 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial-VLN: Zero-Shot Vision-and-Language Navigation With Explicit Spatial Perception and Exploration
Jan 19, 2026Zero-shot Vision-and-Language Navigation (VLN) agents leveraging Large Language Models (LLMs) excel in generalization but suffer from insufficient spatial perception. Focusing on complex continuous environments, we categorize key perceptual bottlenecks into three spatial challenges: door interaction,multi-room navigation, and ambiguous instruction execution, where existing methods consistently suffer high failure rates. We present Spatial-VLN, a perception-guided exploration framework designed to overcome these challenges. The framework consists of two main modules. The Spatial Perception Enhancement (SPE) module integrates panoramic filtering with specialized door and region experts to produce spatially coherent, cross-view consistent perceptual representations. Building on this foundation, our Explored Multi-expert Reasoning (EMR) module uses parallel LLM experts to address waypoint-level semantics and region-level spatial transitions. When discrepancies arise between expert predictions, a query-and-explore mechanism is activated, prompting the agent to actively probe critical areas and resolve perceptual ambiguities. Experiments on VLN-CE demonstrate that Spatial VLN achieves state-of-the-art performance using only low-cost LLMs. Furthermore, to validate real-world applicability, we introduce a value-based waypoint sampling strategy that effectively bridges the Sim2Real gap. Extensive real-world evaluations confirm that our framework delivers superior generalization and robustness in complex environments. Our codes and videos are available at https://yueluhhxx.github.io/Spatial-VLN-web/.
ST-Booster: An Iterative SpatioTemporal Perception Booster for Vision-and-Language Navigation in Continuous Environments
Apr 14, 2025Vision-and-Language Navigation in Continuous Environments (VLN-CE) requires agents to navigate unknown, continuous spaces based on natural language instructions. Compared to discrete settings, VLN-CE poses two core perception challenges. First, the absence of predefined observation points leads to heterogeneous visual memories and weakened global spatial correlations. Second, cumulative reconstruction errors in three-dimensional scenes introduce structural noise, impairing local feature perception. To address these challenges, this paper proposes ST-Booster, an iterative spatiotemporal booster that enhances navigation performance through multi-granularity perception and instruction-aware reasoning. ST-Booster consists of three key modules -- Hierarchical SpatioTemporal Encoding (HSTE), Multi-Granularity Aligned Fusion (MGAF), and ValueGuided Waypoint Generation (VGWG). HSTE encodes long-term global memory using topological graphs and captures shortterm local details via grid maps. MGAF aligns these dualmap representations with instructions through geometry-aware knowledge fusion. The resulting representations are iteratively refined through pretraining tasks. During reasoning, VGWG generates Guided Attention Heatmaps (GAHs) to explicitly model environment-instruction relevance and optimize waypoint selection. Extensive comparative experiments and performance analyses are conducted, demonstrating that ST-Booster outperforms existing state-of-the-art methods, particularly in complex, disturbance-prone environments.
Safe-VLN: Collision Avoidance for Vision-and-Language Navigation of Autonomous Robots Operating in Continuous Environments
Nov 06, 2023
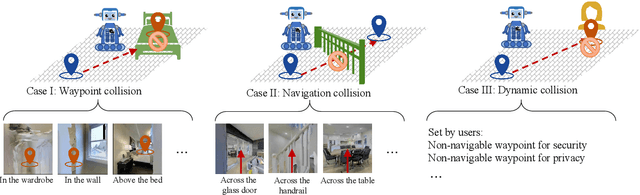
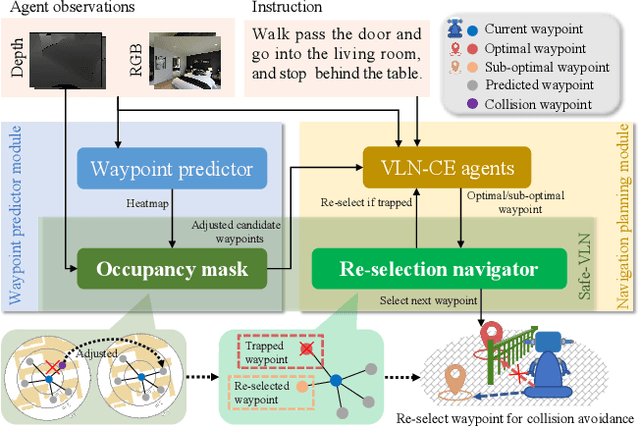

The task of vision-and-language navigation in continuous environments (VLN-CE) aims at training an autonomous agent to perform low-level actions to navigate through 3D continuous surroundings using visual observations and language instructions. The significant potential of VLN-CE for mobile robots has been demonstrated across a large number of studies. However, most existing works in VLN-CE focus primarily on transferring the standard discrete vision-and-language navigation (VLN) methods to continuous environments, overlooking the problem of collisions. Such oversight often results in the agent deviating from the planned path or, in severe instances, the agent being trapped in obstacle areas and failing the navigational task. To address the above-mentioned issues, this paper investigates various collision scenarios within VLN-CE and proposes a classification method to predicate the underlying causes of collisions. Furthermore, a new VLN-CE algorithm, named Safe-VLN, is proposed to bolster collision avoidance capabilities including two key components, i.e., a waypoint predictor and a navigator. In particular, the waypoint predictor leverages a simulated 2D LiDAR occupancy mask to prevent the predicted waypoints from being situated in obstacle-ridden areas. The navigator, on the other hand, employs the strategy of `re-selection after collision' to prevent the robot agent from becoming ensnared in a cycle of perpetual collisions. The proposed Safe-VLN is evaluated on the R2R-CE, the results of which demonstrate an enhanced navigational performance and a statistically significant reduction in collision incidences.