 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Systems-Theoretical Formalization of Closed Systems
Nov 16, 2023There is a lack of formalism for some key foundational concepts in systems engineering. One of the most recently acknowledged deficits is the inadequacy of systems engineering practices for engineering intelligent systems. In our previous works, we proposed that closed systems precepts could be used to accomplish a required paradigm shift for the systems engineering of intelligent systems. However, to enable such a shift, formal foundations for closed systems precepts that expand the theory of systems engineering are needed. The concept of closure is a critical concept in the formalism underlying closed systems precepts. In this paper, we provide formal, systems- and information-theoretic definitions of closure to identify and distinguish different types of closed systems. Then, we assert a mathematical framework to evaluate the subjective formation of the boundaries and constraints of such systems. Finally, we argue that engineering an intelligent system can benefit from appropriate closed and open systems paradigms on multiple levels of abstraction of the system. In the main, this framework will provide the necessary fundamentals to aid in systems engineering of intelligent systems.
Active Learning with Combinatorial Coverage
Feb 28, 2023Active learning is a practical field of machine learning that automates the process of selecting which data to label. Current methods are effective in reducing the burden of data labeling but are heavily model-reliant. This has led to the inability of sampled data to be transferred to new models as well as issues with sampling bias. Both issues are of crucial concern in machine learning deployment. We propose active learning methods utilizing combinatorial coverage to overcome these issues. The proposed methods are data-centric, as opposed to model-centric, and through our experiments we show that the inclusion of coverage in active learning leads to sampling data that tends to be the best in transferring to better performing models and has a competitive sampling bias compared to benchmark methods.
Exposing Surveillance Detection Routes via Reinforcement Learning, Attack Graphs, and Cyber Terrain
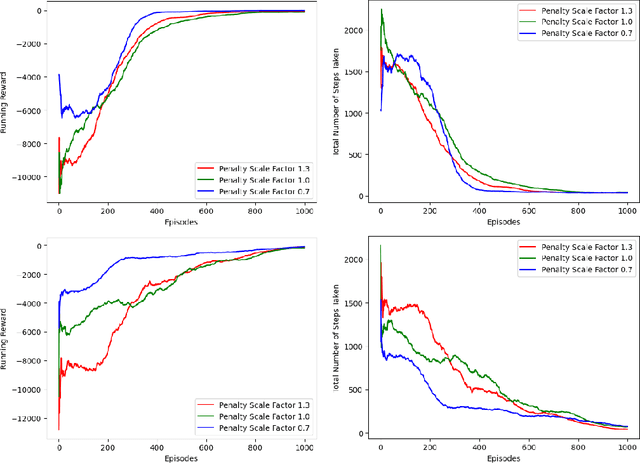
Nov 06, 2022Reinforcement learning (RL) operating on attack graphs leveraging cyber terrain principles are used to develop reward and state associated with determination of surveillance detection routes (SDR). This work extends previous efforts on developing RL methods for path analysis within enterprise networks. This work focuses on building SDR where the routes focus on exploring the network services while trying to evade risk. RL is utilized to support the development of these routes by building a reward mechanism that would help in realization of these paths. The RL algorithm is modified to have a novel warm-up phase which decides in the initial exploration which areas of the network are safe to explore based on the rewards and penalty scale factor.
Core and Periphery as Closed-System Precepts for Engineering General Intelligence
Aug 04, 2022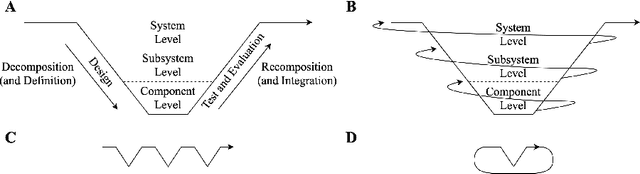
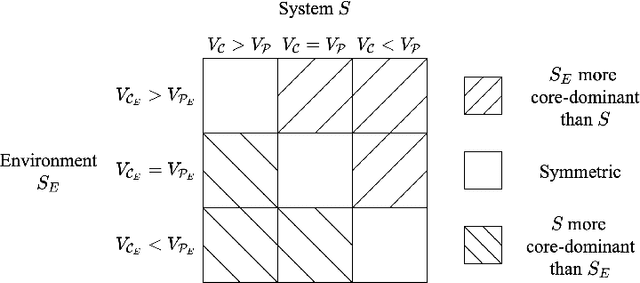
Engineering methods are centered around traditional notions of decomposition and recomposition that rely on partitioning the inputs and outputs of components to allow for component-level properties to hold after their composition. In artificial intelligence (AI), however, systems are often expected to influence their environments, and, by way of their environments, to influence themselves. Thus, it is unclear if an AI system's inputs will be independent of its outputs, and, therefore, if AI systems can be treated as traditional components. This paper posits that engineering general intelligence requires new general systems precepts, termed the core and periphery, and explores their theoretical uses. The new precepts are elaborated using abstract systems theory and the Law of Requisite Variety. By using the presented material, engineers can better understand the general character of regulating the outcomes of AI to achieve stakeholder needs and how the general systems nature of embodiment challenges traditional engineering practice.
Discovering Exfiltration Paths Using Reinforcement Learning with Attack Graphs
Jan 28, 2022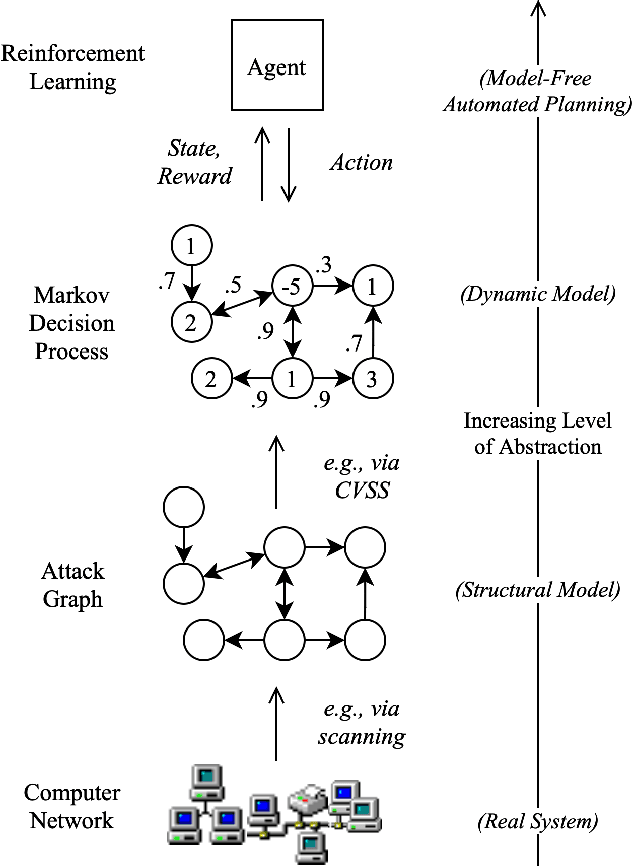
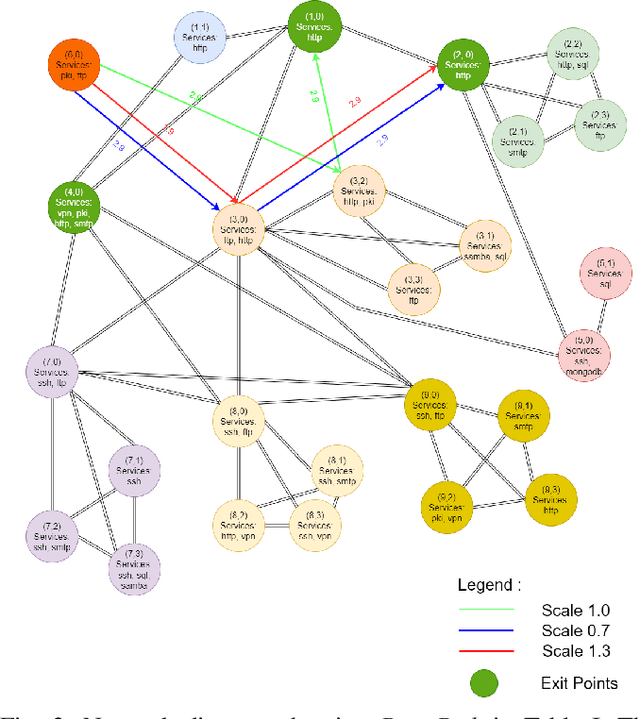
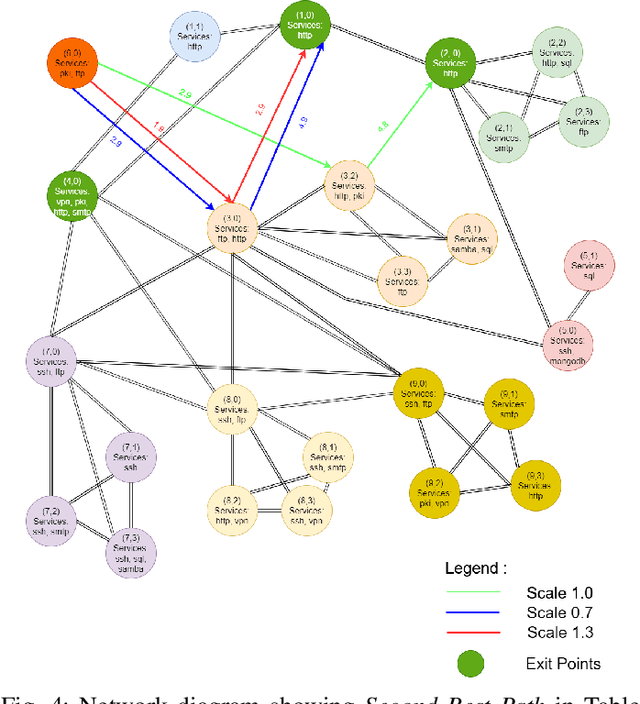
Reinforcement learning (RL), in conjunction with attack graphs and cyber terrain, are used to develop reward and state associated with determination of optimal paths for exfiltration of data in enterprise networks. This work builds on previous crown jewels (CJ) identification that focused on the target goal of computing optimal paths that adversaries may traverse toward compromising CJs or hosts within their proximity. This work inverts the previous CJ approach based on the assumption that data has been stolen and now must be quietly exfiltrated from the network. RL is utilized to support the development of a reward function based on the identification of those paths where adversaries desire reduced detection. Results demonstrate promising performance for a sizable network environment.
Real Time Strategy Language
Jan 21, 2014Real Time Strategy (RTS) games provide complex domain to test the latest artificial intelligence (AI) research. In much of the literature, AI systems have been limited to playing one game. Although, this specialization has resulted in stronger AI gaming systems it does not address the key concerns of AI researcher. AI researchers seek the development of AI agents that can autonomously interpret learn, and apply new knowledge. To achieve human level performance, current AI systems rely on game specific knowledge of an expert. The paper presents the full RTS language in hopes of shifting the current research focus to the development of general RTS agents. General RTS agents are AI gaming systems that can play any RTS games, defined in the RTS language. This prevents game specific knowledge from being hard coded into the system, thereby facilitating research that addresses the fundamental concerns of artificial intelligence.