 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Transformer Attention Heads Provide Transparency in Abstractive Summarization?
Paper and Code

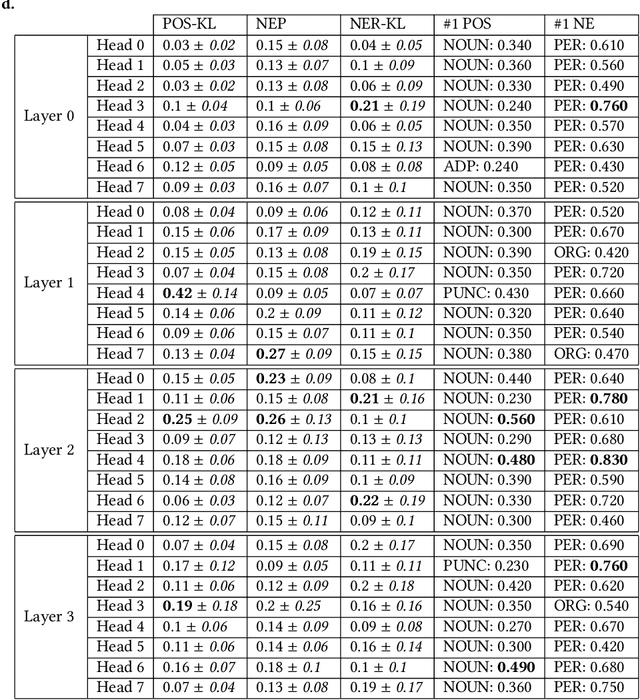

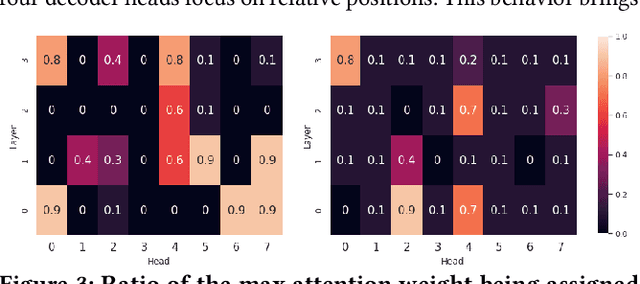
Learning algorithms become more powerful, often at the cost of increased complexity. In response, the demand for algorithms to be transparent is growing. In NLP tasks, attention distributions learned by attention-based deep learning models are used to gain insights in the models' behavior. To which extent is this perspective valid for all NLP tasks? We investigate whether distributions calculated by different attention heads in a transformer architecture can be used to improve transparency in the task of abstractive summarization. To this end, we present both a qualitative and quantitative analysis to investigate the behavior of the attention heads. We show that some attention heads indeed specialize towards syntactically and semantically distinct input. We propose an approach to evaluate to which extent the Transformer model relies on specifically learned attention distributions. We also discuss what this implies for using attention distributions as a means of transparency.