 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpanSeq: Similarity-based sequence data splitting method for improved development and assessment of deep learning projects
Mar 05, 2024



The use of deep learning models in computational biology has increased massively in recent years, and is expected to do so further with the current advances in fields like Natural Language Processing. These models, although able to draw complex relations between input and target, are also largely inclined to learn noisy deviations from the pool of data used during their development. In order to assess their performance on unseen data (their capacity to generalize), it is common to randomly split the available data in development (train/validation) and test sets. This procedure, although standard, has lately been shown to produce dubious assessments of generalization due to the existing similarity between samples in the databases used. In this work, we present SpanSeq, a database partition method for machine learning that can scale to most biological sequences (genes, proteins and genomes) in order to avoid data leakage between sets. We also explore the effect of not restraining similarity between sets by reproducing the development of the state-of-the-art model DeepLoc, not only confirming the consequences of randomly splitting databases on the model assessment, but expanding those repercussions to the model development. SpanSeq is available for downloading and installing at https://github.com/genomicepidemiology/SpanSeq.
Convolutional LSTM Networks for Subcellular Localization of Proteins
Mar 06, 2015
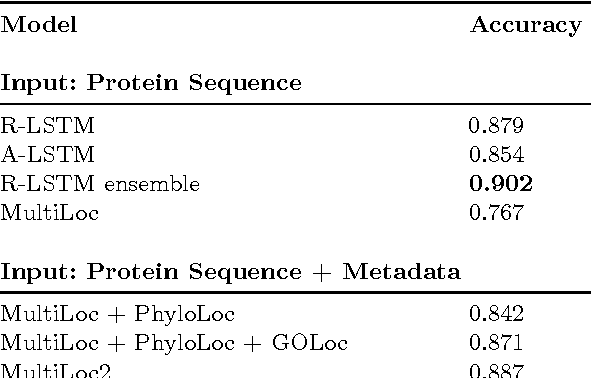

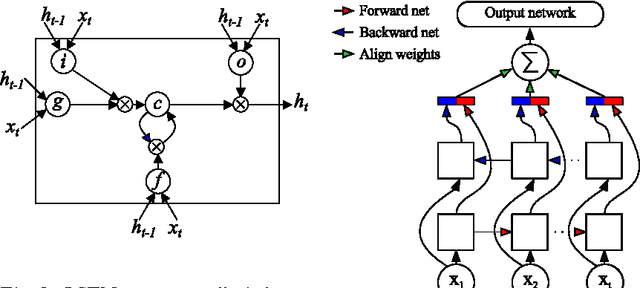
Machine learning is widely used to analyze biological sequence data. Non-sequential models such as SVMs or feed-forward neural networks are often used although they have no natural way of handling sequences of varying length. Recurrent neural networks such as the long short term memory (LSTM) model on the other hand are designed to handle sequences. In this study we demonstrate that LSTM networks predict the subcellular location of proteins given only the protein sequence with high accuracy (0.902) outperforming current state of the art algorithms. We further improve the performance by introducing convolutional filters and experiment with an attention mechanism which lets the LSTM focus on specific parts of the protein. Lastly we introduce new visualizations of both the convolutional filters and the attention mechanisms and show how they can be used to extract biological relevant knowledge from the LSTM networks.