 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge6G Network Business Support System
Jul 19, 2023



6G is the next-generation intelligent and integrated digital information infrastructure, characterized by ubiquitous interconnection, native intelligence, multi-dimensional perception, global coverage, green and low-carbon, native network security, etc. 6G will realize the transition from serving people and people-things communication to supporting the efficient connection of intelligent agents, and comprehensively leading the digital, intelligent and green transformation of the economy and the society. As the core support system for mobile communication network, 6 6G BSS need to integrate with new business models brought about by the development of the next-generation Internet and IT, upgrade from "network-centric" to "business and service centric" and "customer-centric". 6G OSS and BSS systems need to strengthen their integration to improve the operational efficiency and benefits of customers by connecting the digital intelligence support capabilities on both sides of supply and demand. This paper provides a detailed introduction to the overall vision, potential key technologies, and functional architecture of 6G BSS systems. It also presents an evolutionary roadmap and technological prospects for the BSS systems from 5G to 6G.
PENet: Towards Precise and Efficient Image Guided Depth Completion
Mar 18, 2021
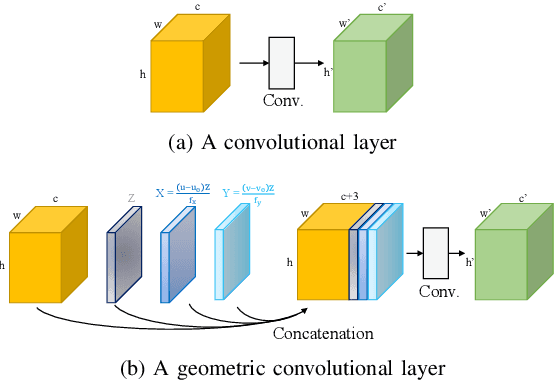

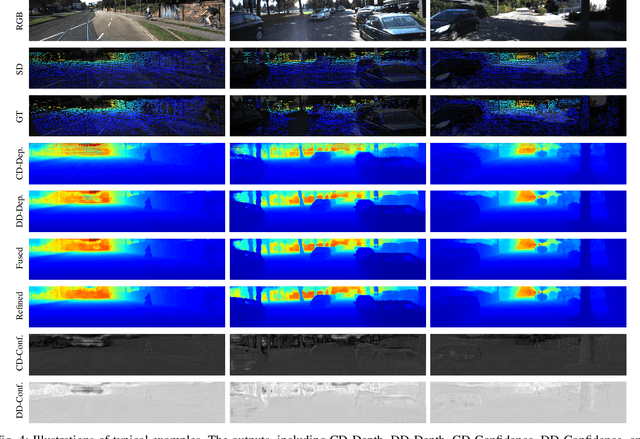
Image guided depth completion is the task of generating a dense depth map from a sparse depth map and a high quality image. In this task, how to fuse the color and depth modalities plays an important role in achieving good performance. This paper proposes a two-branch backbone that consists of a color-dominant branch and a depth-dominant branch to exploit and fuse two modalities thoroughly. More specifically, one branch inputs a color image and a sparse depth map to predict a dense depth map. The other branch takes as inputs the sparse depth map and the previously predicted depth map, and outputs a dense depth map as well. The depth maps predicted from two branches are complimentary to each other and therefore they are adaptively fused. In addition, we also propose a simple geometric convolutional layer to encode 3D geometric cues. The geometric encoded backbone conducts the fusion of different modalities at multiple stages, leading to good depth completion results. We further implement a dilated and accelerated CSPN++ to refine the fused depth map efficiently. The proposed full model ranks 1st in the KITTI depth completion online leaderboard at the time of submission. It also infers much faster than most of the top ranked methods. The code of this work is available at https://github.com/JUGGHM/PENet_ICRA2021.
Self-supervised Visual-LiDAR Odometry with Flip Consistency
Jan 05, 2021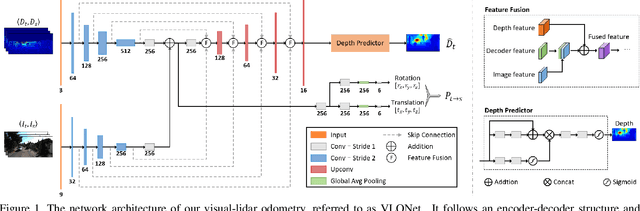



Most learning-based methods estimate ego-motion by utilizing visual sensors, which suffer from dramatic lighting variations and textureless scenarios. In this paper, we incorporate sparse but accurate depth measurements obtained from lidars to overcome the limitation of visual methods. To this end, we design a self-supervised visual-lidar odometry (Self-VLO) framework. It takes both monocular images and sparse depth maps projected from 3D lidar points as input, and produces pose and depth estimations in an end-to-end learning manner, without using any ground truth labels. To effectively fuse two modalities, we design a two-pathway encoder to extract features from visual and depth images and fuse the encoded features with those in decoders at multiple scales by our fusion module. We also adopt a siamese architecture and design an adaptively weighted flip consistency loss to facilitate the self-supervised learning of our VLO. Experiments on the KITTI odometry benchmark show that the proposed approach outperforms all self-supervised visual or lidar odometries. It also performs better than fully supervised VOs, demonstrating the power of fusion.