 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Recurrent Neural Networks with Information Transfer Layers for Indoor Scene Labeling
Mar 13, 2018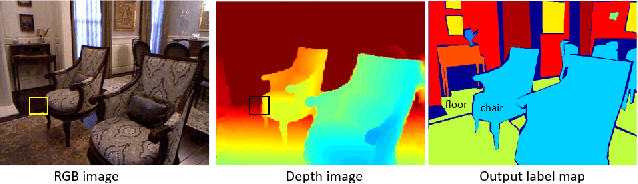

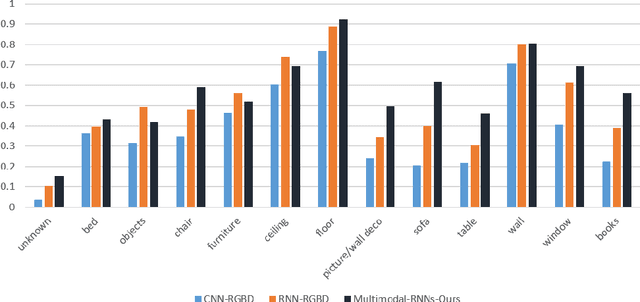
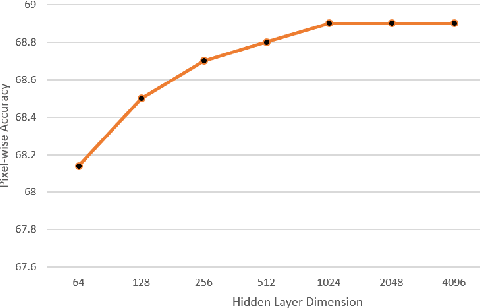
This paper proposes a new method called Multimodal RNNs for RGB-D scene semantic segmentation. It is optimized to classify image pixels given two input sources: RGB color channels and Depth maps. It simultaneously performs training of two recurrent neural networks (RNNs) that are crossly connected through information transfer layers, which are learnt to adaptively extract relevant cross-modality features. Each RNN model learns its representations from its own previous hidden states and transferred patterns from the other RNNs previous hidden states; thus, both model-specific and crossmodality features are retained. We exploit the structure of quad-directional 2D-RNNs to model the short and long range contextual information in the 2D input image. We carefully designed various baselines to efficiently examine our proposed model structure. We test our Multimodal RNNs method on popular RGB-D benchmarks and show how it outperforms previous methods significantly and achieves competitive results with other state-of-the-art works.
* 15 pages, 13 figures, IEEE TMM 2017
Beyond Forward Shortcuts: Fully Convolutional Master-Slave Networks (MSNets) with Backward Skip Connections for Semantic Segmentation
Jul 18, 2017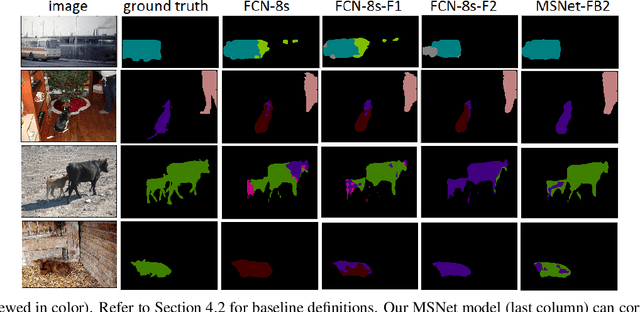

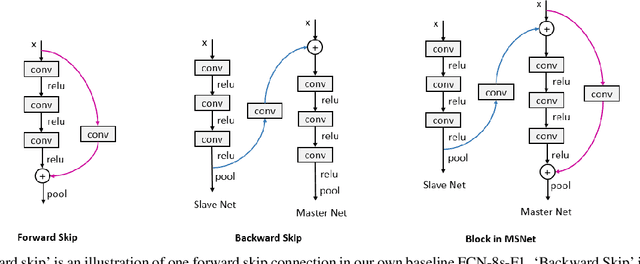
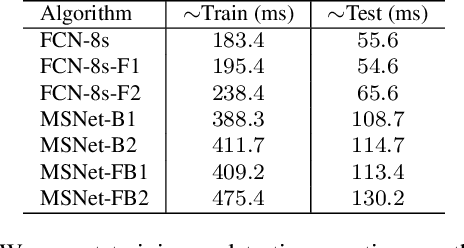
Recent deep CNNs contain forward shortcut connections; i.e. skip connections from low to high layers. Reusing features from lower layers that have higher resolution (location information) benefit higher layers to recover lost details and mitigate information degradation. However, during inference the lower layers do not know about high layer features, although they contain contextual high semantics that benefit low layers to adaptively extract informative features for later layers. In this paper, we study the influence of backward skip connections which are in the opposite direction to forward shortcuts, i.e. paths from high layers to low layers. To achieve this -- which indeed runs counter to the nature of feed-forward networks -- we propose a new fully convolutional model that consists of a pair of networks. A `Slave' network is dedicated to provide the backward connections from its top layers to the `Master' network's bottom layers. The Master network is used to produce the final label predictions. In our experiments we validate the proposed FCN model on ADE20K (ImageNet scene parsing), PASCAL-Context, and PASCAL VOC 2011 datasets.
Multi-task CNN Model for Attribute Prediction
Jan 04, 2016
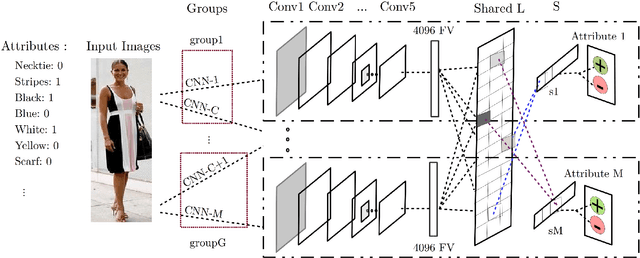
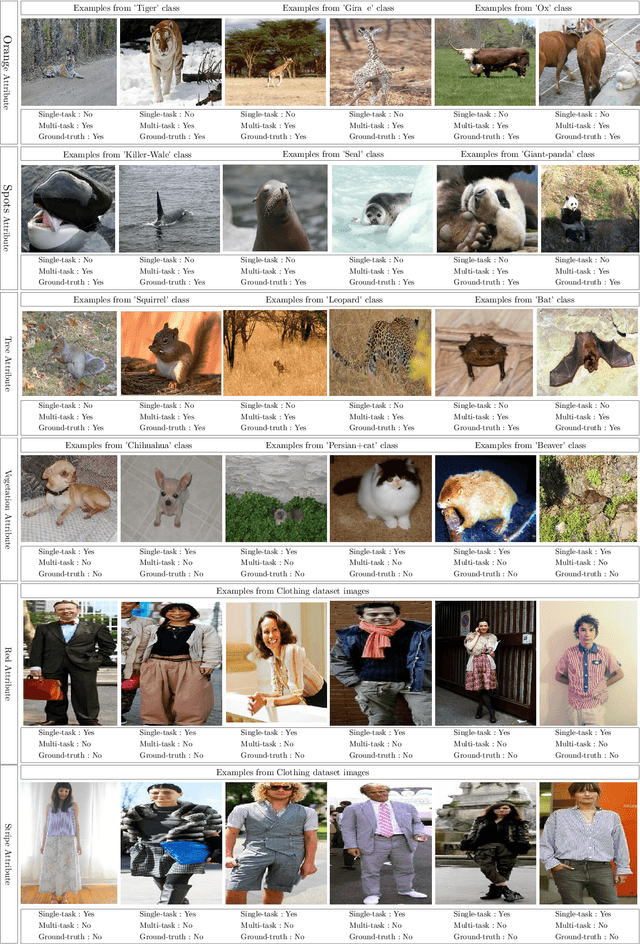

This paper proposes a joint multi-task learning algorithm to better predict attributes in images using deep convolutional neural networks (CNN). We consider learning binary semantic attributes through a multi-task CNN model, where each CNN will predict one binary attribute. The multi-task learning allows CNN models to simultaneously share visual knowledge among different attribute categories. Each CNN will generate attribute-specific feature representations, and then we apply multi-task learning on the features to predict their attributes. In our multi-task framework, we propose a method to decompose the overall model's parameters into a latent task matrix and combination matrix. Furthermore, under-sampled classifiers can leverage shared statistics from other classifiers to improve their performance. Natural grouping of attributes is applied such that attributes in the same group are encouraged to share more knowledge. Meanwhile, attributes in different groups will generally compete with each other, and consequently share less knowledge. We show the effectiveness of our method on two popular attribute datasets.
* 11 pages, 3 figures, ieee transaction paper