 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLess is More: Unlocking Specialization of Time Series Foundation Models via Structured Pruning
May 29, 2025Scaling laws motivate the development of Time Series Foundation Models (TSFMs) that pre-train vast parameters and achieve remarkable zero-shot forecasting performance. Surprisingly, even after fine-tuning, TSFMs cannot consistently outperform smaller, specialized models trained on full-shot downstream data. A key question is how to realize effective adaptation of TSFMs for a target forecasting task. Through empirical studies on various TSFMs, the pre-trained models often exhibit inherent sparsity and redundancy in computation, suggesting that TSFMs have learned to activate task-relevant network substructures to accommodate diverse forecasting tasks. To preserve this valuable prior knowledge, we propose a structured pruning method to regularize the subsequent fine-tuning process by focusing it on a more relevant and compact parameter space. Extensive experiments on seven TSFMs and six benchmarks demonstrate that fine-tuning a smaller, pruned TSFM significantly improves forecasting performance compared to fine-tuning original models. This "prune-then-finetune" paradigm often enables TSFMs to achieve state-of-the-art performance and surpass strong specialized baselines.
Proactive Model Adaptation Against Concept Drift for Online Time Series Forecasting
Dec 11, 2024



Time series forecasting always faces the challenge of concept drift, where data distributions evolve over time, leading to a decline in forecast model performance. Existing solutions are based on online learning, which continually organize recent time series observations as new training samples and update model parameters according to the forecasting feedback on recent data. However, they overlook a critical issue: obtaining ground-truth future values of each sample should be delayed until after the forecast horizon. This delay creates a temporal gap between the training samples and the test sample. Our empirical analysis reveals that the gap can introduce concept drift, causing forecast models to adapt to outdated concepts. In this paper, we present \textsc{Proceed}, a novel proactive model adaptation framework for online time series forecasting. \textsc{Proceed} first operates by estimating the concept drift between the recently used training samples and the current test sample. It then employs an adaptation generator to efficiently translate the estimated drift into parameter adjustments, proactively adapting the model to the test sample. To enhance the generalization capability of the framework, \textsc{Proceed} is trained on synthetic diverse concept drifts. We conduct extensive experiments on five real-world datasets across various forecast models. The empirical study demonstrates that our proposed \textsc{Proceed} brings more performance improvements than the state-of-the-art online learning methods, significantly facilitating forecast models' resilience against concept drifts.
Rethinking Channel Dependence for Multivariate Time Series Forecasting: Learning from Leading Indicators
Jan 31, 2024



Recently, channel-independent methods have achieved state-of-the-art performance in multivariate time series (MTS) forecasting. Despite reducing overfitting risks, these methods miss potential opportunities in utilizing channel dependence for accurate predictions. We argue that there exist locally stationary lead-lag relationships between variates, i.e., some lagged variates may follow the leading indicators within a short time period. Exploiting such channel dependence is beneficial since leading indicators offer advance information that can be used to reduce the forecasting difficulty of the lagged variates. In this paper, we propose a new method named LIFT that first efficiently estimates leading indicators and their leading steps at each time step and then judiciously allows the lagged variates to utilize the advance information from leading indicators. LIFT plays as a plugin that can be seamlessly collaborated with arbitrary time series forecasting methods. Extensive experiments on six real-world datasets demonstrate that LIFT improves the state-of-the-art methods by 5.5% in average forecasting performance.
Methods for Acquiring and Incorporating Knowledge into Stock Price Prediction: A Survey
Aug 09, 2023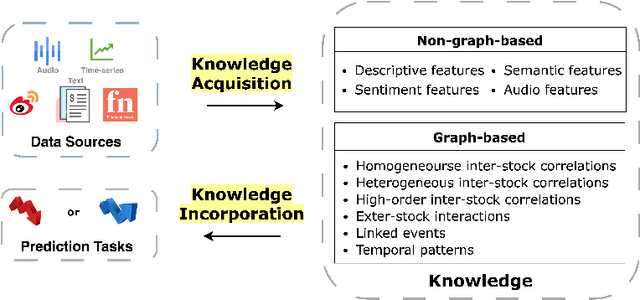
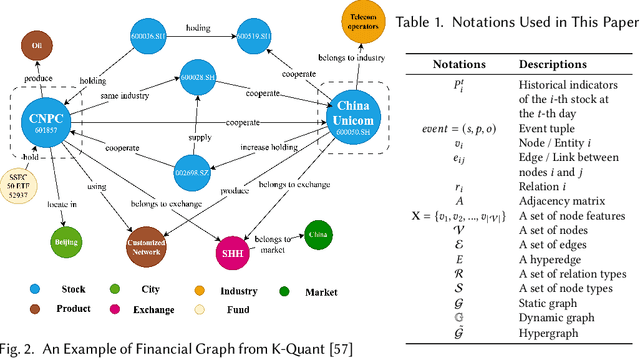
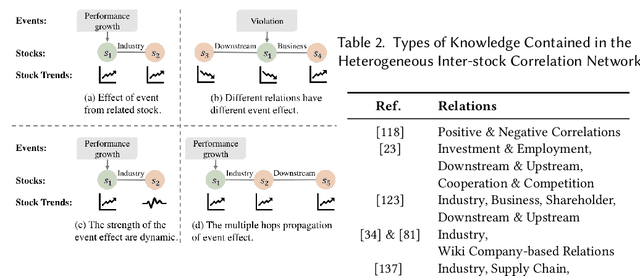
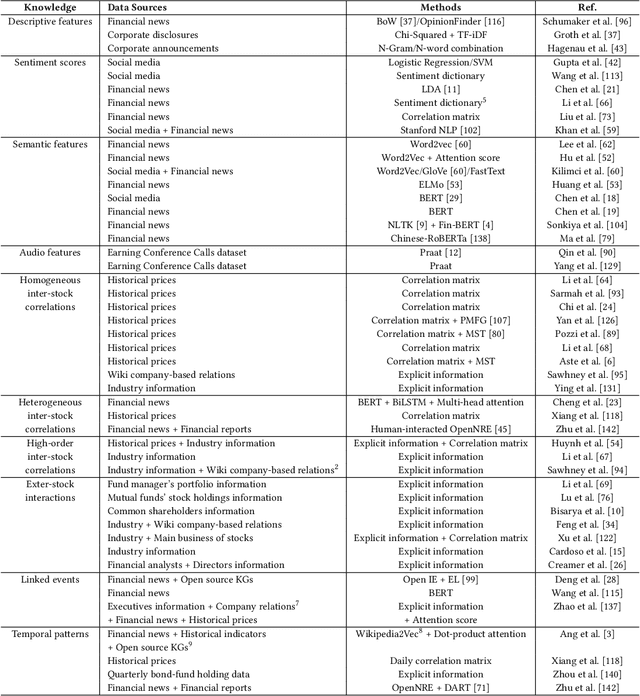
Predicting stock prices presents a challenging research problem due to the inherent volatility and non-linear nature of the stock market. In recent years, knowledge-enhanced stock price prediction methods have shown groundbreaking results by utilizing external knowledge to understand the stock market. Despite the importance of these methods, there is a scarcity of scholarly works that systematically synthesize previous studies from the perspective of external knowledge types. Specifically, the external knowledge can be modeled in different data structures, which we group into non-graph-based formats and graph-based formats: 1) non-graph-based knowledge captures contextual information and multimedia descriptions specifically associated with an individual stock; 2) graph-based knowledge captures interconnected and interdependent information in the stock market. This survey paper aims to provide a systematic and comprehensive description of methods for acquiring external knowledge from various unstructured data sources and then incorporating it into stock price prediction models. We also explore fusion methods for combining external knowledge with historical price features. Moreover, this paper includes a compilation of relevant datasets and delves into potential future research directions in this domain.
DoubleAdapt: A Meta-learning Approach to Incremental Learning for Stock Trend Forecasting
Jun 16, 2023



Stock trend forecasting is a fundamental task of quantitative investment where precise predictions of price trends are indispensable. As an online service, stock data continuously arrive over time. It is practical and efficient to incrementally update the forecast model with the latest data which may reveal some new patterns recurring in the future stock market. However, incremental learning for stock trend forecasting still remains under-explored due to the challenge of distribution shifts (a.k.a. concept drifts). With the stock market dynamically evolving, the distribution of future data can slightly or significantly differ from incremental data, hindering the effectiveness of incremental updates. To address this challenge, we propose DoubleAdapt, an end-to-end framework with two adapters, which can effectively adapt the data and the model to mitigate the effects of distribution shifts. Our key insight is to automatically learn how to adapt stock data into a locally stationary distribution in favor of profitable updates. Complemented by data adaptation, we can confidently adapt the model parameters under mitigated distribution shifts. We cast each incremental learning task as a meta-learning task and automatically optimize the adapters for desirable data adaptation and parameter initialization. Experiments on real-world stock datasets demonstrate that DoubleAdapt achieves state-of-the-art predictive performance and shows considerable efficiency.
RESUS: Warm-Up Cold Users via Meta-Learning Residual User Preferences in CTR Prediction
Oct 28, 2022Click-Through Rate (CTR) prediction on cold users is a challenging task in recommender systems. Recent researches have resorted to meta-learning to tackle the cold-user challenge, which either perform few-shot user representation learning or adopt optimization-based meta-learning. However, existing methods suffer from information loss or inefficient optimization process, and they fail to explicitly model global user preference knowledge which is crucial to complement the sparse and insufficient preference information of cold users. In this paper, we propose a novel and efficient approach named RESUS, which decouples the learning of global preference knowledge contributed by collective users from the learning of residual preferences for individual users. Specifically, we employ a shared predictor to infer basis user preferences, which acquires global preference knowledge from the interactions of different users. Meanwhile, we develop two efficient algorithms based on the nearest neighbor and ridge regression predictors, which infer residual user preferences via learning quickly from a few user-specific interactions. Extensive experiments on three public datasets demonstrate that our RESUS approach is efficient and effective in improving CTR prediction accuracy on cold users, compared with various state-of-the-art methods.
Exemplar Based Deep Discriminative and Shareable Feature Learning for Scene Image Classification
Aug 21, 2015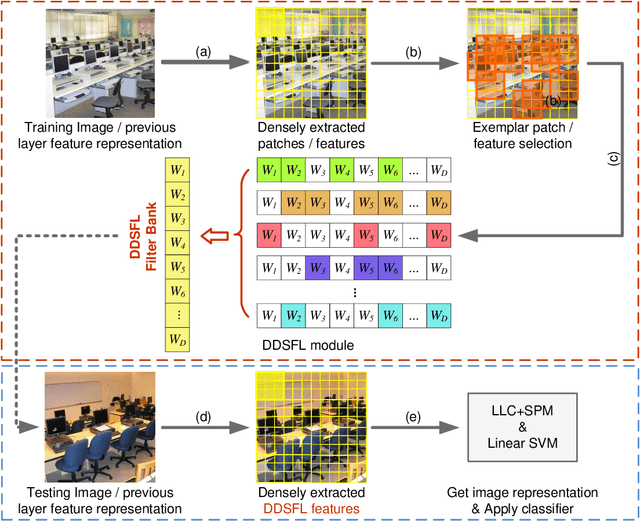
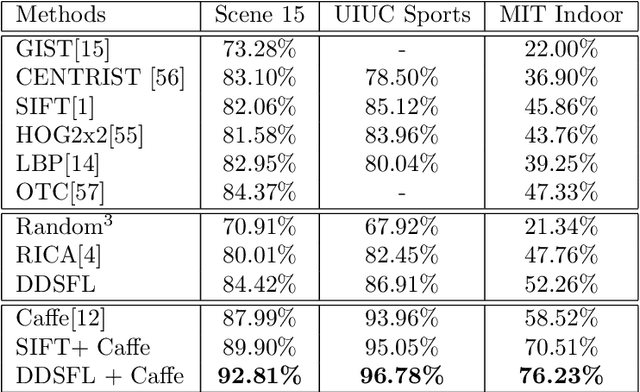
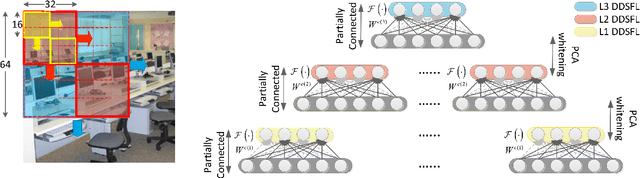
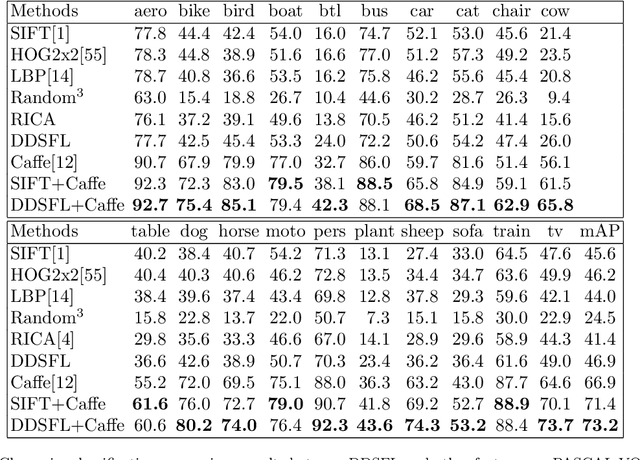
In order to encode the class correlation and class specific information in image representation, we propose a new local feature learning approach named Deep Discriminative and Shareable Feature Learning (DDSFL). DDSFL aims to hierarchically learn feature transformation filter banks to transform raw pixel image patches to features. The learned filter banks are expected to: (1) encode common visual patterns of a flexible number of categories; (2) encode discriminative information; and (3) hierarchically extract patterns at different visual levels. Particularly, in each single layer of DDSFL, shareable filters are jointly learned for classes which share the similar patterns. Discriminative power of the filters is achieved by enforcing the features from the same category to be close, while features from different categories to be far away from each other. Furthermore, we also propose two exemplar selection methods to iteratively select training data for more efficient and effective learning. Based on the experimental results, DDSFL can achieve very promising performance, and it also shows great complementary effect to the state-of-the-art Caffe features.