 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDelving into the Continuous Domain Adaptation
Paper and Code
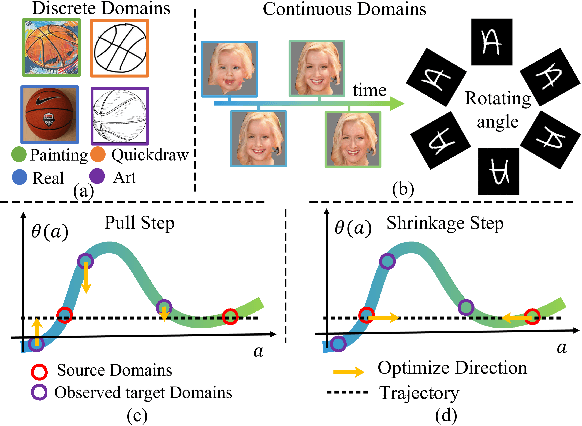

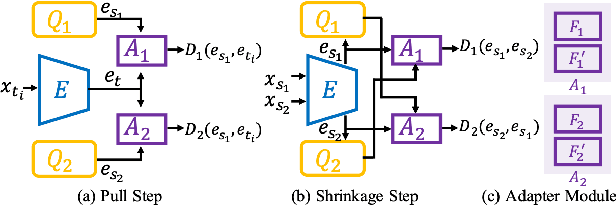
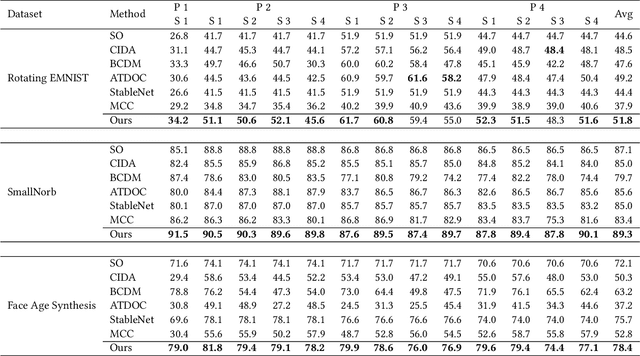
Existing domain adaptation methods assume that domain discrepancies are caused by a few discrete attributes and variations, e.g., art, real, painting, quickdraw, etc. We argue that this is not realistic as it is implausible to define the real-world datasets using a few discrete attributes. Therefore, we propose to investigate a new problem namely the Continuous Domain Adaptation (CDA) through the lens where infinite domains are formed by continuously varying attributes. Leveraging knowledge of two labeled source domains and several observed unlabeled target domains data, the objective of CDA is to learn a generalized model for whole data distribution with the continuous attribute. Besides the contributions of formulating a new problem, we also propose a novel approach as a strong CDA baseline. To be specific, firstly we propose a novel alternating training strategy to reduce discrepancies among multiple domains meanwhile generalize to unseen target domains. Secondly, we propose a continuity constraint when estimating the cross-domain divergence measurement. Finally, to decouple the discrepancy from the mini-batch size, we design a domain-specific queue to maintain the global view of the source domain that further boosts the adaptation performances. Our method is proven to achieve the state-of-the-art in CDA problem using extensive experiments. The code is available at https://github.com/SPIresearch/CDA.