 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSystematic Training and Testing for Machine Learning Using Combinatorial Interaction Testing
Paper and Code
Jan 28, 2022
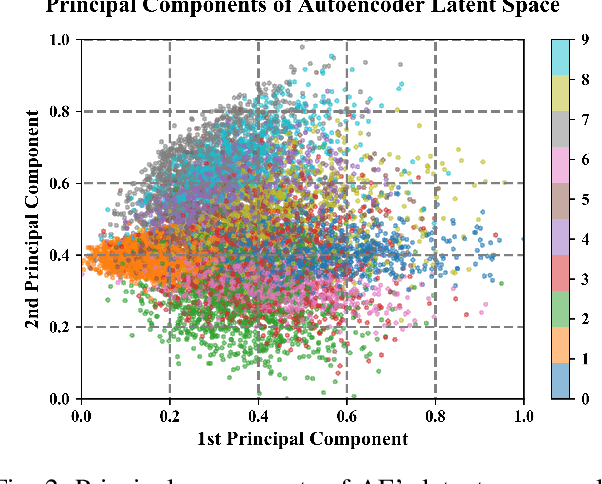
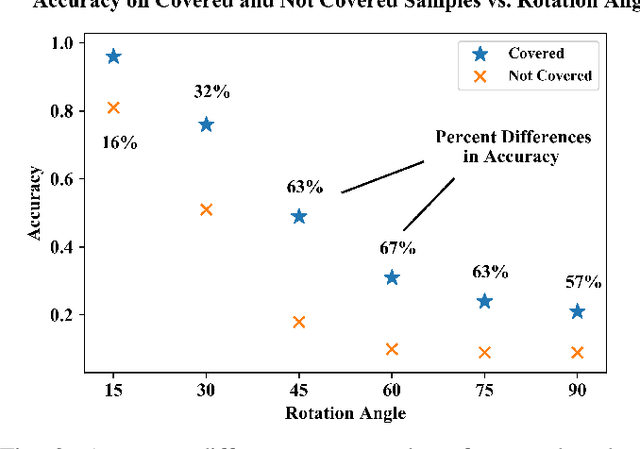

This paper demonstrates the systematic use of combinatorial coverage for selecting and characterizing test and training sets for machine learning models. The presented work adapts combinatorial interaction testing, which has been successfully leveraged in identifying faults in software testing, to characterize data used in machine learning. The MNIST hand-written digits data is used to demonstrate that combinatorial coverage can be used to select test sets that stress machine learning model performance, to select training sets that lead to robust model performance, and to select data for fine-tuning models to new domains. Thus, the results posit combinatorial coverage as a holistic approach to training and testing for machine learning. In contrast to prior work which has focused on the use of coverage in regard to the internal of neural networks, this paper considers coverage over simple features derived from inputs and outputs. Thus, this paper addresses the case where the supplier of test and training sets for machine learning models does not have intellectual property rights to the models themselves. Finally, the paper addresses prior criticism of combinatorial coverage and provides a rebuttal which advocates the use of coverage metrics in machine learning applications.