 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecGPT: A Foundation Model for Sequential Recommendation
Jun 06, 2025This work addresses a fundamental barrier in recommender systems: the inability to generalize across domains without extensive retraining. Traditional ID-based approaches fail entirely in cold-start and cross-domain scenarios where new users or items lack sufficient interaction history. Inspired by foundation models' cross-domain success, we develop a foundation model for sequential recommendation that achieves genuine zero-shot generalization capabilities. Our approach fundamentally departs from existing ID-based methods by deriving item representations exclusively from textual features. This enables immediate embedding of any new item without model retraining. We introduce unified item tokenization with Finite Scalar Quantization that transforms heterogeneous textual descriptions into standardized discrete tokens. This eliminates domain barriers that plague existing systems. Additionally, the framework features hybrid bidirectional-causal attention that captures both intra-item token coherence and inter-item sequential dependencies. An efficient catalog-aware beam search decoder enables real-time token-to-item mapping. Unlike conventional approaches confined to their training domains, RecGPT naturally bridges diverse recommendation contexts through its domain-invariant tokenization mechanism. Comprehensive evaluations across six datasets and industrial scenarios demonstrate consistent performance advantages.
Feature Staleness Aware Incremental Learning for CTR Prediction
Apr 29, 2025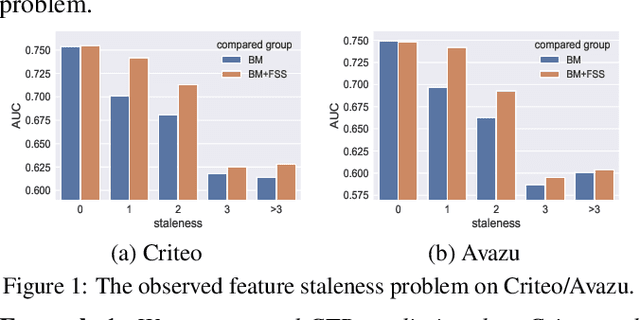
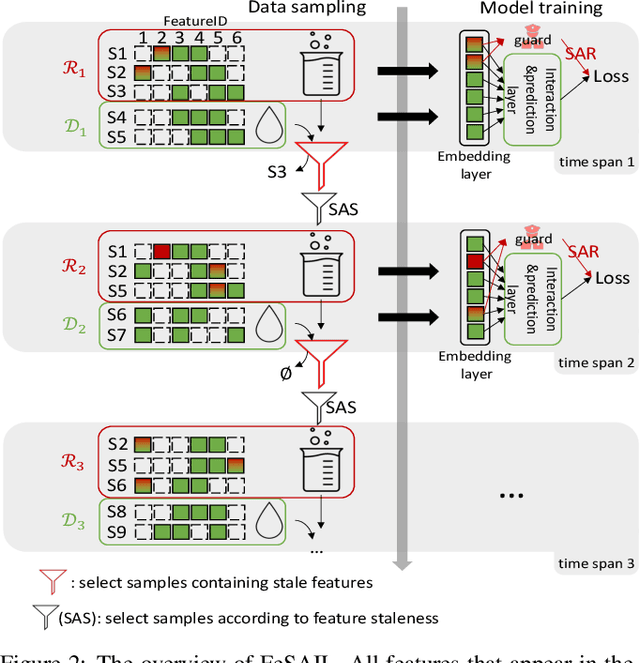
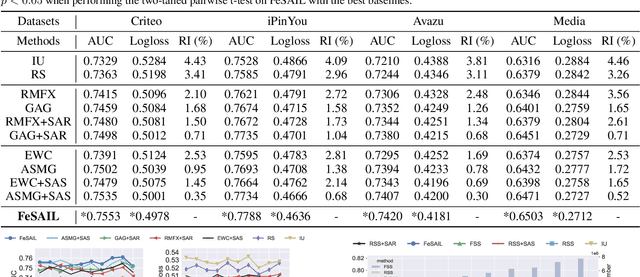
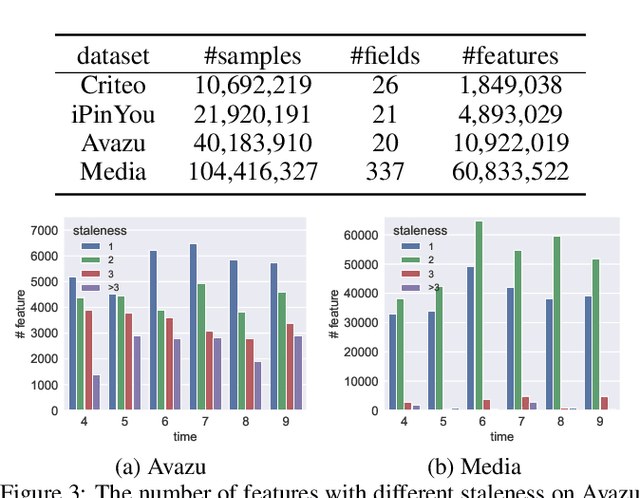
Click-through Rate (CTR) prediction in real-world recommender systems often deals with billions of user interactions every day. To improve the training efficiency, it is common to update the CTR prediction model incrementally using the new incremental data and a subset of historical data. However, the feature embeddings of a CTR prediction model often get stale when the corresponding features do not appear in current incremental data. In the next period, the model would have a performance degradation on samples containing stale features, which we call the feature staleness problem. To mitigate this problem, we propose a Feature Staleness Aware Incremental Learning method for CTR prediction (FeSAIL) which adaptively replays samples containing stale features. We first introduce a staleness aware sampling algorithm (SAS) to sample a fixed number of stale samples with high sampling efficiency. We then introduce a staleness aware regularization mechanism (SAR) for a fine-grained control of the feature embedding updating. We instantiate FeSAIL with a general deep learning-based CTR prediction model and the experimental results demonstrate FeSAIL outperforms various state-of-the-art methods on four benchmark datasets.
RecLM: Recommendation Instruction Tuning
Dec 26, 2024



Modern recommender systems aim to deeply understand users' complex preferences through their past interactions. While deep collaborative filtering approaches using Graph Neural Networks (GNNs) excel at capturing user-item relationships, their effectiveness is limited when handling sparse data or zero-shot scenarios, primarily due to constraints in ID-based embedding functions. To address these challenges, we propose a model-agnostic recommendation instruction-tuning paradigm that seamlessly integrates large language models with collaborative filtering. Our proposed Recommendation Language Model (RecLM) enhances the capture of user preference diversity through a carefully designed reinforcement learning reward function that facilitates self-augmentation of language models. Comprehensive evaluations demonstrate significant advantages of our approach across various settings, and its plug-and-play compatibility with state-of-the-art recommender systems results in notable performance enhancements.
DiffMM: Multi-Modal Diffusion Model for Recommendation
Jun 17, 2024



The rise of online multi-modal sharing platforms like TikTok and YouTube has enabled personalized recommender systems to incorporate multiple modalities (such as visual, textual, and acoustic) into user representations. However, addressing the challenge of data sparsity in these systems remains a key issue. To address this limitation, recent research has introduced self-supervised learning techniques to enhance recommender systems. However, these methods often rely on simplistic random augmentation or intuitive cross-view information, which can introduce irrelevant noise and fail to accurately align the multi-modal context with user-item interaction modeling. To fill this research gap, we propose a novel multi-modal graph diffusion model for recommendation called DiffMM. Our framework integrates a modality-aware graph diffusion model with a cross-modal contrastive learning paradigm to improve modality-aware user representation learning. This integration facilitates better alignment between multi-modal feature information and collaborative relation modeling. Our approach leverages diffusion models' generative capabilities to automatically generate a user-item graph that is aware of different modalities, facilitating the incorporation of useful multi-modal knowledge in modeling user-item interactions. We conduct extensive experiments on three public datasets, consistently demonstrating the superiority of our DiffMM over various competitive baselines. For open-sourced model implementation details, you can access the source codes of our proposed framework at: https://github.com/HKUDS/DiffMM .
Graph Pre-training and Prompt Learning for Recommendation
Nov 28, 2023



GNN-based recommenders have excelled in modeling intricate user-item interactions through multi-hop message passing. However, existing methods often overlook the dynamic nature of evolving user-item interactions, which impedes the adaption to changing user preferences and distribution shifts in newly arriving data. Thus, their scalability and performances in real-world dynamic environments are limited. In this study, we propose GraphPL, a framework that incorporates parameter-efficient and dynamic graph pre-training with prompt learning. This novel combination empowers GNNs to effectively capture both long-term user preferences and short-term behavior dynamics, enabling the delivery of accurate and timely recommendations. Our GraphPL framework addresses the challenge of evolving user preferences by seamlessly integrating a temporal prompt mechanism and a graph-structural prompt learning mechanism into the pre-trained GNN model. The temporal prompt mechanism encodes time information on user-item interaction, allowing the model to naturally capture temporal context, while the graph-structural prompt learning mechanism enables the transfer of pre-trained knowledge to adapt to behavior dynamics without the need for continuous incremental training. We further bring in a dynamic evaluation setting for recommendation to mimic real-world dynamic scenarios and bridge the offline-online gap to a better level. Our extensive experiments including a large-scale industrial deployment showcases the lightweight plug-in scalability of our GraphPL when integrated with various state-of-the-art recommenders, emphasizing the advantages of GraphPL in terms of effectiveness, robustness and efficiency.
Debiased Contrastive Learning for Sequential Recommendation
Mar 21, 2023



Current sequential recommender systems are proposed to tackle the dynamic user preference learning with various neural techniques, such as Transformer and Graph Neural Networks (GNNs). However, inference from the highly sparse user behavior data may hinder the representation ability of sequential pattern encoding. To address the label shortage issue, contrastive learning (CL) methods are proposed recently to perform data augmentation in two fashions: (i) randomly corrupting the sequence data (e.g. stochastic masking, reordering); (ii) aligning representations across pre-defined contrastive views. Although effective, we argue that current CL-based methods have limitations in addressing popularity bias and disentangling of user conformity and real interest. In this paper, we propose a new Debiased Contrastive learning paradigm for Recommendation (DCRec) that unifies sequential pattern encoding with global collaborative relation modeling through adaptive conformity-aware augmentation. This solution is designed to tackle the popularity bias issue in recommendation systems. Our debiased contrastive learning framework effectively captures both the patterns of item transitions within sequences and the dependencies between users across sequences. Our experiments on various real-world datasets have demonstrated that DCRec significantly outperforms state-of-the-art baselines, indicating its efficacy for recommendation. To facilitate reproducibility of our results, we make our implementation of DCRec publicly available at: https://github.com/HKUDS/DCRec.
Automated Self-Supervised Learning for Recommendation
Mar 21, 2023



Graph neural networks (GNNs) have emerged as the state-of-the-art paradigm for collaborative filtering (CF). To improve the representation quality over limited labeled data, contrastive learning has attracted attention in recommendation and benefited graph-based CF model recently. However, the success of most contrastive methods heavily relies on manually generating effective contrastive views for heuristic-based data augmentation. This does not generalize across different datasets and downstream recommendation tasks, which is difficult to be adaptive for data augmentation and robust to noise perturbation. To fill this crucial gap, this work proposes a unified Automated Collaborative Filtering (AutoCF) to automatically perform data augmentation for recommendation. Specifically, we focus on the generative self-supervised learning framework with a learnable augmentation paradigm that benefits the automated distillation of important self-supervised signals. To enhance the representation discrimination ability, our masked graph autoencoder is designed to aggregate global information during the augmentation via reconstructing the masked subgraph structures. Experiments and ablation studies are performed on several public datasets for recommending products, venues, and locations. Results demonstrate the superiority of AutoCF against various baseline methods. We release the model implementation at https://github.com/HKUDS/AutoCF.
Directed Acyclic Graph Factorization Machines for CTR Prediction via Knowledge Distillation
Nov 21, 2022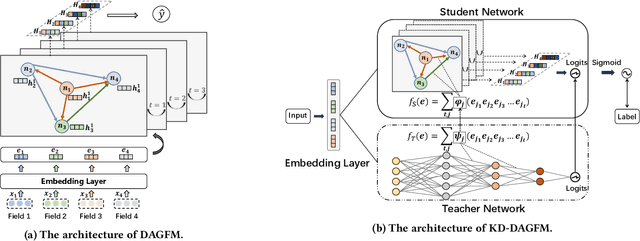



With the growth of high-dimensional sparse data in web-scale recommender systems, the computational cost to learn high-order feature interaction in CTR prediction task largely increases, which limits the use of high-order interaction models in real industrial applications. Some recent knowledge distillation based methods transfer knowledge from complex teacher models to shallow student models for accelerating the online model inference. However, they suffer from the degradation of model accuracy in knowledge distillation process. It is challenging to balance the efficiency and effectiveness of the shallow student models. To address this problem, we propose a Directed Acyclic Graph Factorization Machine (KD-DAGFM) to learn the high-order feature interactions from existing complex interaction models for CTR prediction via Knowledge Distillation. The proposed lightweight student model DAGFM can learn arbitrary explicit feature interactions from teacher networks, which achieves approximately lossless performance and is proved by a dynamic programming algorithm. Besides, an improved general model KD-DAGFM+ is shown to be effective in distilling both explicit and implicit feature interactions from any complex teacher model. Extensive experiments are conducted on four real-world datasets, including a large-scale industrial dataset from WeChat platform with billions of feature dimensions. KD-DAGFM achieves the best performance with less than 21.5% FLOPs of the state-of-the-art method on both online and offline experiments, showing the superiority of DAGFM to deal with the industrial scale data in CTR prediction task. Our implementation code is available at: https://github.com/RUCAIBox/DAGFM.
RESUS: Warm-Up Cold Users via Meta-Learning Residual User Preferences in CTR Prediction
Oct 28, 2022Click-Through Rate (CTR) prediction on cold users is a challenging task in recommender systems. Recent researches have resorted to meta-learning to tackle the cold-user challenge, which either perform few-shot user representation learning or adopt optimization-based meta-learning. However, existing methods suffer from information loss or inefficient optimization process, and they fail to explicitly model global user preference knowledge which is crucial to complement the sparse and insufficient preference information of cold users. In this paper, we propose a novel and efficient approach named RESUS, which decouples the learning of global preference knowledge contributed by collective users from the learning of residual preferences for individual users. Specifically, we employ a shared predictor to infer basis user preferences, which acquires global preference knowledge from the interactions of different users. Meanwhile, we develop two efficient algorithms based on the nearest neighbor and ridge regression predictors, which infer residual user preferences via learning quickly from a few user-specific interactions. Extensive experiments on three public datasets demonstrate that our RESUS approach is efficient and effective in improving CTR prediction accuracy on cold users, compared with various state-of-the-art methods.
Masked Transformer for Neighhourhood-aware Click-Through Rate Prediction
Jan 25, 2022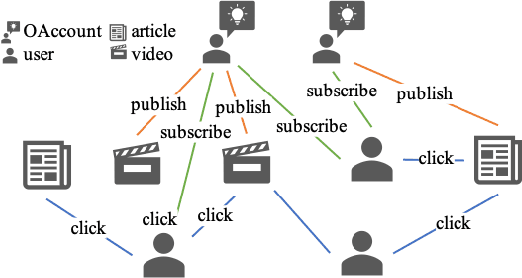
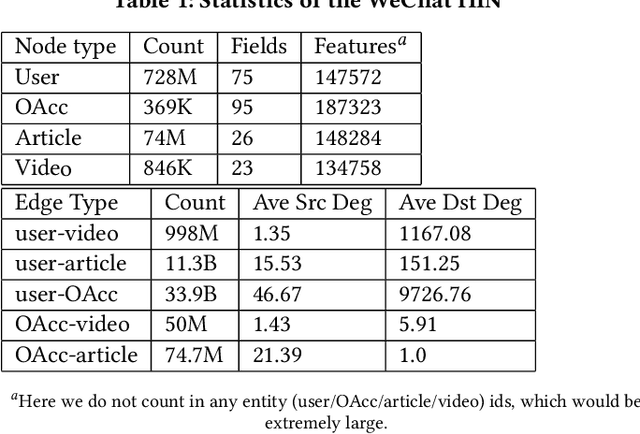
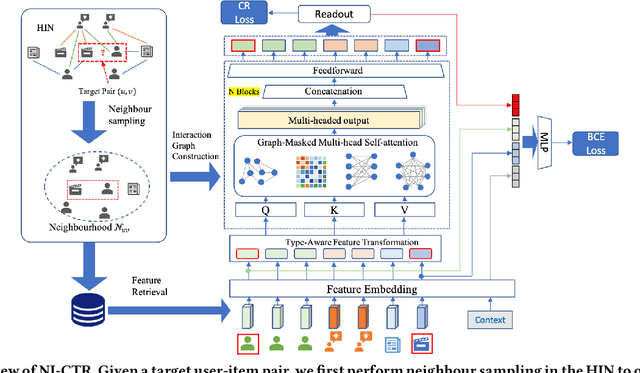
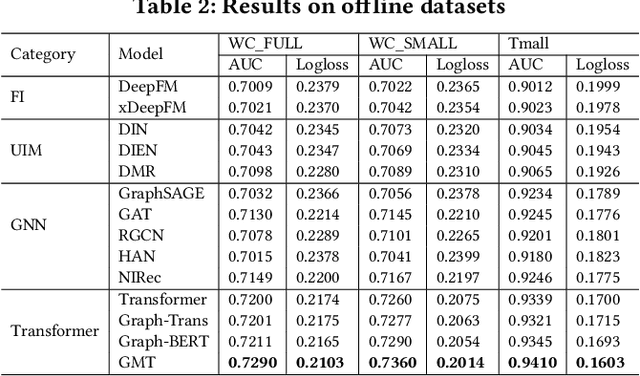
Click-Through Rate (CTR) prediction, is an essential component of online advertising. The mainstream techniques mostly focus on feature interaction or user interest modeling, which rely on users' directly interacted items. The performance of these methods are usally impeded by inactive behaviours and system's exposure, incurring that the features extracted do not contain enough information to represent all potential interests. For this sake, we propose Neighbor-Interaction based CTR prediction, which put this task into a Heterogeneous Information Network (HIN) setting, then involves local neighborhood of the target user-item pair in the HIN to predict their linkage. In order to enhance the representation of the local neighbourhood, we consider four types of topological interaction among the nodes, and propose a novel Graph-masked Transformer architecture to effectively incorporates both feature and topological information. We conduct comprehensive experiments on two real world datasets and the experimental results show that our proposed method outperforms state-of-the-art CTR models significantly.