 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoVis: A Collaborative Framework for Fine-grained Graphic Visual Understanding
Paper and Code
Nov 27, 2024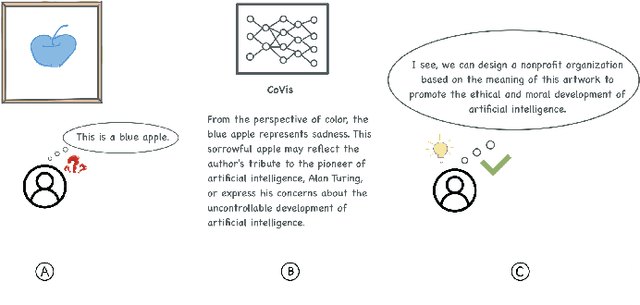
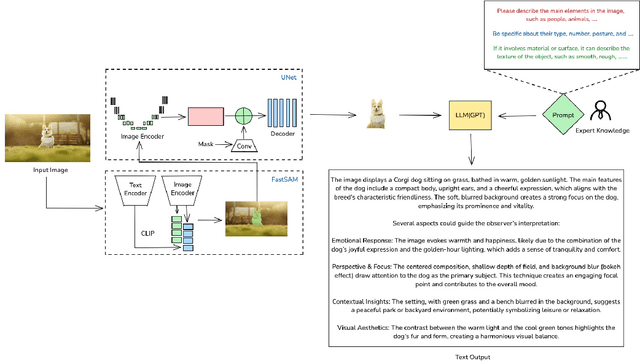
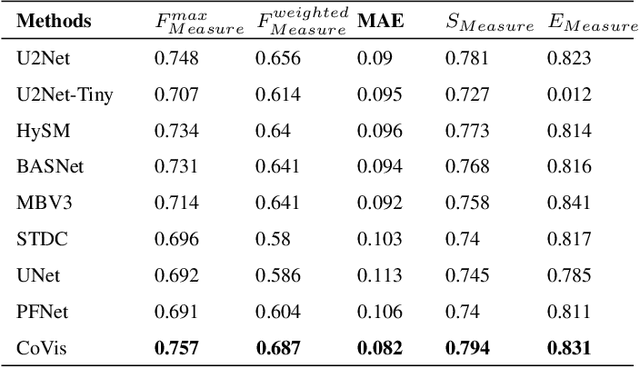

Graphic visual content helps in promoting information communication and inspiration divergence. However, the interpretation of visual content currently relies mainly on humans' personal knowledge background, thereby affecting the quality and efficiency of information acquisition and understanding. To improve the quality and efficiency of visual information transmission and avoid the limitation of the observer due to the information cocoon, we propose CoVis, a collaborative framework for fine-grained visual understanding. By designing and implementing a cascaded dual-layer segmentation network coupled with a large-language-model (LLM) based content generator, the framework extracts as much knowledge as possible from an image. Then, it generates visual analytics for images, assisting observers in comprehending imagery from a more holistic perspective. Quantitative experiments and qualitative experiments based on 32 human participants indicate that the CoVis has better performance than current methods in feature extraction and can generate more comprehensive and detailed visual descriptions than current general-purpose large models.