 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Recurrent Neural Networks with Information Transfer Layers for Indoor Scene Labeling
Mar 13, 2018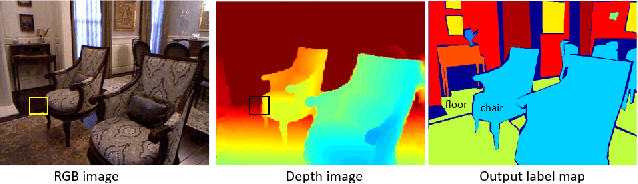

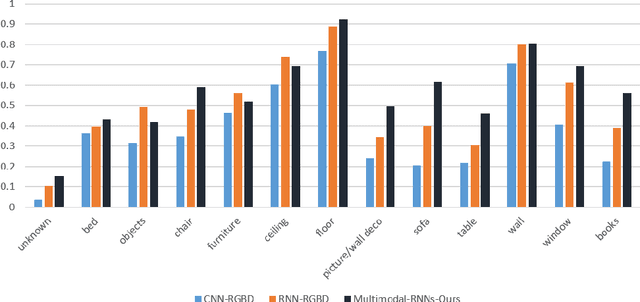
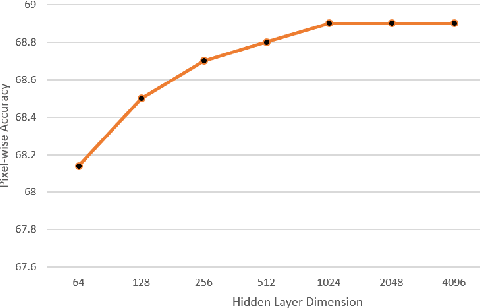
This paper proposes a new method called Multimodal RNNs for RGB-D scene semantic segmentation. It is optimized to classify image pixels given two input sources: RGB color channels and Depth maps. It simultaneously performs training of two recurrent neural networks (RNNs) that are crossly connected through information transfer layers, which are learnt to adaptively extract relevant cross-modality features. Each RNN model learns its representations from its own previous hidden states and transferred patterns from the other RNNs previous hidden states; thus, both model-specific and crossmodality features are retained. We exploit the structure of quad-directional 2D-RNNs to model the short and long range contextual information in the 2D input image. We carefully designed various baselines to efficiently examine our proposed model structure. We test our Multimodal RNNs method on popular RGB-D benchmarks and show how it outperforms previous methods significantly and achieves competitive results with other state-of-the-art works.
* 15 pages, 13 figures, IEEE TMM 2017
Joint Learning of Siamese CNNs and Temporally Constrained Metrics for Tracklet Association
Sep 25, 2016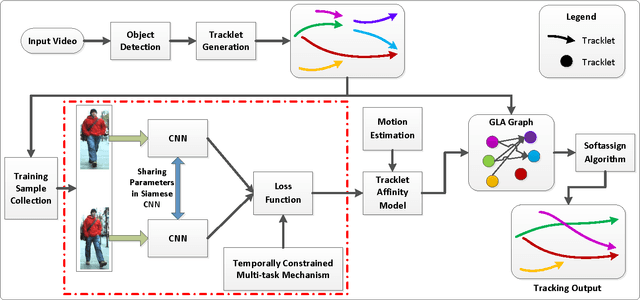
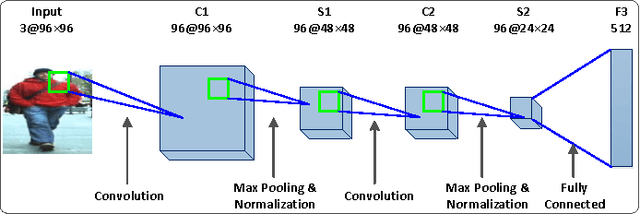
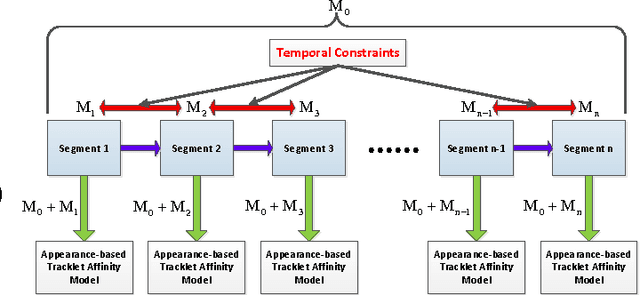

In this paper, we study the challenging problem of multi-object tracking in a complex scene captured by a single camera. Different from the existing tracklet association-based tracking methods, we propose a novel and efficient way to obtain discriminative appearance-based tracklet affinity models. Our proposed method jointly learns the convolutional neural networks (CNNs) and temporally constrained metrics. In our method, a Siamese convolutional neural network (CNN) is first pre-trained on the auxiliary data. Then the Siamese CNN and temporally constrained metrics are jointly learned online to construct the appearance-based tracklet affinity models. The proposed method can jointly learn the hierarchical deep features and temporally constrained segment-wise metrics under a unified framework. For reliable association between tracklets, a novel loss function incorporating temporally constrained multi-task learning mechanism is proposed. By employing the proposed method, tracklet association can be accomplished even in challenging situations. Moreover, a new dataset with 40 fully annotated sequences is created to facilitate the tracking evaluation. Experimental results on five public datasets and the new large-scale dataset show that our method outperforms several state-of-the-art approaches in multi-object tracking.
Scene Parsing with Integration of Parametric and Non-parametric Models
Apr 20, 2016
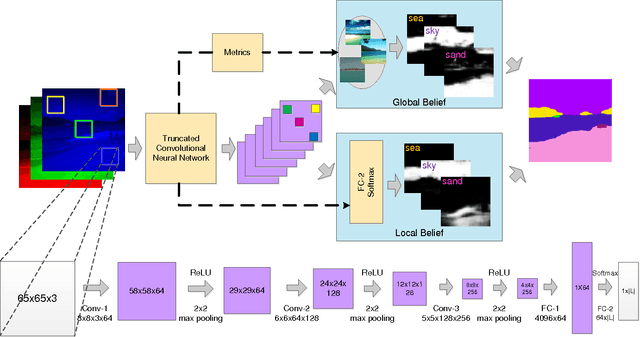
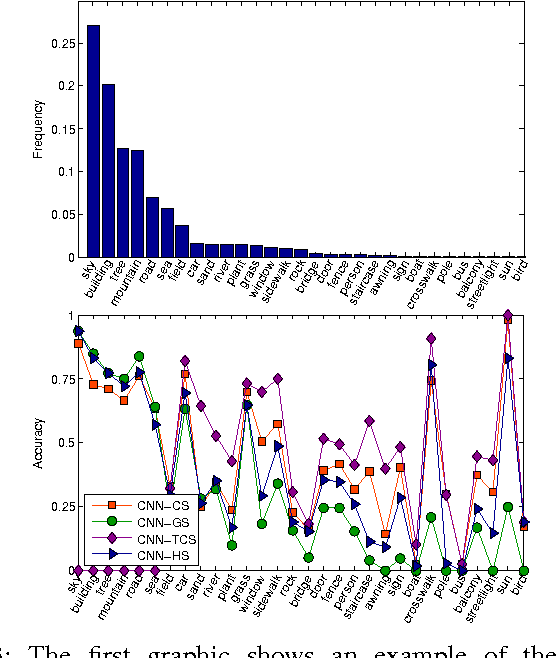
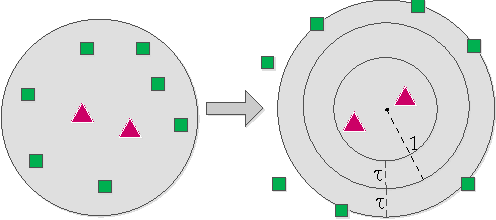
We adopt Convolutional Neural Networks (CNNs) to be our parametric model to learn discriminative features and classifiers for local patch classification. Based on the occurrence frequency distribution of classes, an ensemble of CNNs (CNN-Ensemble) are learned, in which each CNN component focuses on learning different and complementary visual patterns. The local beliefs of pixels are output by CNN-Ensemble. Considering that visually similar pixels are indistinguishable under local context, we leverage the global scene semantics to alleviate the local ambiguity. The global scene constraint is mathematically achieved by adding a global energy term to the labeling energy function, and it is practically estimated in a non-parametric framework. A large margin based CNN metric learning method is also proposed for better global belief estimation. In the end, the integration of local and global beliefs gives rise to the class likelihood of pixels, based on which maximum marginal inference is performed to generate the label prediction maps. Even without any post-processing, we achieve state-of-the-art results on the challenging SiftFlow and Barcelona benchmarks.
Learning Contextual Dependencies with Convolutional Hierarchical Recurrent Neural Networks
Feb 07, 2016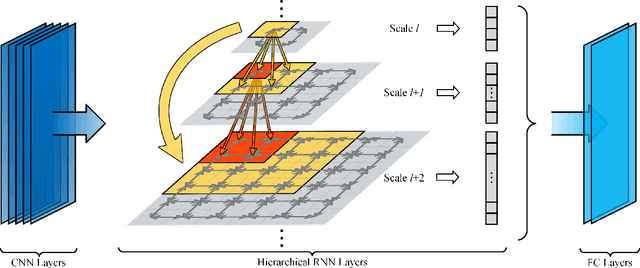
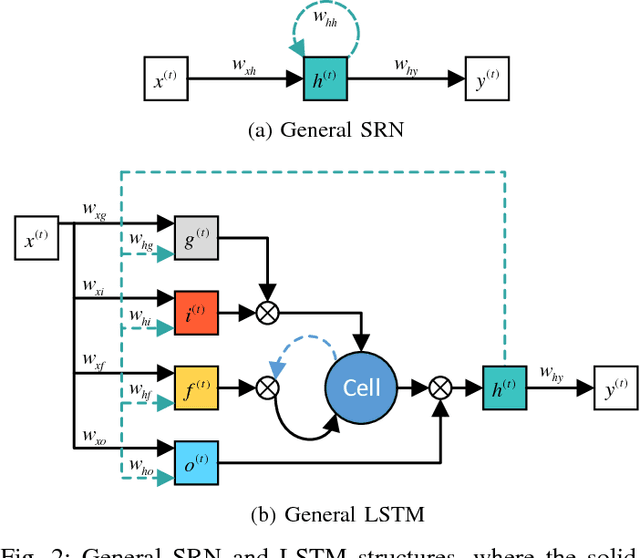

Existing deep convolutional neural networks (CNNs) have shown their great success on image classification. CNNs mainly consist of convolutional and pooling layers, both of which are performed on local image areas without considering the dependencies among different image regions. However, such dependencies are very important for generating explicit image representation. In contrast, recurrent neural networks (RNNs) are well known for their ability of encoding contextual information among sequential data, and they only require a limited number of network parameters. General RNNs can hardly be directly applied on non-sequential data. Thus, we proposed the hierarchical RNNs (HRNNs). In HRNNs, each RNN layer focuses on modeling spatial dependencies among image regions from the same scale but different locations. While the cross RNN scale connections target on modeling scale dependencies among regions from the same location but different scales. Specifically, we propose two recurrent neural network models: 1) hierarchical simple recurrent network (HSRN), which is fast and has low computational cost; and 2) hierarchical long-short term memory recurrent network (HLSTM), which performs better than HSRN with the price of more computational cost. In this manuscript, we integrate CNNs with HRNNs, and develop end-to-end convolutional hierarchical recurrent neural networks (C-HRNNs). C-HRNNs not only make use of the representation power of CNNs, but also efficiently encodes spatial and scale dependencies among different image regions. On four of the most challenging object/scene image classification benchmarks, our C-HRNNs achieve state-of-the-art results on Places 205, SUN 397, MIT indoor, and competitive results on ILSVRC 2012.
DAG-Recurrent Neural Networks For Scene Labeling
Nov 23, 2015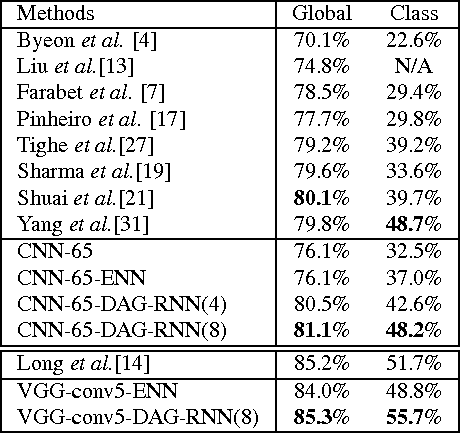
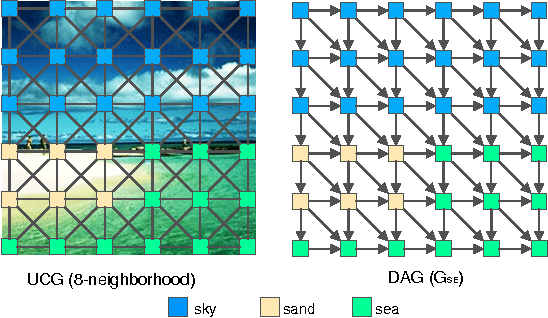
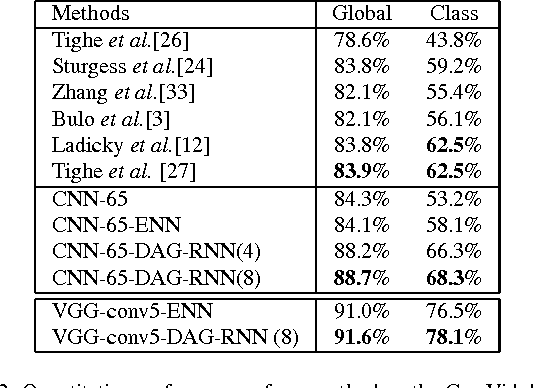
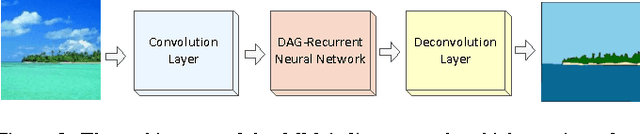
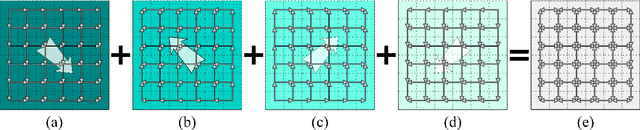
In image labeling, local representations for image units are usually generated from their surrounding image patches, thus long-range contextual information is not effectively encoded. In this paper, we introduce recurrent neural networks (RNNs) to address this issue. Specifically, directed acyclic graph RNNs (DAG-RNNs) are proposed to process DAG-structured images, which enables the network to model long-range semantic dependencies among image units. Our DAG-RNNs are capable of tremendously enhancing the discriminative power of local representations, which significantly benefits the local classification. Meanwhile, we propose a novel class weighting function that attends to rare classes, which phenomenally boosts the recognition accuracy for non-frequent classes. Integrating with convolution and deconvolution layers, our DAG-RNNs achieve new state-of-the-art results on the challenging SiftFlow, CamVid and Barcelona benchmarks.
Exemplar Based Deep Discriminative and Shareable Feature Learning for Scene Image Classification
Aug 21, 2015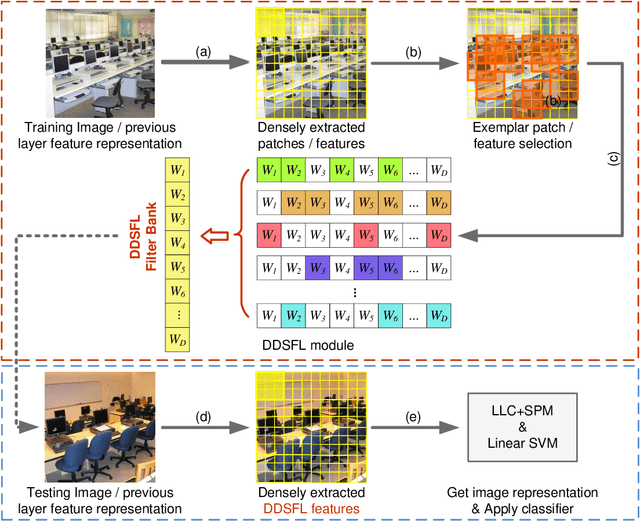
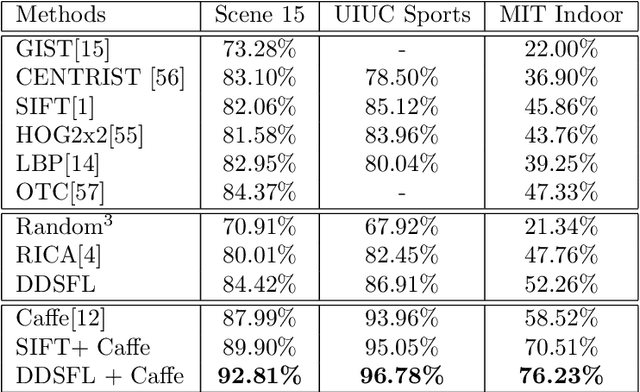
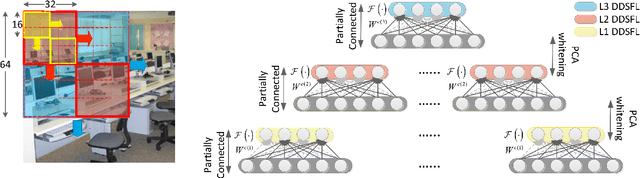
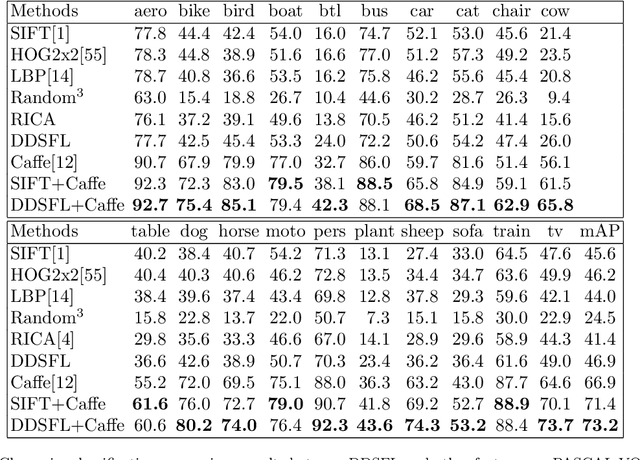
In order to encode the class correlation and class specific information in image representation, we propose a new local feature learning approach named Deep Discriminative and Shareable Feature Learning (DDSFL). DDSFL aims to hierarchically learn feature transformation filter banks to transform raw pixel image patches to features. The learned filter banks are expected to: (1) encode common visual patterns of a flexible number of categories; (2) encode discriminative information; and (3) hierarchically extract patterns at different visual levels. Particularly, in each single layer of DDSFL, shareable filters are jointly learned for classes which share the similar patterns. Discriminative power of the filters is achieved by enforcing the features from the same category to be close, while features from different categories to be far away from each other. Furthermore, we also propose two exemplar selection methods to iteratively select training data for more efficient and effective learning. Based on the experimental results, DDSFL can achieve very promising performance, and it also shows great complementary effect to the state-of-the-art Caffe features.