 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Computer Vision Pipeline for Iterative Bullet Hole Tracking in Rifle Zeroing
Jan 22, 2026Adjusting rifle sights, a process commonly called "zeroing," requires shooters to identify and differentiate bullet holes from multiple firing iterations. Traditionally, this process demands physical inspection, introducing delays due to range safety protocols and increasing the risk of human error. We present an end-to-end computer vision system for automated bullet hole detection and iteration-based tracking directly from images taken at the firing line. Our approach combines YOLOv8 for accurate small-object detection with Intersection over Union (IoU) analysis to differentiate bullet holes across sequential images. To address the scarcity of labeled sequential data, we propose a novel data augmentation technique that removes rather than adds objects to simulate realistic firing sequences. Additionally, we introduce a preprocessing pipeline that standardizes target orientation using ORB-based perspective correction, improving model accuracy. Our system achieves 97.0% mean average precision on bullet hole detection and 88.8% accuracy in assigning bullet holes to the correct firing iteration. While designed for rifle zeroing, this framework offers broader applicability in domains requiring the temporal differentiation of visually similar objects.
Automated software vulnerability detection with machine learning
Aug 02, 2018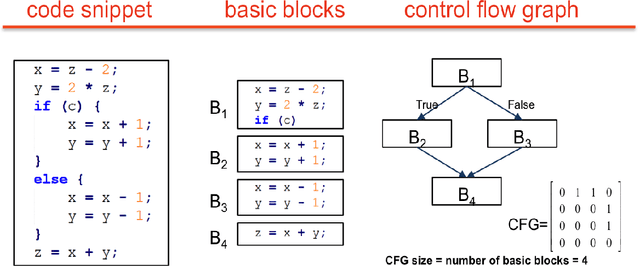
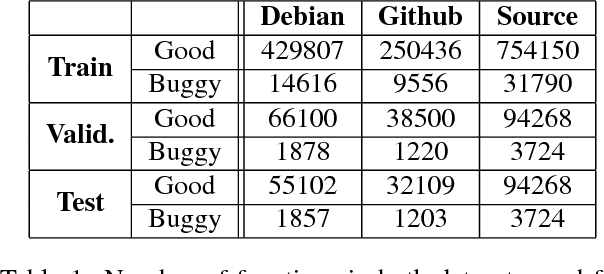
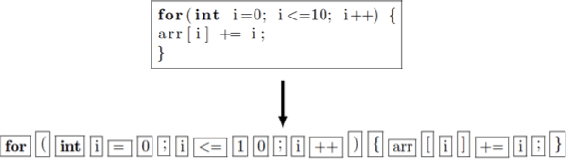
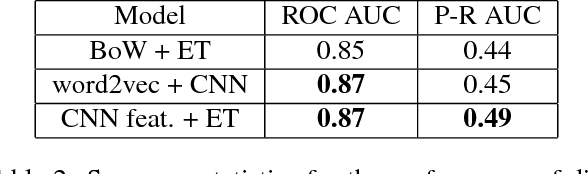
Thousands of security vulnerabilities are discovered in production software each year, either reported publicly to the Common Vulnerabilities and Exposures database or discovered internally in proprietary code. Vulnerabilities often manifest themselves in subtle ways that are not obvious to code reviewers or the developers themselves. With the wealth of open source code available for analysis, there is an opportunity to learn the patterns of bugs that can lead to security vulnerabilities directly from data. In this paper, we present a data-driven approach to vulnerability detection using machine learning, specifically applied to C and C++ programs. We first compile a large dataset of hundreds of thousands of open-source functions labeled with the outputs of a static analyzer. We then compare methods applied directly to source code with methods applied to artifacts extracted from the build process, finding that source-based models perform better. We also compare the application of deep neural network models with more traditional models such as random forests and find the best performance comes from combining features learned by deep models with tree-based models. Ultimately, our highest performing model achieves an area under the precision-recall curve of 0.49 and an area under the ROC curve of 0.87.