Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDpgMedia2019: A Dutch News Dataset for Partisanship Detection
Aug 06, 2019
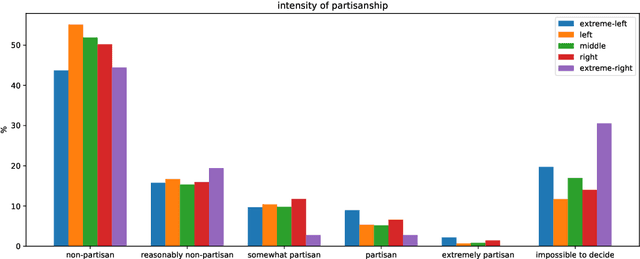
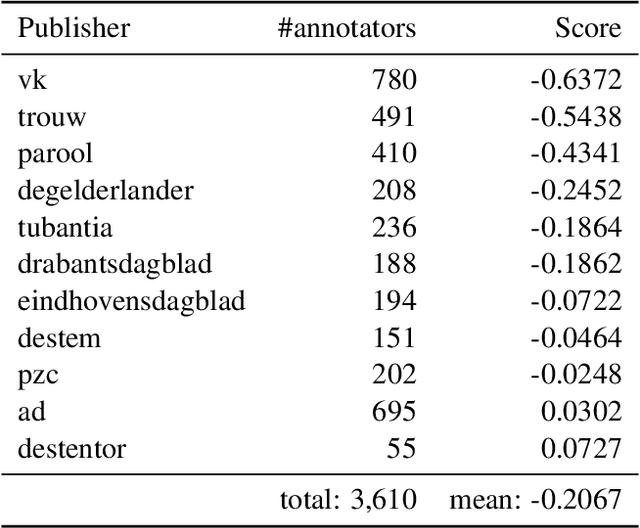
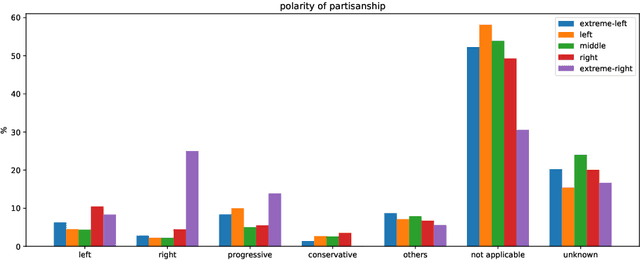
We present a new Dutch news dataset with labeled partisanship. The dataset contains more than 100K articles that are labeled on the publisher level and 776 articles that were crowdsourced using an internal survey platform and labeled on the article level. In this paper, we document our original motivation, the collection and annotation process, limitations, and applications.
Via