 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLVM-GP: Uncertainty-Aware PDE Solver via coupling latent variable model and Gaussian process
Jul 30, 2025We propose a novel probabilistic framework, termed LVM-GP, for uncertainty quantification in solving forward and inverse partial differential equations (PDEs) with noisy data. The core idea is to construct a stochastic mapping from the input to a high-dimensional latent representation, enabling uncertainty-aware prediction of the solution. Specifically, the architecture consists of a confidence-aware encoder and a probabilistic decoder. The encoder implements a high-dimensional latent variable model based on a Gaussian process (LVM-GP), where the latent representation is constructed by interpolating between a learnable deterministic feature and a Gaussian process prior, with the interpolation strength adaptively controlled by a confidence function learned from data. The decoder defines a conditional Gaussian distribution over the solution field, where the mean is predicted by a neural operator applied to the latent representation, allowing the model to learn flexible function-to-function mapping. Moreover, physical laws are enforced as soft constraints in the loss function to ensure consistency with the underlying PDE structure. Compared to existing approaches such as Bayesian physics-informed neural networks (B-PINNs) and deep ensembles, the proposed framework can efficiently capture functional dependencies via merging a latent Gaussian process and neural operator, resulting in competitive predictive accuracy and robust uncertainty quantification. Numerical experiments demonstrate the effectiveness and reliability of the method.
ESGReveal: An LLM-based approach for extracting structured data from ESG reports
Dec 25, 2023ESGReveal is an innovative method proposed for efficiently extracting and analyzing Environmental, Social, and Governance (ESG) data from corporate reports, catering to the critical need for reliable ESG information retrieval. This approach utilizes Large Language Models (LLM) enhanced with Retrieval Augmented Generation (RAG) techniques. The ESGReveal system includes an ESG metadata module for targeted queries, a preprocessing module for assembling databases, and an LLM agent for data extraction. Its efficacy was appraised using ESG reports from 166 companies across various sectors listed on the Hong Kong Stock Exchange in 2022, ensuring comprehensive industry and market capitalization representation. Utilizing ESGReveal unearthed significant insights into ESG reporting with GPT-4, demonstrating an accuracy of 76.9% in data extraction and 83.7% in disclosure analysis, which is an improvement over baseline models. This highlights the framework's capacity to refine ESG data analysis precision. Moreover, it revealed a demand for reinforced ESG disclosures, with environmental and social data disclosures standing at 69.5% and 57.2%, respectively, suggesting a pursuit for more corporate transparency. While current iterations of ESGReveal do not process pictorial information, a functionality intended for future enhancement, the study calls for continued research to further develop and compare the analytical capabilities of various LLMs. In summary, ESGReveal is a stride forward in ESG data processing, offering stakeholders a sophisticated tool to better evaluate and advance corporate sustainability efforts. Its evolution is promising in promoting transparency in corporate reporting and aligning with broader sustainable development aims.
AutoPCF: Efficient Product Carbon Footprint Accounting with Large Language Models
Aug 11, 2023The product carbon footprint (PCF) is crucial for decarbonizing the supply chain, as it measures the direct and indirect greenhouse gas emissions caused by all activities during the product's life cycle. However, PCF accounting often requires expert knowledge and significant time to construct life cycle models. In this study, we test and compare the emergent ability of five large language models (LLMs) in modeling the 'cradle-to-gate' life cycles of products and generating the inventory data of inputs and outputs, revealing their limitations as a generalized PCF knowledge database. By utilizing LLMs, we propose an automatic AI-driven PCF accounting framework, called AutoPCF, which also applies deep learning algorithms to automatically match calculation parameters, and ultimately calculate the PCF. The results of estimating the carbon footprint for three case products using the AutoPCF framework demonstrate its potential in achieving automatic modeling and estimation of PCF with a large reduction in modeling time from days to minutes.
IB-UQ: Information bottleneck based uncertainty quantification for neural function regression and neural operator learning
Feb 07, 2023In this paper, a novel framework is established for uncertainty quantification via information bottleneck (IB-UQ) for scientific machine learning tasks, including deep neural network (DNN) regression and neural operator learning (DeepONet). Specifically, we first employ the General Incompressible-Flow Networks (GIN) model to learn a "wide" distribution fromnoisy observation data. Then, following the information bottleneck objective, we learn a stochastic map from input to some latent representation that can be used to predict the output. A tractable variational bound on the IB objective is constructed with a normalizing flow reparameterization. Hence, we can optimize the objective using the stochastic gradient descent method. IB-UQ can provide both mean and variance in the label prediction by explicitly modeling the representation variables. Compared to most DNN regression methods and the deterministic DeepONet, the proposed model can be trained on noisy data and provide accurate predictions with reliable uncertainty estimates on unseen noisy data. We demonstrate the capability of the proposed IB-UQ framework via several representative examples, including discontinuous function regression, real-world dataset regression and learning nonlinear operators for diffusion-reaction partial differential equation.
RESUS: Warm-Up Cold Users via Meta-Learning Residual User Preferences in CTR Prediction
Oct 28, 2022Click-Through Rate (CTR) prediction on cold users is a challenging task in recommender systems. Recent researches have resorted to meta-learning to tackle the cold-user challenge, which either perform few-shot user representation learning or adopt optimization-based meta-learning. However, existing methods suffer from information loss or inefficient optimization process, and they fail to explicitly model global user preference knowledge which is crucial to complement the sparse and insufficient preference information of cold users. In this paper, we propose a novel and efficient approach named RESUS, which decouples the learning of global preference knowledge contributed by collective users from the learning of residual preferences for individual users. Specifically, we employ a shared predictor to infer basis user preferences, which acquires global preference knowledge from the interactions of different users. Meanwhile, we develop two efficient algorithms based on the nearest neighbor and ridge regression predictors, which infer residual user preferences via learning quickly from a few user-specific interactions. Extensive experiments on three public datasets demonstrate that our RESUS approach is efficient and effective in improving CTR prediction accuracy on cold users, compared with various state-of-the-art methods.
A Novel Fast Exact Subproblem Solver for Stochastic Quasi-Newton Cubic Regularized Optimization
Apr 19, 2022
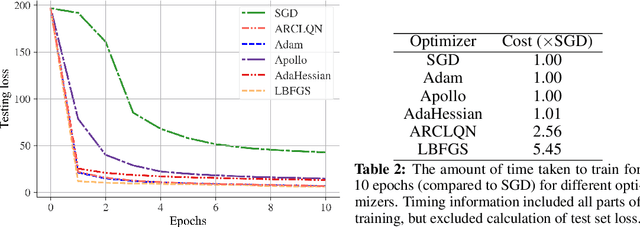

In this work we describe an Adaptive Regularization using Cubics (ARC) method for large-scale nonconvex unconstrained optimization using Limited-memory Quasi-Newton (LQN) matrices. ARC methods are a relatively new family of optimization strategies that utilize a cubic-regularization (CR) term in place of trust-regions and line-searches. LQN methods offer a large-scale alternative to using explicit second-order information by taking identical inputs to those used by popular first-order methods such as stochastic gradient descent (SGD). Solving the CR subproblem exactly requires Newton's method, yet using properties of the internal structure of LQN matrices, we are able to find exact solutions to the CR subproblem in a matrix-free manner, providing large speedups and scaling into modern size requirements. Additionally, we expand upon previous ARC work and explicitly incorporate first-order updates into our algorithm. We provide experimental results when the SR1 update is used, which show substantial speed-ups and competitive performance compared to Adam and other second order optimizers on deep neural networks (DNNs). We find that our new approach, ARCLQN, compares to modern optimizers with minimal tuning, a common pain-point for second order methods.