 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Staleness Aware Incremental Learning for CTR Prediction
Apr 29, 2025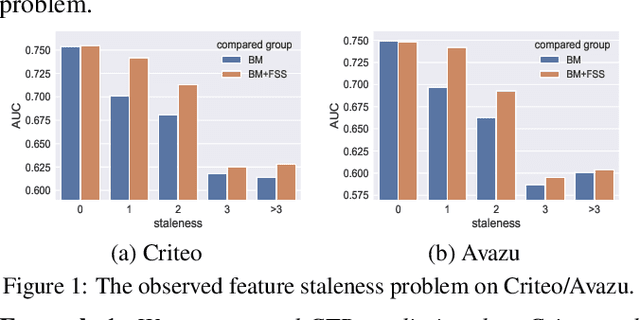
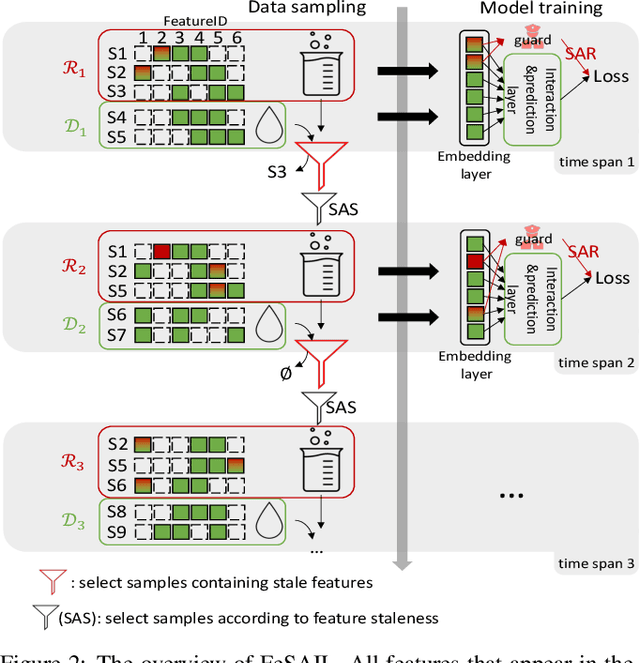
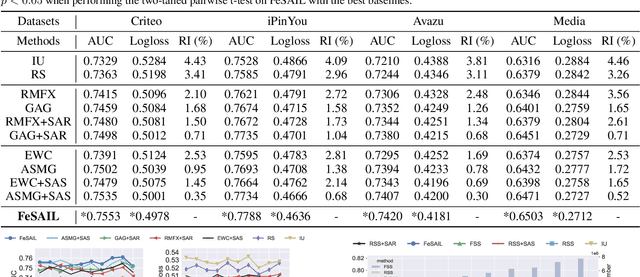
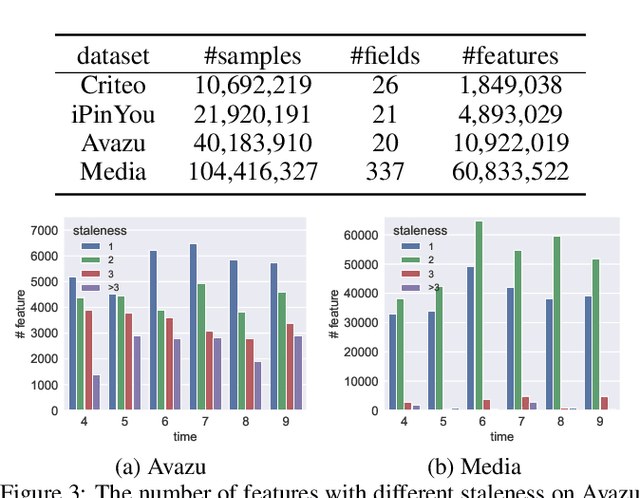
Click-through Rate (CTR) prediction in real-world recommender systems often deals with billions of user interactions every day. To improve the training efficiency, it is common to update the CTR prediction model incrementally using the new incremental data and a subset of historical data. However, the feature embeddings of a CTR prediction model often get stale when the corresponding features do not appear in current incremental data. In the next period, the model would have a performance degradation on samples containing stale features, which we call the feature staleness problem. To mitigate this problem, we propose a Feature Staleness Aware Incremental Learning method for CTR prediction (FeSAIL) which adaptively replays samples containing stale features. We first introduce a staleness aware sampling algorithm (SAS) to sample a fixed number of stale samples with high sampling efficiency. We then introduce a staleness aware regularization mechanism (SAR) for a fine-grained control of the feature embedding updating. We instantiate FeSAIL with a general deep learning-based CTR prediction model and the experimental results demonstrate FeSAIL outperforms various state-of-the-art methods on four benchmark datasets.
Directed Acyclic Graph Factorization Machines for CTR Prediction via Knowledge Distillation
Nov 21, 2022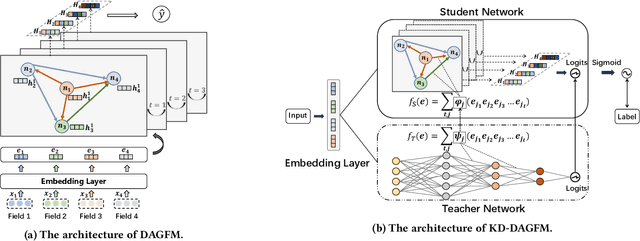



With the growth of high-dimensional sparse data in web-scale recommender systems, the computational cost to learn high-order feature interaction in CTR prediction task largely increases, which limits the use of high-order interaction models in real industrial applications. Some recent knowledge distillation based methods transfer knowledge from complex teacher models to shallow student models for accelerating the online model inference. However, they suffer from the degradation of model accuracy in knowledge distillation process. It is challenging to balance the efficiency and effectiveness of the shallow student models. To address this problem, we propose a Directed Acyclic Graph Factorization Machine (KD-DAGFM) to learn the high-order feature interactions from existing complex interaction models for CTR prediction via Knowledge Distillation. The proposed lightweight student model DAGFM can learn arbitrary explicit feature interactions from teacher networks, which achieves approximately lossless performance and is proved by a dynamic programming algorithm. Besides, an improved general model KD-DAGFM+ is shown to be effective in distilling both explicit and implicit feature interactions from any complex teacher model. Extensive experiments are conducted on four real-world datasets, including a large-scale industrial dataset from WeChat platform with billions of feature dimensions. KD-DAGFM achieves the best performance with less than 21.5% FLOPs of the state-of-the-art method on both online and offline experiments, showing the superiority of DAGFM to deal with the industrial scale data in CTR prediction task. Our implementation code is available at: https://github.com/RUCAIBox/DAGFM.
RESUS: Warm-Up Cold Users via Meta-Learning Residual User Preferences in CTR Prediction
Oct 28, 2022Click-Through Rate (CTR) prediction on cold users is a challenging task in recommender systems. Recent researches have resorted to meta-learning to tackle the cold-user challenge, which either perform few-shot user representation learning or adopt optimization-based meta-learning. However, existing methods suffer from information loss or inefficient optimization process, and they fail to explicitly model global user preference knowledge which is crucial to complement the sparse and insufficient preference information of cold users. In this paper, we propose a novel and efficient approach named RESUS, which decouples the learning of global preference knowledge contributed by collective users from the learning of residual preferences for individual users. Specifically, we employ a shared predictor to infer basis user preferences, which acquires global preference knowledge from the interactions of different users. Meanwhile, we develop two efficient algorithms based on the nearest neighbor and ridge regression predictors, which infer residual user preferences via learning quickly from a few user-specific interactions. Extensive experiments on three public datasets demonstrate that our RESUS approach is efficient and effective in improving CTR prediction accuracy on cold users, compared with various state-of-the-art methods.