 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest & Evaluation Best Practices for Machine Learning-Enabled Systems
Oct 10, 2023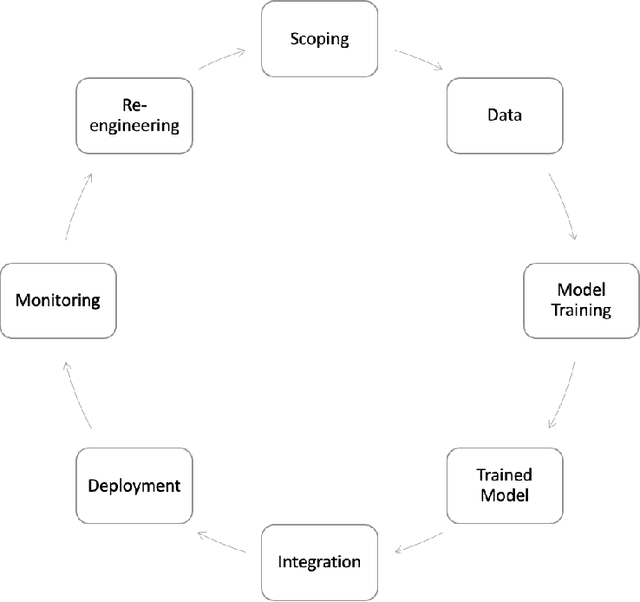
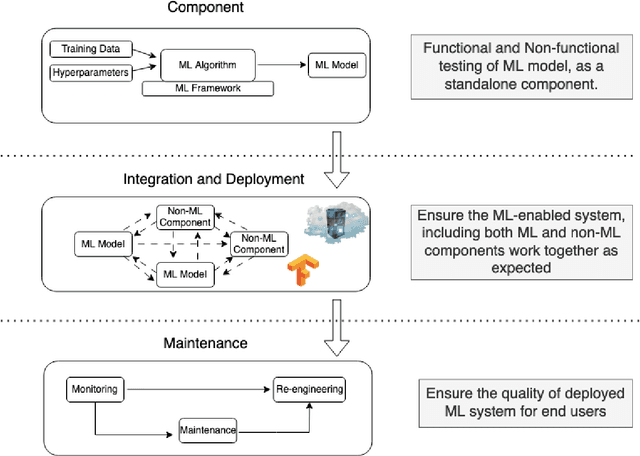
Machine learning (ML) - based software systems are rapidly gaining adoption across various domains, making it increasingly essential to ensure they perform as intended. This report presents best practices for the Test and Evaluation (T&E) of ML-enabled software systems across its lifecycle. We categorize the lifecycle of ML-enabled software systems into three stages: component, integration and deployment, and post-deployment. At the component level, the primary objective is to test and evaluate the ML model as a standalone component. Next, in the integration and deployment stage, the goal is to evaluate an integrated ML-enabled system consisting of both ML and non-ML components. Finally, once the ML-enabled software system is deployed and operationalized, the T&E objective is to ensure the system performs as intended. Maintenance activities for ML-enabled software systems span the lifecycle and involve maintaining various assets of ML-enabled software systems. Given its unique characteristics, the T&E of ML-enabled software systems is challenging. While significant research has been reported on T&E at the component level, limited work is reported on T&E in the remaining two stages. Furthermore, in many cases, there is a lack of systematic T&E strategies throughout the ML-enabled system's lifecycle. This leads practitioners to resort to ad-hoc T&E practices, which can undermine user confidence in the reliability of ML-enabled software systems. New systematic testing approaches, adequacy measurements, and metrics are required to address the T&E challenges across all stages of the ML-enabled system lifecycle.
Metric Learning Improves the Ability of Combinatorial Coverage Metrics to Anticipate Classification Error
Feb 28, 2023



Machine learning models are increasingly used in practice. However, many machine learning methods are sensitive to test or operational data that is dissimilar to training data. Out-of-distribution (OOD) data is known to increase the probability of error and research into metrics that identify what dissimilarities in data affect model performance is on-going. Recently, combinatorial coverage metrics have been explored in the literature as an alternative to distribution-based metrics. Results show that coverage metrics can correlate with classification error. However, other results show that the utility of coverage metrics is highly dataset-dependent. In this paper, we show that this dataset-dependence can be alleviated with metric learning, a machine learning technique for learning latent spaces where data from different classes is further apart. In a study of 6 open-source datasets, we find that metric learning increased the difference between set-difference coverage metrics (SDCCMs) calculated on correctly and incorrectly classified data, thereby demonstrating that metric learning improves the ability of SDCCMs to anticipate classification error. Paired t-tests validate the statistical significance of our findings. Overall, we conclude that metric learning improves the ability of coverage metrics to anticipate classifier error and identify when OOD data is likely to degrade model performance.
Active Learning with Combinatorial Coverage
Feb 28, 2023Active learning is a practical field of machine learning that automates the process of selecting which data to label. Current methods are effective in reducing the burden of data labeling but are heavily model-reliant. This has led to the inability of sampled data to be transferred to new models as well as issues with sampling bias. Both issues are of crucial concern in machine learning deployment. We propose active learning methods utilizing combinatorial coverage to overcome these issues. The proposed methods are data-centric, as opposed to model-centric, and through our experiments we show that the inclusion of coverage in active learning leads to sampling data that tends to be the best in transferring to better performing models and has a competitive sampling bias compared to benchmark methods.
Rationalization for Explainable NLP: A Survey
Jan 21, 2023



Recent advances in deep learning have improved the performance of many Natural Language Processing (NLP) tasks such as translation, question-answering, and text classification. However, this improvement comes at the expense of model explainability. Black-box models make it difficult to understand the internals of a system and the process it takes to arrive at an output. Numerical (LIME, Shapley) and visualization (saliency heatmap) explainability techniques are helpful; however, they are insufficient because they require specialized knowledge. These factors led rationalization to emerge as a more accessible explainable technique in NLP. Rationalization justifies a model's output by providing a natural language explanation (rationale). Recent improvements in natural language generation have made rationalization an attractive technique because it is intuitive, human-comprehensible, and accessible to non-technical users. Since rationalization is a relatively new field, it is disorganized. As the first survey, rationalization literature in NLP from 2007-2022 is analyzed. This survey presents available methods, explainable evaluations, code, and datasets used across various NLP tasks that use rationalization. Further, a new subfield in Explainable AI (XAI), namely, Rational AI (RAI), is introduced to advance the current state of rationalization. A discussion on observed insights, challenges, and future directions is provided to point to promising research opportunities.
Systematic Training and Testing for Machine Learning Using Combinatorial Interaction Testing
Jan 28, 2022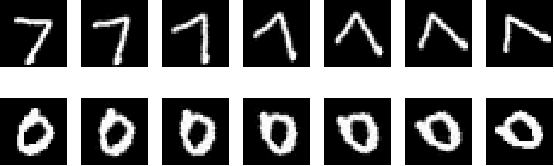
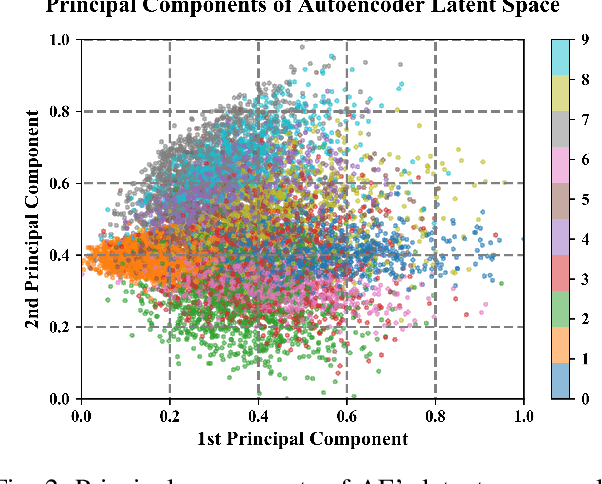
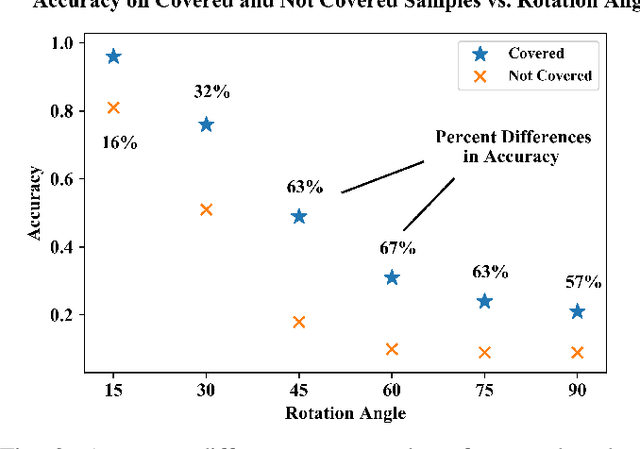

This paper demonstrates the systematic use of combinatorial coverage for selecting and characterizing test and training sets for machine learning models. The presented work adapts combinatorial interaction testing, which has been successfully leveraged in identifying faults in software testing, to characterize data used in machine learning. The MNIST hand-written digits data is used to demonstrate that combinatorial coverage can be used to select test sets that stress machine learning model performance, to select training sets that lead to robust model performance, and to select data for fine-tuning models to new domains. Thus, the results posit combinatorial coverage as a holistic approach to training and testing for machine learning. In contrast to prior work which has focused on the use of coverage in regard to the internal of neural networks, this paper considers coverage over simple features derived from inputs and outputs. Thus, this paper addresses the case where the supplier of test and training sets for machine learning models does not have intellectual property rights to the models themselves. Finally, the paper addresses prior criticism of combinatorial coverage and provides a rebuttal which advocates the use of coverage metrics in machine learning applications.
A Survey on AI Assurance
Nov 15, 2021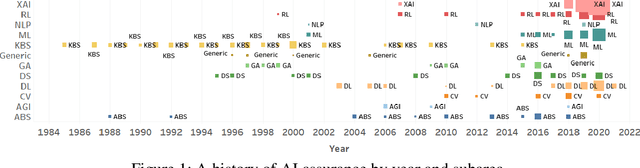
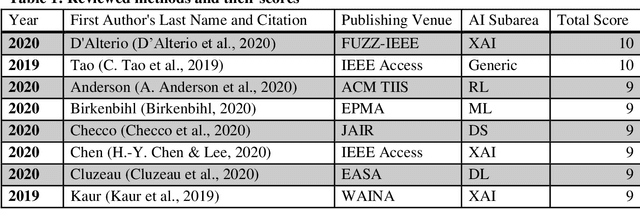
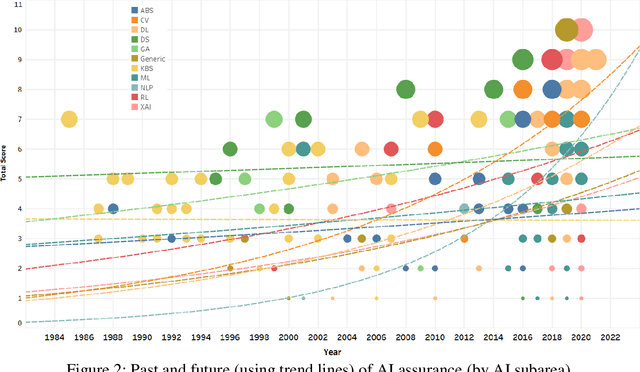
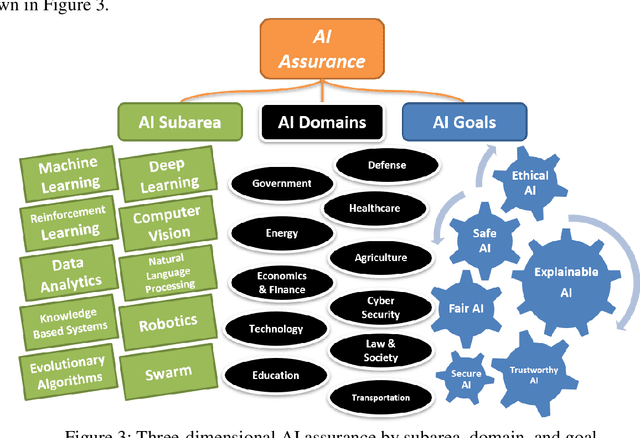
Artificial Intelligence (AI) algorithms are increasingly providing decision making and operational support across multiple domains. AI includes a wide library of algorithms for different problems. One important notion for the adoption of AI algorithms into operational decision process is the concept of assurance. The literature on assurance, unfortunately, conceals its outcomes within a tangled landscape of conflicting approaches, driven by contradicting motivations, assumptions, and intuitions. Accordingly, albeit a rising and novel area, this manuscript provides a systematic review of research works that are relevant to AI assurance, between years 1985 - 2021, and aims to provide a structured alternative to the landscape. A new AI assurance definition is adopted and presented and assurance methods are contrasted and tabulated. Additionally, a ten-metric scoring system is developed and introduced to evaluate and compare existing methods. Lastly, in this manuscript, we provide foundational insights, discussions, future directions, a roadmap, and applicable recommendations for the development and deployment of AI assurance.
* This paper is published at Springer's Journal of Big Data
Test and Evaluation Framework for Multi-Agent Systems of Autonomous Intelligent Agents
Jan 25, 2021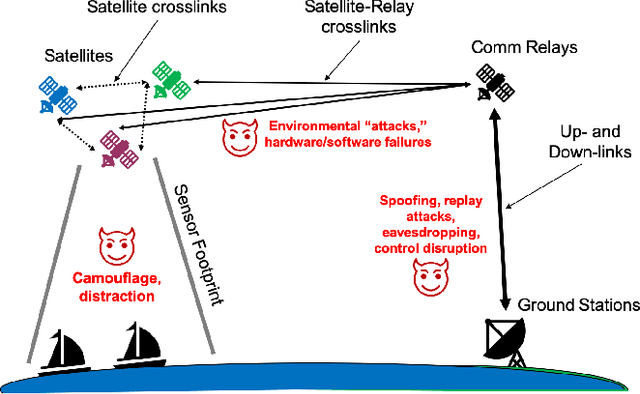
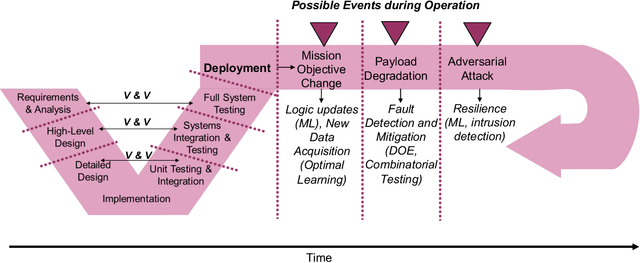
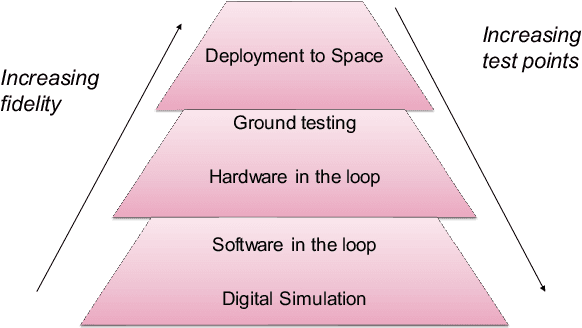

Test and evaluation is a necessary process for ensuring that engineered systems perform as intended under a variety of conditions, both expected and unexpected. In this work, we consider the unique challenges of developing a unifying test and evaluation framework for complex ensembles of cyber-physical systems with embedded artificial intelligence. We propose a framework that incorporates test and evaluation throughout not only the development life cycle, but continues into operation as the system learns and adapts in a noisy, changing, and contended environment. The framework accounts for the challenges of testing the integration of diverse systems at various hierarchical scales of composition while respecting that testing time and resources are limited. A generic use case is provided for illustrative purposes and research directions emerging as a result of exploring the use case via the framework are suggested.
Investigating the Robustness of Artificial Intelligent Algorithms with Mixture Experiments
Oct 10, 2020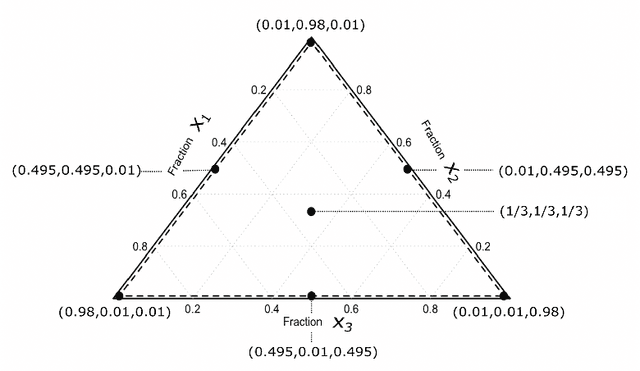
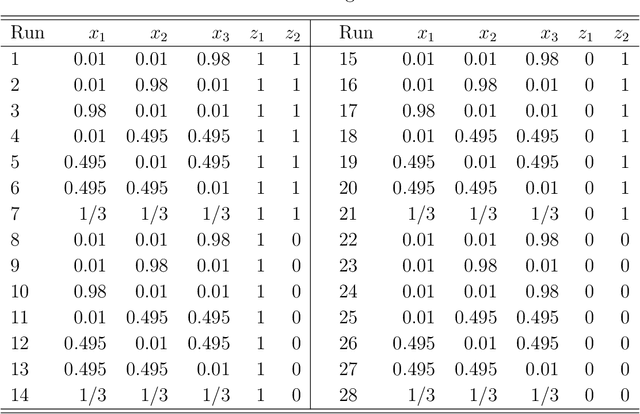
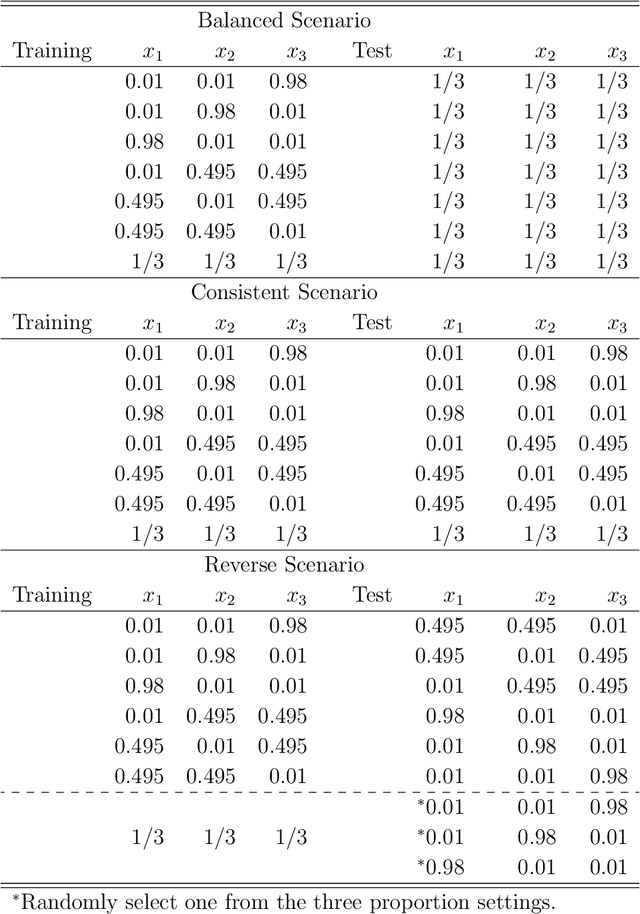
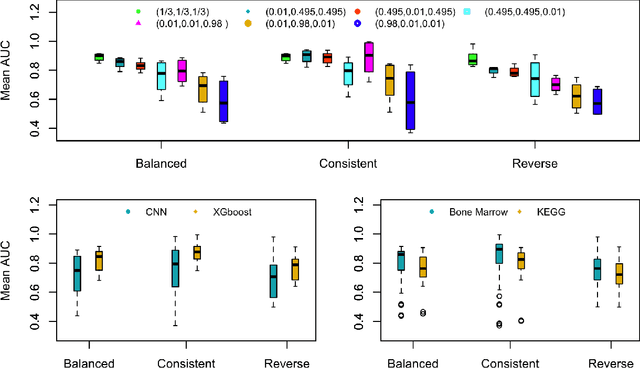
Artificial intelligent (AI) algorithms, such as deep learning and XGboost, are used in numerous applications including computer vision, autonomous driving, and medical diagnostics. The robustness of these AI algorithms is of great interest as inaccurate prediction could result in safety concerns and limit the adoption of AI systems. In this paper, we propose a framework based on design of experiments to systematically investigate the robustness of AI classification algorithms. A robust classification algorithm is expected to have high accuracy and low variability under different application scenarios. The robustness can be affected by a wide range of factors such as the imbalance of class labels in the training dataset, the chosen prediction algorithm, the chosen dataset of the application, and a change of distribution in the training and test datasets. To investigate the robustness of AI classification algorithms, we conduct a comprehensive set of mixture experiments to collect prediction performance results. Then statistical analyses are conducted to understand how various factors affect the robustness of AI classification algorithms. We summarize our findings and provide suggestions to practitioners in AI applications.