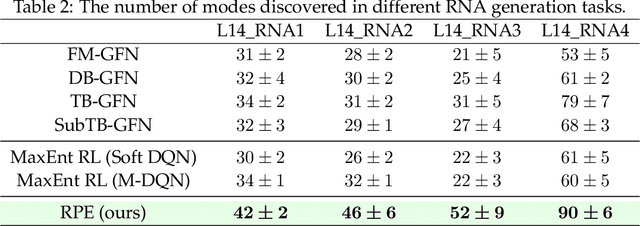
The Generative Flow Network (GFlowNet) is a probabilistic framework in which an agent learns a stochastic policy and flow functions to sample objects with probability proportional to an unnormalized reward function. GFlowNets share a strong resemblance to reinforcement learning (RL), that typically aims to maximize reward, due to their sequential decision-making processes. Recent works have studied connections between GFlowNets and maximum entropy (MaxEnt) RL, which modifies the standard objective of RL agents by learning an entropy-regularized objective. However, a critical theoretical gap persists: despite the apparent similarities in their sequential decision-making nature, a direct link between GFlowNets and standard RL has yet to be discovered, while bridging this gap could further unlock the potential of both fields. In this paper, we establish a new connection between GFlowNets and policy evaluation for a uniform policy. Surprisingly, we find that the resulting value function for the uniform policy has a close relationship to the flows in GFlowNets. Leveraging these insights, we further propose a novel rectified policy evaluation (RPE) algorithm, which achieves the same reward-matching effect as GFlowNets, offering a new perspective. We compare RPE, MaxEnt RL, and GFlowNets in a number of benchmarks, and show that RPE achieves competitive results compared to previous approaches. This work sheds light on the previously unexplored connection between (non-MaxEnt) RL and GFlowNets, potentially opening new avenues for future research in both fields.