 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFocusing on Context is NICE: Improving Overshadowed Entity Disambiguation
Oct 12, 2022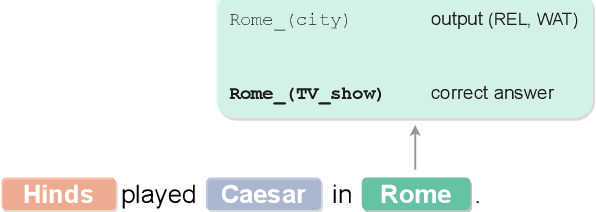
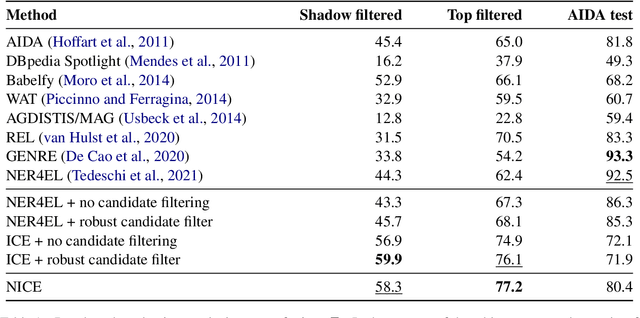
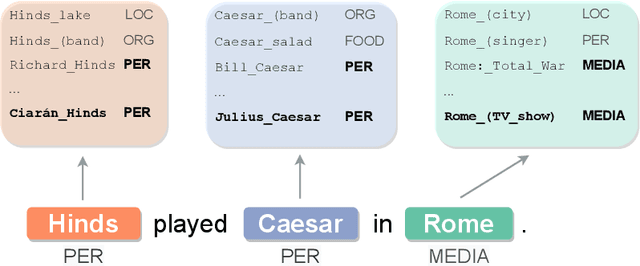
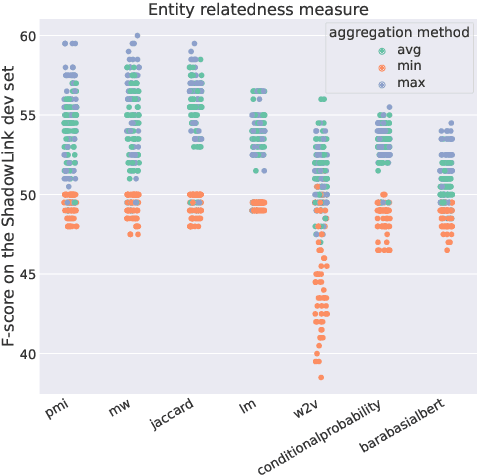
Entity disambiguation (ED) is the task of mapping an ambiguous entity mention to the corresponding entry in a structured knowledge base. Previous research showed that entity overshadowing is a significant challenge for existing ED models: when presented with an ambiguous entity mention, the models are much more likely to rank a more frequent yet less contextually relevant entity at the top. Here, we present NICE, an iterative approach that uses entity type information to leverage context and avoid over-relying on the frequency-based prior. Our experiments show that NICE achieves the best performance results on the overshadowed entities while still performing competitively on the frequent entities.
Robustness Evaluation of Entity Disambiguation Using Prior Probes:the Case of Entity Overshadowing
Aug 24, 2021
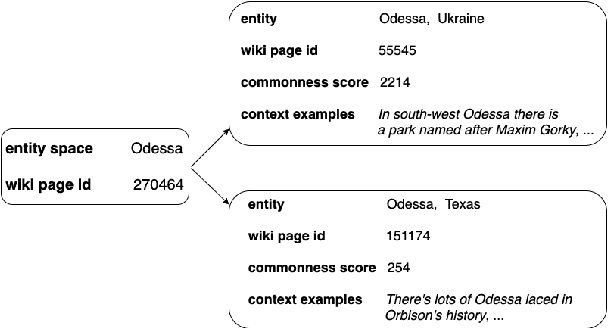
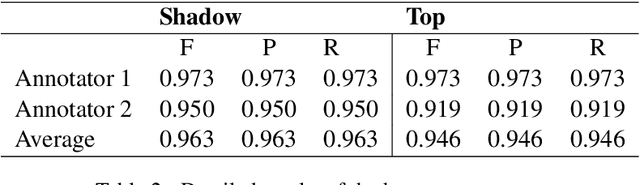
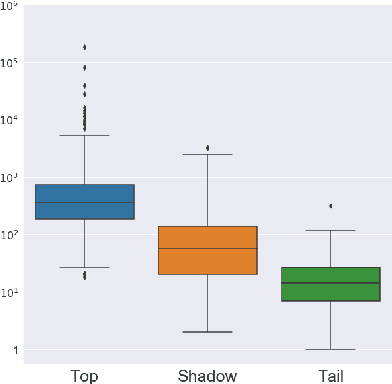
Entity disambiguation (ED) is the last step of entity linking (EL), when candidate entities are reranked according to the context they appear in. All datasets for training and evaluating models for EL consist of convenience samples, such as news articles and tweets, that propagate the prior probability bias of the entity distribution towards more frequently occurring entities. It was previously shown that the performance of the EL systems on such datasets is overestimated since it is possible to obtain higher accuracy scores by merely learning the prior. To provide a more adequate evaluation benchmark, we introduce the ShadowLink dataset, which includes 16K short text snippets annotated with entity mentions. We evaluate and report the performance of popular EL systems on the ShadowLink benchmark. The results show a considerable difference in accuracy between more and less common entities for all of the EL systems under evaluation, demonstrating the effects of prior probability bias and entity overshadowing.