 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Token Compression for Vision Transformer with Spatial Information Preserved
Mar 30, 2025



Token compression is essential for reducing the computational and memory requirements of transformer models, enabling their deployment in resource-constrained environments. In this work, we propose an efficient and hardware-compatible token compression method called Prune and Merge. Our approach integrates token pruning and merging operations within transformer models to achieve layer-wise token compression. By introducing trainable merge and reconstruct matrices and utilizing shortcut connections, we efficiently merge tokens while preserving important information and enabling the restoration of pruned tokens. Additionally, we introduce a novel gradient-weighted attention scoring mechanism that computes token importance scores during the training phase, eliminating the need for separate computations during inference and enhancing compression efficiency. We also leverage gradient information to capture the global impact of tokens and automatically identify optimal compression structures. Extensive experiments on the ImageNet-1k and ADE20K datasets validate the effectiveness of our approach, achieving significant speed-ups with minimal accuracy degradation compared to state-of-the-art methods. For instance, on DeiT-Small, we achieve a 1.64$\times$ speed-up with only a 0.2\% drop in accuracy on ImageNet-1k. Moreover, by compressing segmenter models and comparing with existing methods, we demonstrate the superior performance of our approach in terms of efficiency and effectiveness. Code and models have been made available at https://github.com/NUST-Machine-Intelligence-Laboratory/prune_and_merge.
Attention Map Guided Transformer Pruning for Edge Device
Apr 04, 2023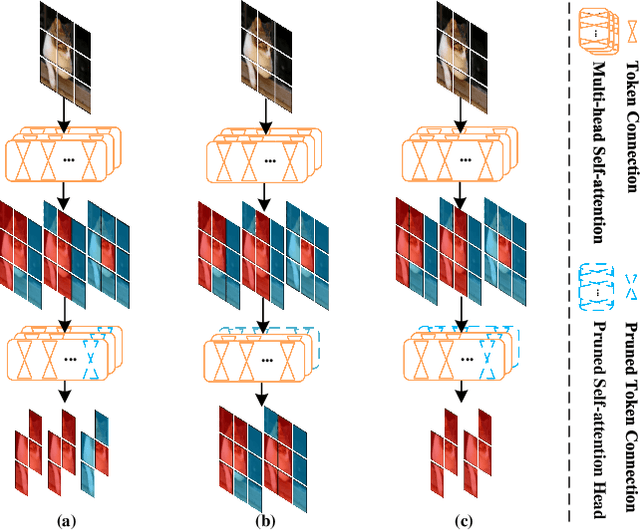
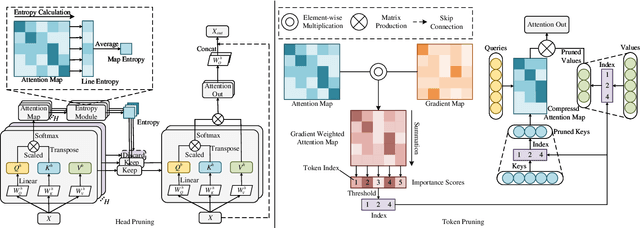
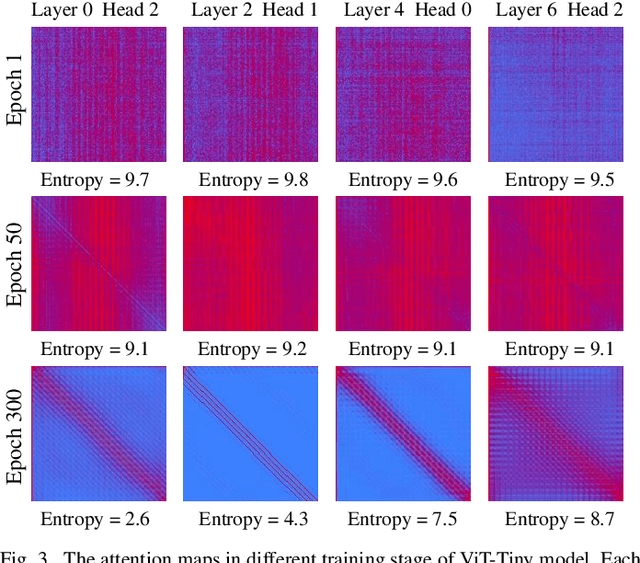
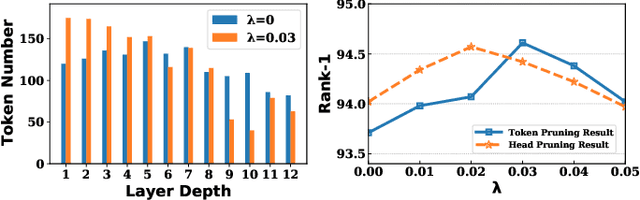
Due to its significant capability of modeling long-range dependencies, vision transformer (ViT) has achieved promising success in both holistic and occluded person re-identification (Re-ID) tasks. However, the inherent problems of transformers such as the huge computational cost and memory footprint are still two unsolved issues that will block the deployment of ViT based person Re-ID models on resource-limited edge devices. Our goal is to reduce both the inference complexity and model size without sacrificing the comparable accuracy on person Re-ID, especially for tasks with occlusion. To this end, we propose a novel attention map guided (AMG) transformer pruning method, which removes both redundant tokens and heads with the guidance of the attention map in a hardware-friendly way. We first calculate the entropy in the key dimension and sum it up for the whole map, and the corresponding head parameters of maps with high entropy will be removed for model size reduction. Then we combine the similarity and first-order gradients of key tokens along the query dimension for token importance estimation and remove redundant key and value tokens to further reduce the inference complexity. Comprehensive experiments on Occluded DukeMTMC and Market-1501 demonstrate the effectiveness of our proposals. For example, our proposed pruning strategy on ViT-Base enjoys \textup{\textbf{29.4\%}} \textup{\textbf{FLOPs}} savings with \textup{\textbf{0.2\%}} drop on Rank-1 and \textup{\textbf{0.4\%}} improvement on mAP, respectively.