 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA statistical framework for fair predictive algorithms
Paper and Code
Oct 25, 2016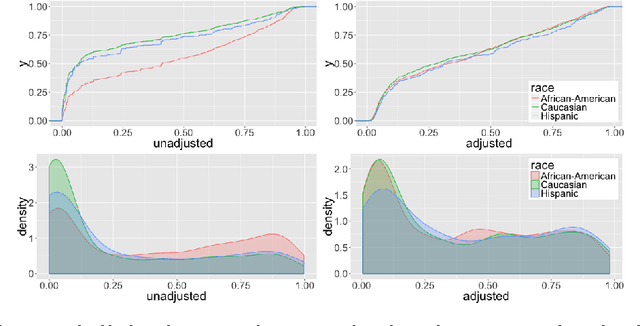
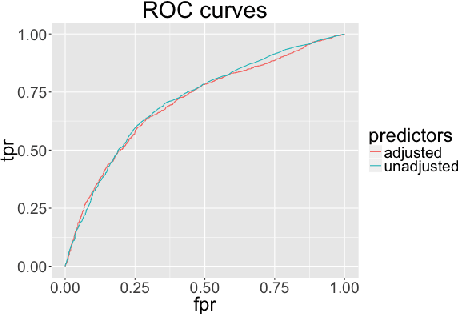
Predictive modeling is increasingly being employed to assist human decision-makers. One purported advantage of replacing human judgment with computer models in high stakes settings-- such as sentencing, hiring, policing, college admissions, and parole decisions-- is the perceived "neutrality" of computers. It is argued that because computer models do not hold personal prejudice, the predictions they produce will be equally free from prejudice. There is growing recognition that employing algorithms does not remove the potential for bias, and can even amplify it, since training data were inevitably generated by a process that is itself biased. In this paper, we provide a probabilistic definition of algorithmic bias. We propose a method to remove bias from predictive models by removing all information regarding protected variables from the permitted training data. Unlike previous work in this area, our framework is general enough to accommodate arbitrary data types, e.g. binary, continuous, etc. Motivated by models currently in use in the criminal justice system that inform decisions on pre-trial release and paroling, we apply our proposed method to a dataset on the criminal histories of individuals at the time of sentencing to produce "race-neutral" predictions of re-arrest. In the process, we demonstrate that the most common approach to creating "race-neutral" models-- omitting race as a covariate-- still results in racially disparate predictions. We then demonstrate that the application of our proposed method to these data removes racial disparities from predictions with minimal impact on predictive accuracy.