 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating the Robustness of Artificial Intelligent Algorithms with Mixture Experiments
Paper and Code
Oct 10, 2020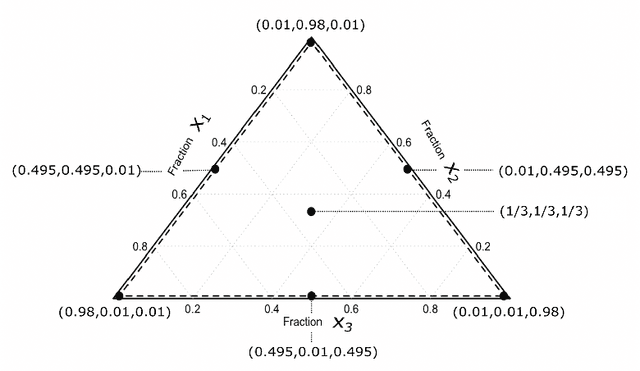
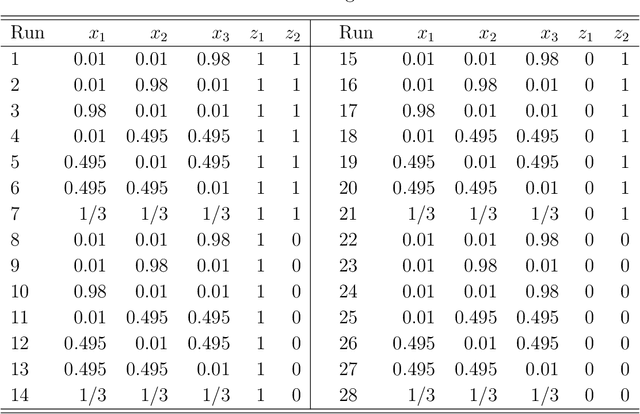
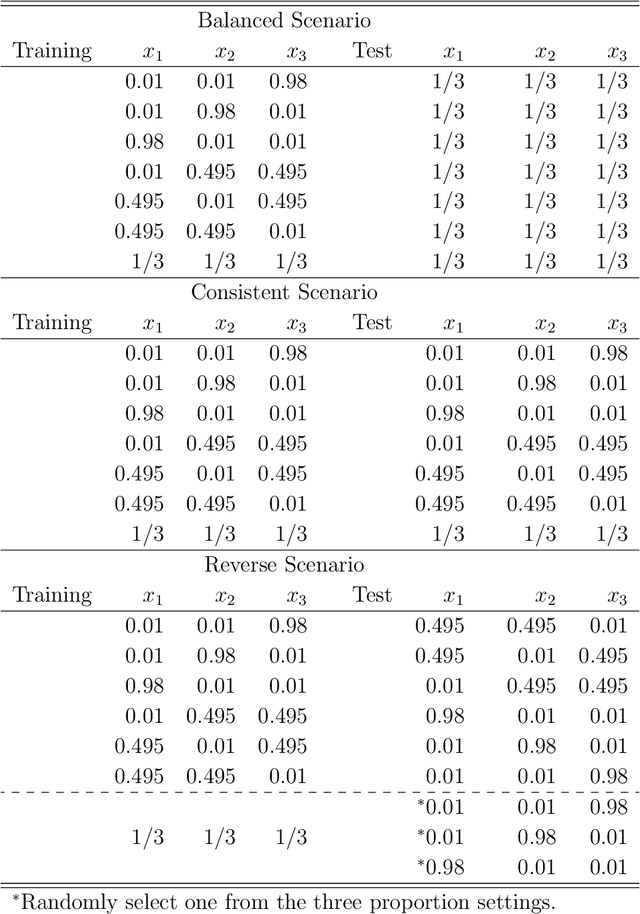
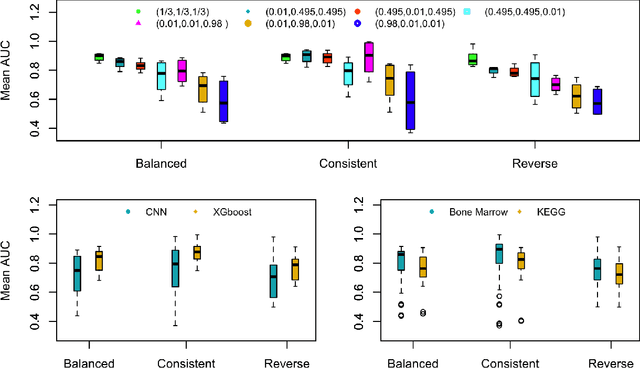
Artificial intelligent (AI) algorithms, such as deep learning and XGboost, are used in numerous applications including computer vision, autonomous driving, and medical diagnostics. The robustness of these AI algorithms is of great interest as inaccurate prediction could result in safety concerns and limit the adoption of AI systems. In this paper, we propose a framework based on design of experiments to systematically investigate the robustness of AI classification algorithms. A robust classification algorithm is expected to have high accuracy and low variability under different application scenarios. The robustness can be affected by a wide range of factors such as the imbalance of class labels in the training dataset, the chosen prediction algorithm, the chosen dataset of the application, and a change of distribution in the training and test datasets. To investigate the robustness of AI classification algorithms, we conduct a comprehensive set of mixture experiments to collect prediction performance results. Then statistical analyses are conducted to understand how various factors affect the robustness of AI classification algorithms. We summarize our findings and provide suggestions to practitioners in AI applications.