 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLipGen: Viseme-Guided Lip Video Generation for Enhancing Visual Speech Recognition
Jan 08, 2025



Visual speech recognition (VSR), commonly known as lip reading, has garnered significant attention due to its wide-ranging practical applications. The advent of deep learning techniques and advancements in hardware capabilities have significantly enhanced the performance of lip reading models. Despite these advancements, existing datasets predominantly feature stable video recordings with limited variability in lip movements. This limitation results in models that are highly sensitive to variations encountered in real-world scenarios. To address this issue, we propose a novel framework, LipGen, which aims to improve model robustness by leveraging speech-driven synthetic visual data, thereby mitigating the constraints of current datasets. Additionally, we introduce an auxiliary task that incorporates viseme classification alongside attention mechanisms. This approach facilitates the efficient integration of temporal information, directing the model's focus toward the relevant segments of speech, thereby enhancing discriminative capabilities. Our method demonstrates superior performance compared to the current state-of-the-art on the lip reading in the wild (LRW) dataset and exhibits even more pronounced advantages under challenging conditions.
Motif-Based Prompt Learning for Universal Cross-Domain Recommendation
Oct 20, 2023



Cross-Domain Recommendation (CDR) stands as a pivotal technology addressing issues of data sparsity and cold start by transferring general knowledge from the source to the target domain. However, existing CDR models suffer limitations in adaptability across various scenarios due to their inherent complexity. To tackle this challenge, recent advancements introduce universal CDR models that leverage shared embeddings to capture general knowledge across domains and transfer it through "Multi-task Learning" or "Pre-train, Fine-tune" paradigms. However, these models often overlook the broader structural topology that spans domains and fail to align training objectives, potentially leading to negative transfer. To address these issues, we propose a motif-based prompt learning framework, MOP, which introduces motif-based shared embeddings to encapsulate generalized domain knowledge, catering to both intra-domain and inter-domain CDR tasks. Specifically, we devise three typical motifs: butterfly, triangle, and random walk, and encode them through a Motif-based Encoder to obtain motif-based shared embeddings. Moreover, we train MOP under the "Pre-training \& Prompt Tuning" paradigm. By unifying pre-training and recommendation tasks as a common motif-based similarity learning task and integrating adaptable prompt parameters to guide the model in downstream recommendation tasks, MOP excels in transferring domain knowledge effectively. Experimental results on four distinct CDR tasks demonstrate the effectiveness of MOP than the state-of-the-art models.
A Multi-Strategy based Pre-Training Method for Cold-Start Recommendation
Dec 04, 2021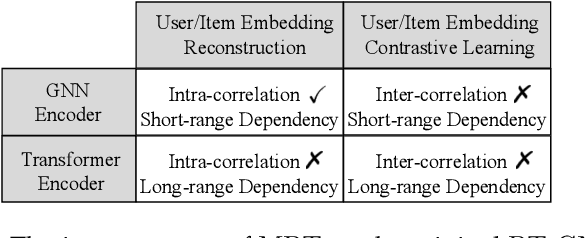
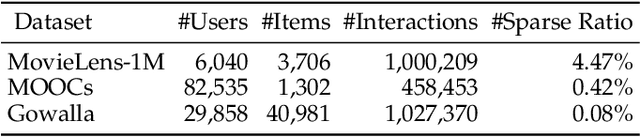
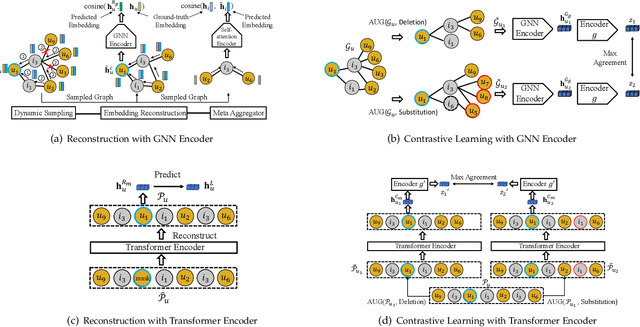
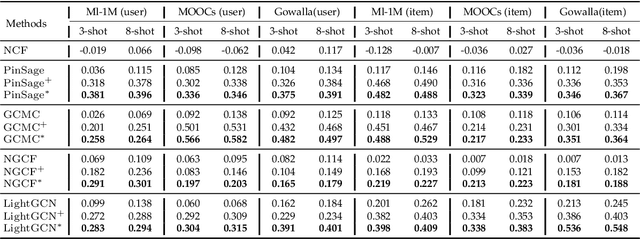
Cold-start problem is a fundamental challenge for recommendation tasks. The recent self-supervised learning (SSL) on Graph Neural Networks (GNNs) model, PT-GNN, pre-trains the GNN model to reconstruct the cold-start embeddings and has shown great potential for cold-start recommendation. However, due to the over-smoothing problem, PT-GNN can only capture up to 3-order relation, which can not provide much useful auxiliary information to depict the target cold-start user or item. Besides, the embedding reconstruction task only considers the intra-correlations within the subgraph of users and items, while ignoring the inter-correlations across different subgraphs. To solve the above challenges, we propose a multi-strategy based pre-training method for cold-start recommendation (MPT), which extends PT-GNN from the perspective of model architecture and pretext tasks to improve the cold-start recommendation performance. Specifically, in terms of the model architecture, in addition to the short-range dependencies of users and items captured by the GNN encoder, we introduce a Transformer encoder to capture long-range dependencies. In terms of the pretext task, in addition to considering the intra-correlations of users and items by the embedding reconstruction task, we add embedding contrastive learning task to capture inter-correlations of users and items. We train the GNN and Transformer encoders on these pretext tasks under the meta-learning setting to simulate the real cold-start scenario, making the model easily and rapidly being adapted to new cold-start users and items. Experiments on three public recommendation datasets show the superiority of the proposed MPT model against the vanilla GNN models, the pre-training GNN model on user/item embedding inference and the recommendation task.
Self-supervised Graph Learning for Occasional Group Recommendation
Dec 04, 2021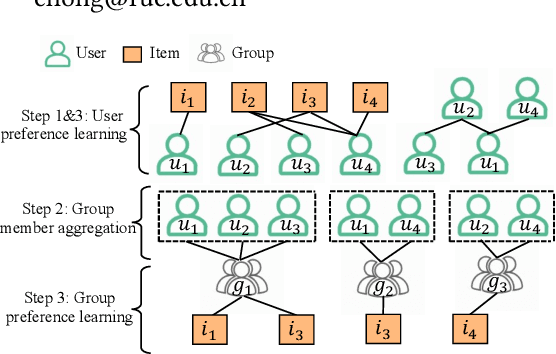
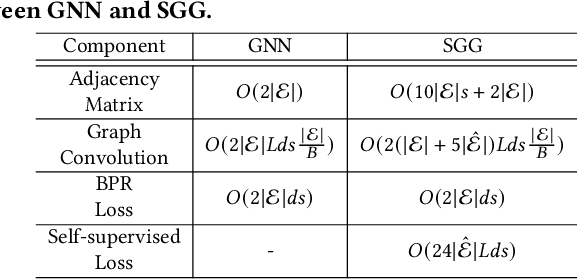
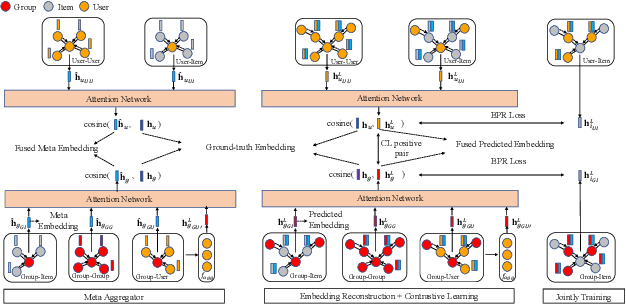
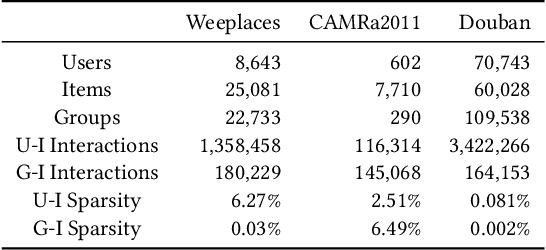
We study the problem of recommending items to occasional groups (a.k.a. cold-start groups), where the occasional groups are formed ad-hoc and have few or no historical interacted items. Due to the extreme sparsity issue of the occasional groups' interactions with items, it is difficult to learn high-quality embeddings for these occasional groups. Despite the recent advances on Graph Neural Networks (GNNs) incorporate high-order collaborative signals to alleviate the problem, the high-order cold-start neighbors are not explicitly considered during the graph convolution in GNNs. This paper proposes a self-supervised graph learning paradigm, which jointly trains the backbone GNN model to reconstruct the group/user/item embeddings under the meta-learning setting, such that it can directly improve the embedding quality and can be easily adapted to the new occasional groups. To further reduce the impact from the cold-start neighbors, we incorporate a self-attention-based meta aggregator to enhance the aggregation ability of each graph convolution step. Besides, we add a contrastive learning (CL) adapter to explicitly consider the correlations between the group and non-group members. Experimental results on three public recommendation datasets show the superiority of our proposed model against the state-of-the-art group recommendation methods.
Recommending Courses in MOOCs for Jobs: An Auto Weak Supervision Approach
Dec 28, 2020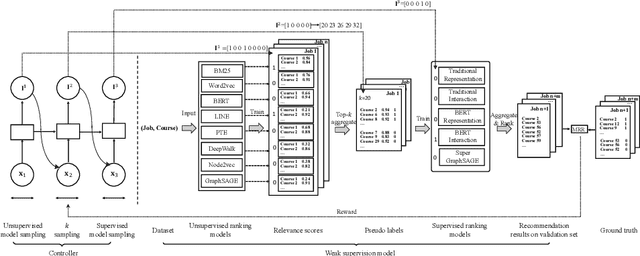
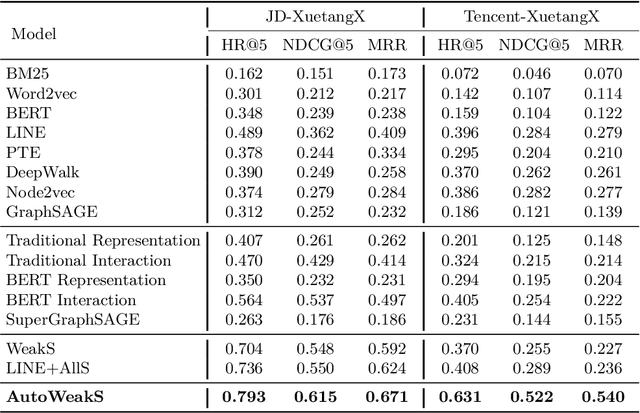
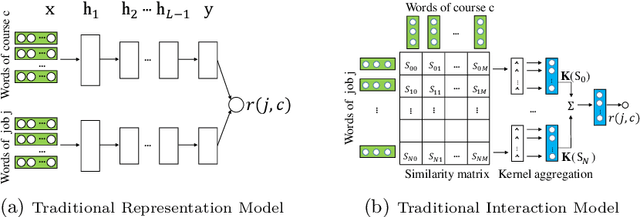
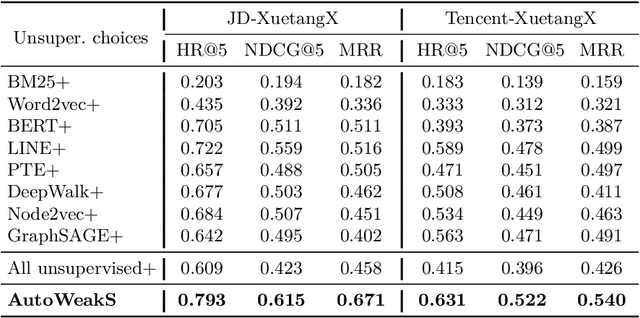
The proliferation of massive open online courses (MOOCs) demands an effective way of course recommendation for jobs posted in recruitment websites, especially for the people who take MOOCs to find new jobs. Despite the advances of supervised ranking models, the lack of enough supervised signals prevents us from directly learning a supervised ranking model. This paper proposes a general automated weak supervision framework AutoWeakS via reinforcement learning to solve the problem. On the one hand, the framework enables training multiple supervised ranking models upon the pseudo labels produced by multiple unsupervised ranking models. On the other hand, the framework enables automatically searching the optimal combination of these supervised and unsupervised models. Systematically, we evaluate the proposed model on several datasets of jobs from different recruitment websites and courses from a MOOCs platform. Experiments show that our model significantly outperforms the classical unsupervised, supervised and weak supervision baselines.