 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Dataset Selection for High-Quality Data Sharing
Dec 24, 2025



The success of modern machine learning hinges on access to high-quality training data. In many real-world scenarios, such as acquiring data from public repositories or sharing across institutions, data is naturally organized into discrete datasets that vary in relevance, quality, and utility. Selecting which repositories or institutions to search for useful datasets, and which datasets to incorporate into model training are therefore critical decisions, yet most existing methods select individual samples and treat all data as equally relevant, ignoring differences between datasets and their sources. In this work, we formalize the task of dataset selection: selecting entire datasets from a large, heterogeneous pool to improve downstream performance under resource constraints. We propose Dataset Selection via Hierarchies (DaSH), a dataset selection method that models utility at both dataset and group (e.g., collections, institutions) levels, enabling efficient generalization from limited observations. Across two public benchmarks (Digit-Five and DomainNet), DaSH outperforms state-of-the-art data selection baselines by up to 26.2% in accuracy, while requiring significantly fewer exploration steps. Ablations show DaSH is robust to low-resource settings and lack of relevant datasets, making it suitable for scalable and adaptive dataset selection in practical multi-source learning workflows.
FAIR: Facilitating Artificial Intelligence Resilience in Manufacturing Industrial Internet
Mar 03, 2025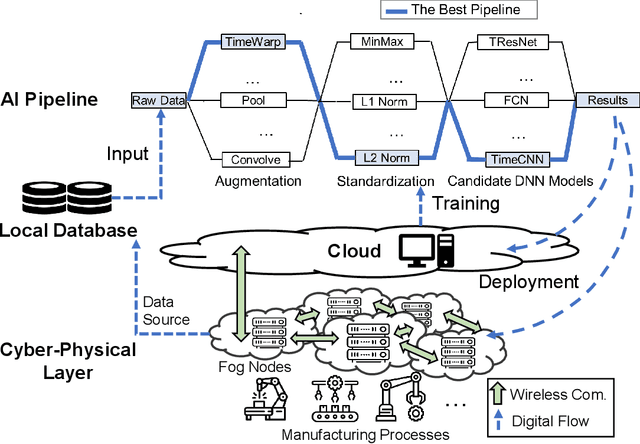
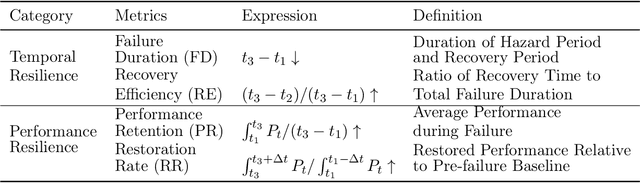
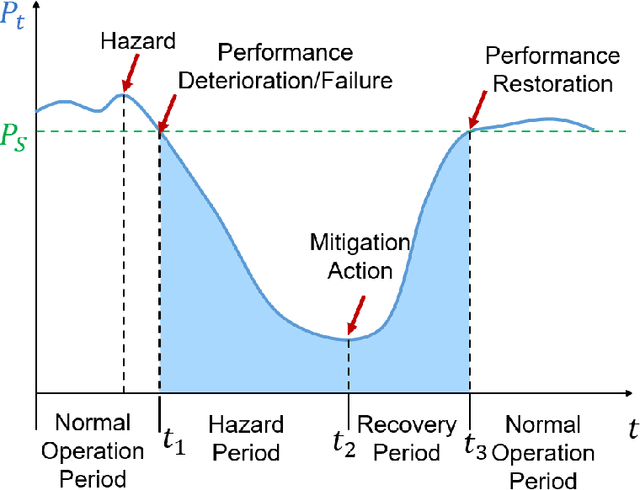
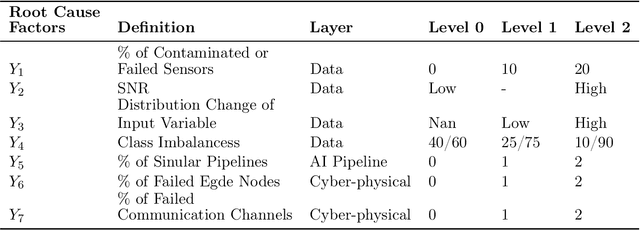
Artificial intelligence (AI) systems have been increasingly adopted in the Manufacturing Industrial Internet (MII). Investigating and enabling the AI resilience is very important to alleviate profound impact of AI system failures in manufacturing and Industrial Internet of Things (IIoT) operations, leading to critical decision making. However, there is a wide knowledge gap in defining the resilience of AI systems and analyzing potential root causes and corresponding mitigation strategies. In this work, we propose a novel framework for investigating the resilience of AI performance over time under hazard factors in data quality, AI pipelines, and the cyber-physical layer. The proposed method can facilitate effective diagnosis and mitigation strategies to recover AI performance based on a multimodal multi-head self latent attention model. The merits of the proposed method are elaborated using an MII testbed of connected Aerosol Jet Printing (AJP) machines, fog nodes, and Cloud with inference tasks via AI pipelines.
Ensemble Active Learning by Contextual Bandits for AI Incubation in Manufacturing
Oct 11, 2023



It is challenging but important to save annotation efforts in streaming data acquisition to maintain data quality for supervised learning base learners. We propose an ensemble active learning method to actively acquire samples for annotation by contextual bandits, which is will enforce the exploration-exploitation balance and leading to improved AI modeling performance.
Bayesian Sparse Regression for Mixed Multi-Responses with Application to Runtime Metrics Prediction in Fog Manufacturing
Oct 11, 2022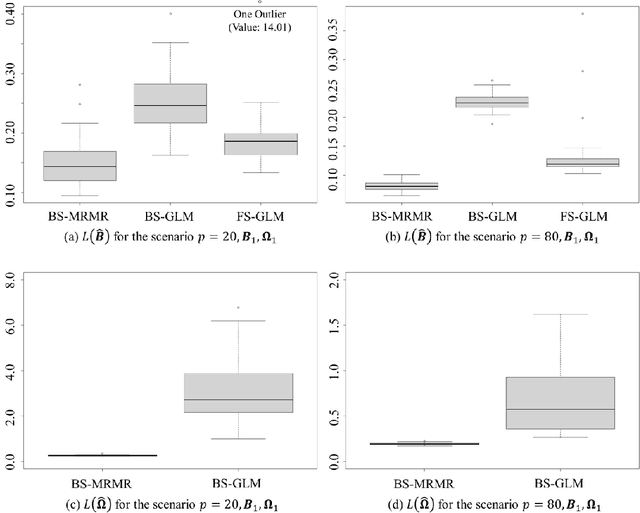
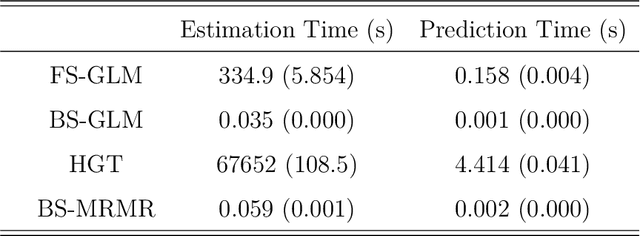
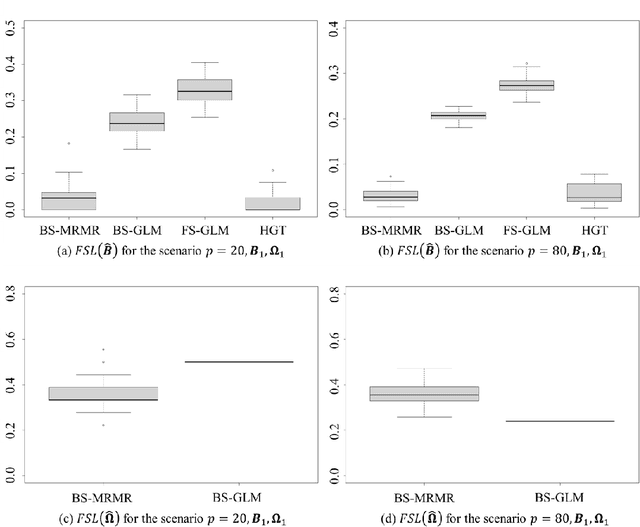

Fog manufacturing can greatly enhance traditional manufacturing systems through distributed Fog computation units, which are governed by predictive computational workload offloading methods under different Industrial Internet architectures. It is known that the predictive offloading methods highly depend on accurate prediction and uncertainty quantification of runtime performance metrics, containing multivariate mixed-type responses (i.e., continuous, counting, binary). In this work, we propose a Bayesian sparse regression for multivariate mixed responses to enhance the prediction of runtime performance metrics and to enable the statistical inferences. The proposed method considers both group and individual variable selection to jointly model the mixed types of runtime performance metrics. The conditional dependency among multiple responses is described by a graphical model using the precision matrix, where a spike-and-slab prior is used to enable the sparse estimation of the graph. The proposed method not only achieves accurate prediction, but also makes the predictive model more interpretable with statistical inferences on model parameters and prediction in the Fog manufacturing. A simulation study and a real case example in a Fog manufacturing are conducted to demonstrate the merits of the proposed model.
Learning to Refit for Convex Learning Problems
Nov 24, 2021


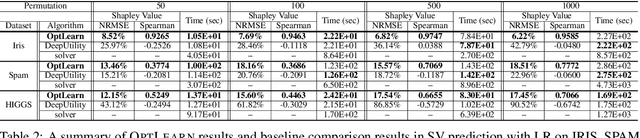
Machine learning (ML) models need to be frequently retrained on changing datasets in a wide variety of application scenarios, including data valuation and uncertainty quantification. To efficiently retrain the model, linear approximation methods such as influence function have been proposed to estimate the impact of data changes on model parameters. However, these methods become inaccurate for large dataset changes. In this work, we focus on convex learning problems and propose a general framework to learn to estimate optimized model parameters for different training sets using neural networks. We propose to enforce the predicted model parameters to obey optimality conditions and maintain utility through regularization techniques, which significantly improve generalization. Moreover, we rigorously characterize the expressive power of neural networks to approximate the optimizer of convex problems. Empirical results demonstrate the advantage of the proposed method in accurate and efficient model parameter estimation compared to the state-of-the-art.
Adaptively Weighted Top-N Recommendation for Organ Matching
Jul 23, 2021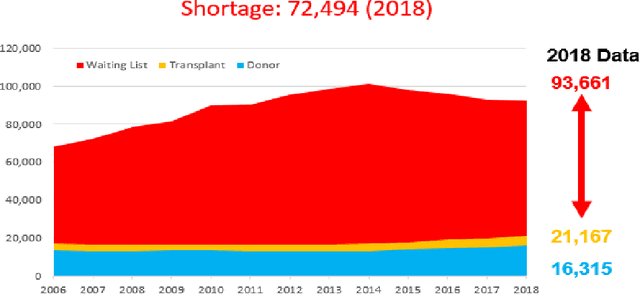



Reducing the shortage of organ donations to meet the demands of patients on the waiting list has being a major challenge in organ transplantation. Because of the shortage, organ matching decision is the most critical decision to assign the limited viable organs to the most suitable patients. Currently, organ matching decisions were only made by matching scores calculated via scoring models, which are built by the first principles. However, these models may disagree with the actual post-transplantation matching performance (e.g., patient's post-transplant quality of life (QoL) or graft failure measurements). In this paper, we formulate the organ matching decision-making as a top-N recommendation problem and propose an Adaptively Weighted Top-N Recommendation (AWTR) method. AWTR improves performance of the current scoring models by using limited actual matching performance in historical data set as well as the collected covariates from organ donors and patients. AWTR sacrifices the overall recommendation accuracy by emphasizing the recommendation and ranking accuracy for top-N matched patients. The proposed method is validated in a simulation study, where KAS [60] is used to simulate the organ-patient recommendation response. The results show that our proposed method outperforms seven state-of-the-art top-N recommendation benchmark methods.