 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausality-Aware Temporal Projection for Video Understanding in Video-LLMs
Jan 05, 2026Recent Video Large Language Models (Video-LLMs) have shown strong multimodal reasoning capabilities, yet remain challenged by video understanding tasks that require consistent temporal ordering and causal coherence. Many parameter-efficient Video-LLMs rely on unconstrained bidirectional projectors to model inter-frame interactions, which can blur temporal ordering by allowing later frames to influence earlier representations, without explicit architectural mechanisms to respect the directional nature of video reasoning. To address this limitation, we propose V-CORE, a parameter-efficient framework that introduces explicit temporal ordering constraints for video understanding. V-CORE consists of two key components: (1) Learnable Spatial Aggregation (LSA), which adaptively selects salient spatial tokens to reduce redundancy, and (2) a Causality-Aware Temporal Projector (CATP), which enforces structured unidirectional information flow via block-causal attention and a terminal dynamic summary token acting as a causal sink. This design preserves intra-frame spatial interactions while ensuring that temporal information is aggregated in a strictly ordered manner. With 4-bit QLoRA and a frozen LLM backbone, V-CORE can be trained efficiently on a single consumer GPU. Experiments show that V-CORE achieves strong performance on the challenging NExT-QA benchmark, reaching 61.2% accuracy, and remains competitive across MSVD-QA, MSRVTT-QA, and TGIF-QA, with gains concentrated in temporal and causal reasoning subcategories (+3.5% and +5.2% respectively), directly validating the importance of explicit temporal ordering constraints.
Route-DETR: Pairwise Query Routing in Transformers for Object Detection
Dec 15, 2025Detection Transformer (DETR) offers an end-to-end solution for object detection by eliminating hand-crafted components like non-maximum suppression. However, DETR suffers from inefficient query competition where multiple queries converge to similar positions, leading to redundant computations. We present Route-DETR, which addresses these issues through adaptive pairwise routing in decoder self-attention layers. Our key insight is distinguishing between competing queries (targeting the same object) versus complementary queries (targeting different objects) using inter-query similarity, confidence scores, and geometry. We introduce dual routing mechanisms: suppressor routes that modulate attention between competing queries to reduce duplication, and delegator routes that encourage exploration of different regions. These are implemented via learnable low-rank attention biases enabling asymmetric query interactions. A dual-branch training strategy incorporates routing biases only during training while preserving standard attention for inference, ensuring no additional computational cost. Experiments on COCO and Cityscapes demonstrate consistent improvements across multiple DETR baselines, achieving +1.7% mAP gain over DINO on ResNet-50 and reaching 57.6% mAP on Swin-L, surpassing prior state-of-the-art models.
Exploring the Vulnerability of the Content Moderation Guardrail in Large Language Models via Intent Manipulation
May 24, 2025Intent detection, a core component of natural language understanding, has considerably evolved as a crucial mechanism in safeguarding large language models (LLMs). While prior work has applied intent detection to enhance LLMs' moderation guardrails, showing a significant success against content-level jailbreaks, the robustness of these intent-aware guardrails under malicious manipulations remains under-explored. In this work, we investigate the vulnerability of intent-aware guardrails and demonstrate that LLMs exhibit implicit intent detection capabilities. We propose a two-stage intent-based prompt-refinement framework, IntentPrompt, that first transforms harmful inquiries into structured outlines and further reframes them into declarative-style narratives by iteratively optimizing prompts via feedback loops to enhance jailbreak success for red-teaming purposes. Extensive experiments across four public benchmarks and various black-box LLMs indicate that our framework consistently outperforms several cutting-edge jailbreak methods and evades even advanced Intent Analysis (IA) and Chain-of-Thought (CoT)-based defenses. Specifically, our "FSTR+SPIN" variant achieves attack success rates ranging from 88.25% to 96.54% against CoT-based defenses on the o1 model, and from 86.75% to 97.12% on the GPT-4o model under IA-based defenses. These findings highlight a critical weakness in LLMs' safety mechanisms and suggest that intent manipulation poses a growing challenge to content moderation guardrails.
LP-DETR: Layer-wise Progressive Relations for Object Detection
Feb 07, 2025



This paper presents LP-DETR (Layer-wise Progressive DETR), a novel approach that enhances DETR-based object detection through multi-scale relation modeling. Our method introduces learnable spatial relationships between object queries through a relation-aware self-attention mechanism, which adaptively learns to balance different scales of relations (local, medium and global) across decoder layers. This progressive design enables the model to effectively capture evolving spatial dependencies throughout the detection pipeline. Extensive experiments on COCO 2017 dataset demonstrate that our method improves both convergence speed and detection accuracy compared to standard self-attention module. The proposed method achieves competitive results, reaching 52.3\% AP with 12 epochs and 52.5\% AP with 24 epochs using ResNet-50 backbone, and further improving to 58.0\% AP with Swin-L backbone. Furthermore, our analysis reveals an interesting pattern: the model naturally learns to prioritize local spatial relations in early decoder layers while gradually shifting attention to broader contexts in deeper layers, providing valuable insights for future research in object detection.
ChallengeMe: An Adversarial Learning-enabled Text Summarization Framework
Feb 07, 2025The astonishing performance of large language models (LLMs) and their remarkable achievements in production and daily life have led to their widespread application in collaborative tasks. However, current large models face challenges such as hallucination and lack of specificity in content generation in vertical domain tasks. Inspired by the contrast and classification mechanisms in human cognitive processes, this paper constructs an adversarial learning-based prompt framework named ChallengeMe, which includes three cascaded solutions: generation prompts, evaluation prompts, and feedback optimization. In this process, we designed seven core optimization dimensions and set the threshold for adversarial learning. The results of mixed case studies on the text summarization task show that the proposed framework can generate more accurate and fluent text summaries compared to the current advanced mainstream LLMs.
Optimized Coordination Strategy for Multi-Aerospace Systems in Pick-and-Place Tasks By Deep Neural Network
Dec 13, 2024In this paper, we present an advanced strategy for the coordinated control of a multi-agent aerospace system, utilizing Deep Neural Networks (DNNs) within a reinforcement learning framework. Our approach centers on optimizing autonomous task assignment to enhance the system's operational efficiency in object relocation tasks, framed as an aerospace-oriented pick-and-place scenario. By modeling this coordination challenge within a MuJoCo environment, we employ a deep reinforcement learning algorithm to train a DNN-based policy to maximize task completion rates across the multi-agent system. The objective function is explicitly designed to maximize effective object transfer rates, leveraging neural network capabilities to handle complex state and action spaces in high-dimensional aerospace environments. Through extensive simulation, we benchmark the proposed method against a heuristic combinatorial approach rooted in game-theoretic principles, demonstrating a marked performance improvement, with the trained policy achieving up to 16\% higher task efficiency. Experimental validation is conducted on a multi-agent hardware setup to substantiate the efficacy of our approach in a real-world aerospace scenario.
CoVis: A Collaborative Framework for Fine-grained Graphic Visual Understanding
Nov 27, 2024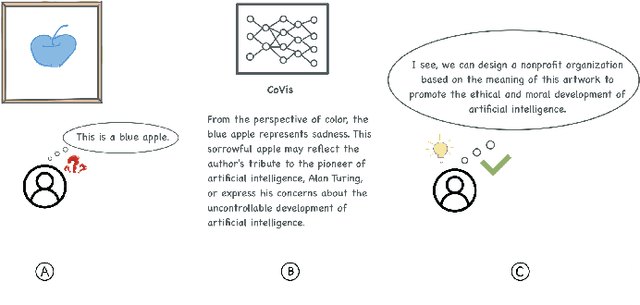
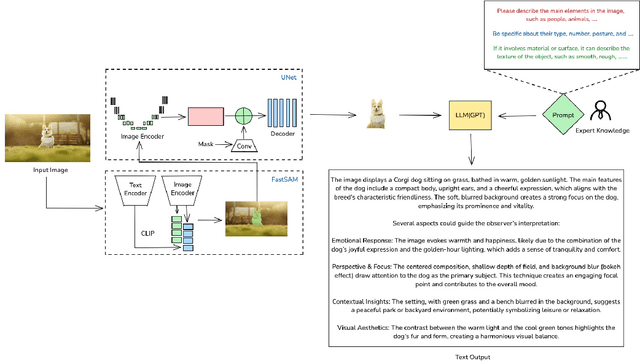
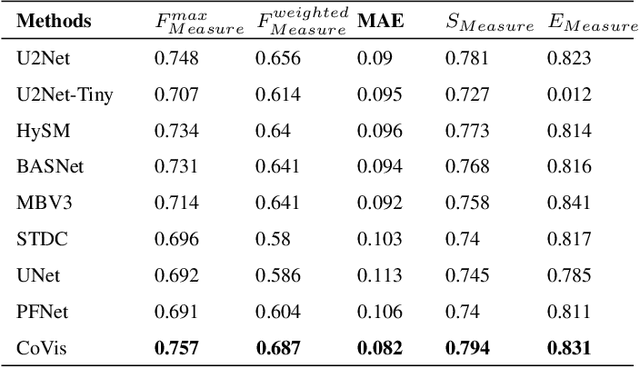

Graphic visual content helps in promoting information communication and inspiration divergence. However, the interpretation of visual content currently relies mainly on humans' personal knowledge background, thereby affecting the quality and efficiency of information acquisition and understanding. To improve the quality and efficiency of visual information transmission and avoid the limitation of the observer due to the information cocoon, we propose CoVis, a collaborative framework for fine-grained visual understanding. By designing and implementing a cascaded dual-layer segmentation network coupled with a large-language-model (LLM) based content generator, the framework extracts as much knowledge as possible from an image. Then, it generates visual analytics for images, assisting observers in comprehending imagery from a more holistic perspective. Quantitative experiments and qualitative experiments based on 32 human participants indicate that the CoVis has better performance than current methods in feature extraction and can generate more comprehensive and detailed visual descriptions than current general-purpose large models.