 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Data Gap in AI Reliability Research and Establishing DR-AIR, a Comprehensive Data Repository for AI Reliability
Feb 17, 2025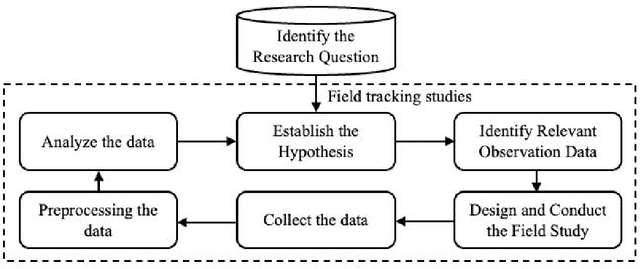
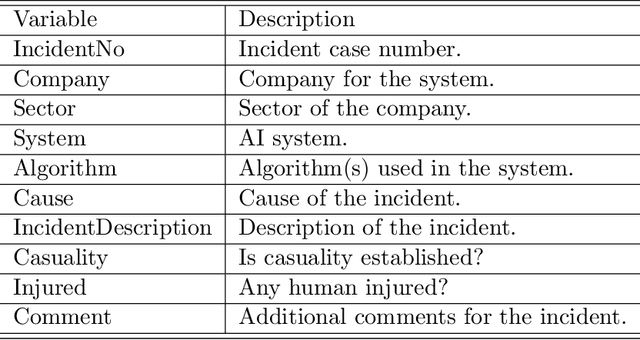


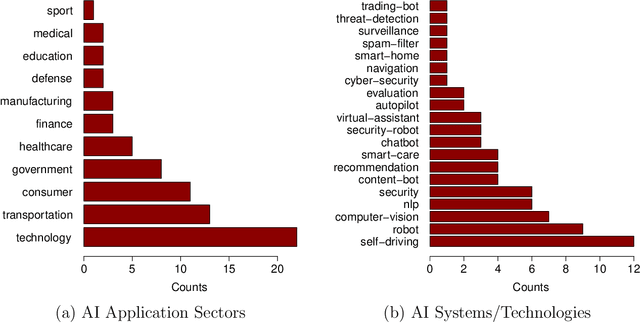
Artificial intelligence (AI) technology and systems have been advancing rapidly. However, ensuring the reliability of these systems is crucial for fostering public confidence in their use. This necessitates the modeling and analysis of reliability data specific to AI systems. A major challenge in AI reliability research, particularly for those in academia, is the lack of readily available AI reliability data. To address this gap, this paper focuses on conducting a comprehensive review of available AI reliability data and establishing DR-AIR: a data repository for AI reliability. Specifically, we introduce key measurements and data types for assessing AI reliability, along with the methodologies used to collect these data. We also provide a detailed description of the currently available datasets with illustrative examples. Furthermore, we outline the setup of the DR-AIR repository and demonstrate its practical applications. This repository provides easy access to datasets specifically curated for AI reliability research. We believe these efforts will significantly benefit the AI research community by facilitating access to valuable reliability data and promoting collaboration across various academic domains within AI. We conclude our paper with a call to action, encouraging the research community to contribute and share AI reliability data to further advance this critical field of study.
Statistical Perspectives on Reliability of Artificial Intelligence Systems
Nov 09, 2021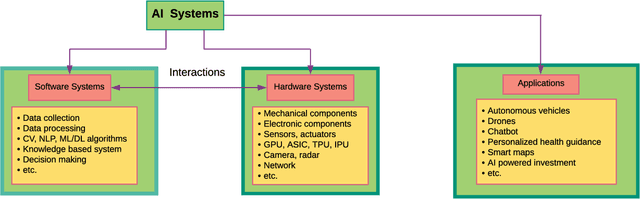
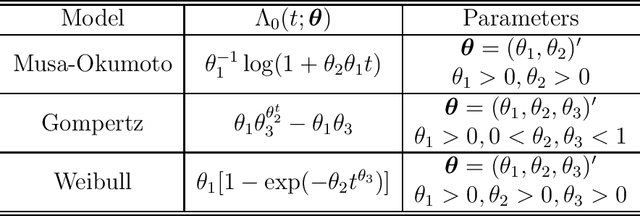
Artificial intelligence (AI) systems have become increasingly popular in many areas. Nevertheless, AI technologies are still in their developing stages, and many issues need to be addressed. Among those, the reliability of AI systems needs to be demonstrated so that the AI systems can be used with confidence by the general public. In this paper, we provide statistical perspectives on the reliability of AI systems. Different from other considerations, the reliability of AI systems focuses on the time dimension. That is, the system can perform its designed functionality for the intended period. We introduce a so-called SMART statistical framework for AI reliability research, which includes five components: Structure of the system, Metrics of reliability, Analysis of failure causes, Reliability assessment, and Test planning. We review traditional methods in reliability data analysis and software reliability, and discuss how those existing methods can be transformed for reliability modeling and assessment of AI systems. We also describe recent developments in modeling and analysis of AI reliability and outline statistical research challenges in this area, including out-of-distribution detection, the effect of the training set, adversarial attacks, model accuracy, and uncertainty quantification, and discuss how those topics can be related to AI reliability, with illustrative examples. Finally, we discuss data collection and test planning for AI reliability assessment and how to improve system designs for higher AI reliability. The paper closes with some concluding remarks.
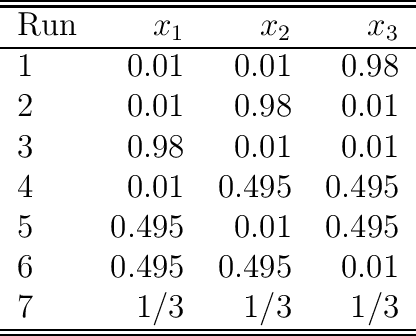
Investigating the Robustness of Artificial Intelligent Algorithms with Mixture Experiments
Oct 10, 2020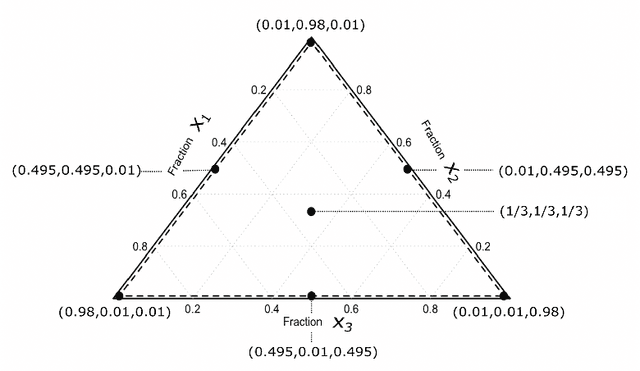
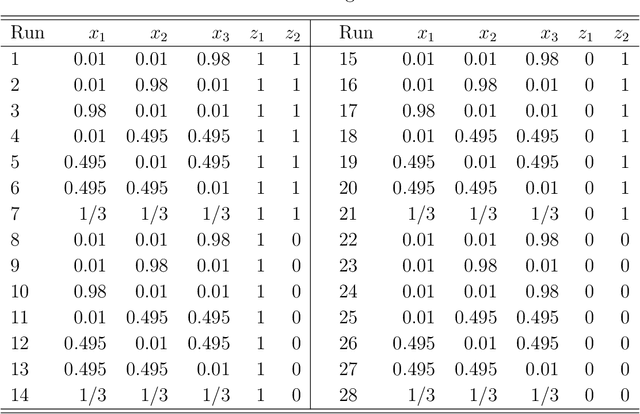
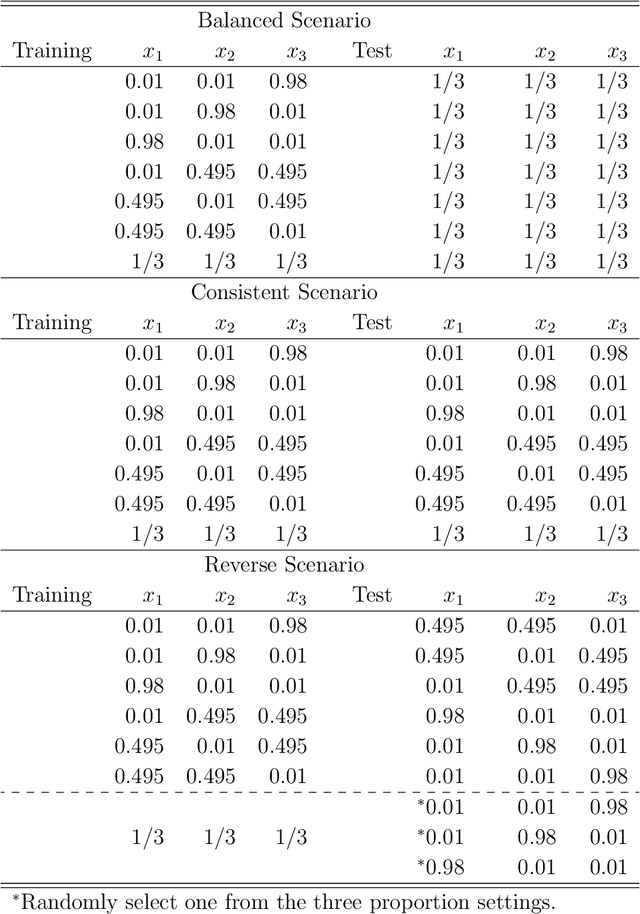
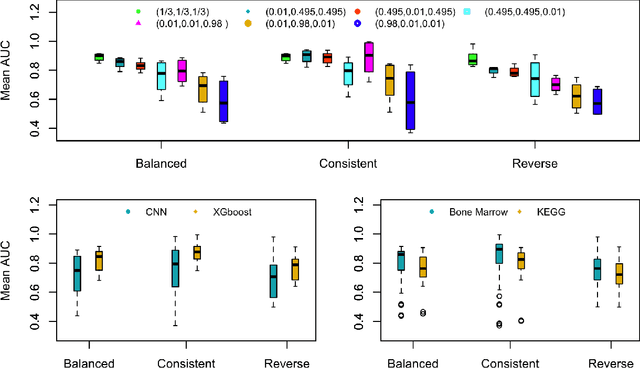
Artificial intelligent (AI) algorithms, such as deep learning and XGboost, are used in numerous applications including computer vision, autonomous driving, and medical diagnostics. The robustness of these AI algorithms is of great interest as inaccurate prediction could result in safety concerns and limit the adoption of AI systems. In this paper, we propose a framework based on design of experiments to systematically investigate the robustness of AI classification algorithms. A robust classification algorithm is expected to have high accuracy and low variability under different application scenarios. The robustness can be affected by a wide range of factors such as the imbalance of class labels in the training dataset, the chosen prediction algorithm, the chosen dataset of the application, and a change of distribution in the training and test datasets. To investigate the robustness of AI classification algorithms, we conduct a comprehensive set of mixture experiments to collect prediction performance results. Then statistical analyses are conducted to understand how various factors affect the robustness of AI classification algorithms. We summarize our findings and provide suggestions to practitioners in AI applications.