 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChallengeMe: An Adversarial Learning-enabled Text Summarization Framework
Feb 07, 2025The astonishing performance of large language models (LLMs) and their remarkable achievements in production and daily life have led to their widespread application in collaborative tasks. However, current large models face challenges such as hallucination and lack of specificity in content generation in vertical domain tasks. Inspired by the contrast and classification mechanisms in human cognitive processes, this paper constructs an adversarial learning-based prompt framework named ChallengeMe, which includes three cascaded solutions: generation prompts, evaluation prompts, and feedback optimization. In this process, we designed seven core optimization dimensions and set the threshold for adversarial learning. The results of mixed case studies on the text summarization task show that the proposed framework can generate more accurate and fluent text summaries compared to the current advanced mainstream LLMs.
CoVis: A Collaborative Framework for Fine-grained Graphic Visual Understanding
Nov 27, 2024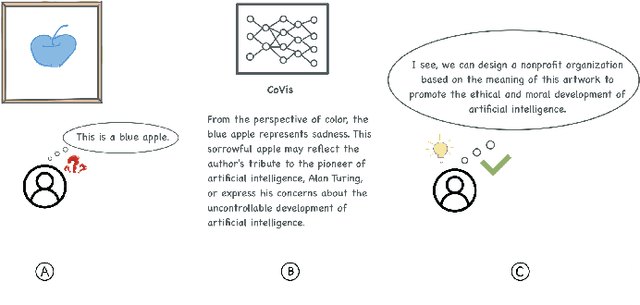
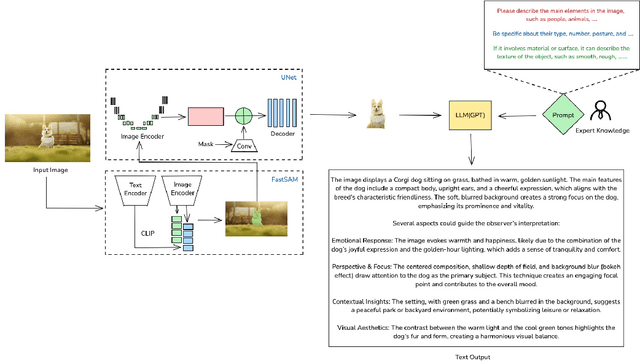
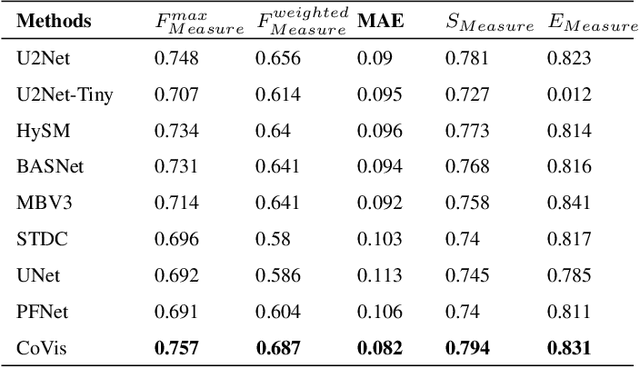

Graphic visual content helps in promoting information communication and inspiration divergence. However, the interpretation of visual content currently relies mainly on humans' personal knowledge background, thereby affecting the quality and efficiency of information acquisition and understanding. To improve the quality and efficiency of visual information transmission and avoid the limitation of the observer due to the information cocoon, we propose CoVis, a collaborative framework for fine-grained visual understanding. By designing and implementing a cascaded dual-layer segmentation network coupled with a large-language-model (LLM) based content generator, the framework extracts as much knowledge as possible from an image. Then, it generates visual analytics for images, assisting observers in comprehending imagery from a more holistic perspective. Quantitative experiments and qualitative experiments based on 32 human participants indicate that the CoVis has better performance than current methods in feature extraction and can generate more comprehensive and detailed visual descriptions than current general-purpose large models.