 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMM-RS: A Multi-modal, Multi-GSD, Multi-scene Remote Sensing Dataset and Benchmark for Text-to-Image Generation
Oct 26, 2024



Recently, the diffusion-based generative paradigm has achieved impressive general image generation capabilities with text prompts due to its accurate distribution modeling and stable training process. However, generating diverse remote sensing (RS) images that are tremendously different from general images in terms of scale and perspective remains a formidable challenge due to the lack of a comprehensive remote sensing image generation dataset with various modalities, ground sample distances (GSD), and scenes. In this paper, we propose a Multi-modal, Multi-GSD, Multi-scene Remote Sensing (MMM-RS) dataset and benchmark for text-to-image generation in diverse remote sensing scenarios. Specifically, we first collect nine publicly available RS datasets and conduct standardization for all samples. To bridge RS images to textual semantic information, we utilize a large-scale pretrained vision-language model to automatically output text prompts and perform hand-crafted rectification, resulting in information-rich text-image pairs (including multi-modal images). In particular, we design some methods to obtain the images with different GSD and various environments (e.g., low-light, foggy) in a single sample. With extensive manual screening and refining annotations, we ultimately obtain a MMM-RS dataset that comprises approximately 2.1 million text-image pairs. Extensive experimental results verify that our proposed MMM-RS dataset allows off-the-shelf diffusion models to generate diverse RS images across various modalities, scenes, weather conditions, and GSD. The dataset is available at https://github.com/ljl5261/MMM-RS.
Multi-clue Consistency Learning to Bridge Gaps Between General and Oriented Object in Semi-supervised Detection
Jul 08, 2024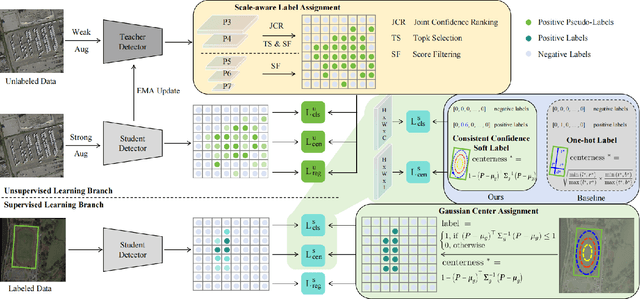
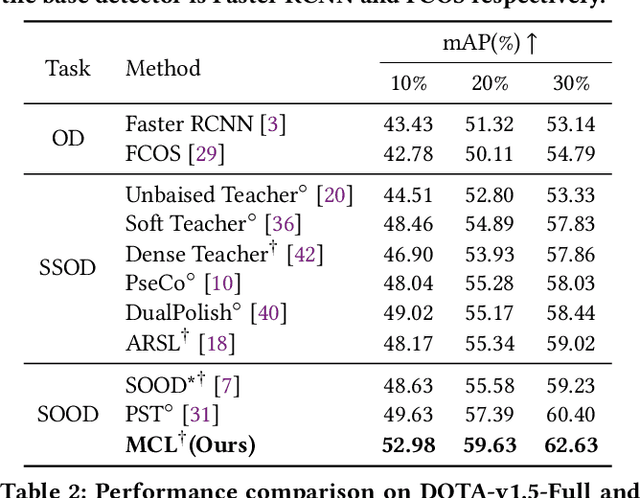
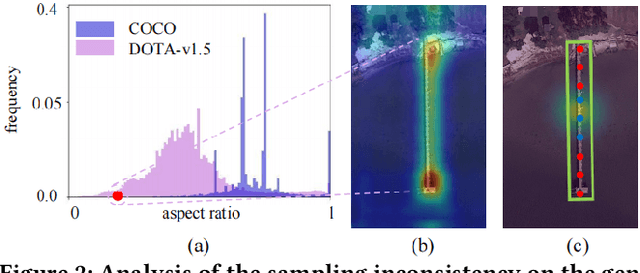

While existing semi-supervised object detection (SSOD) methods perform well in general scenes, they encounter challenges in handling oriented objects in aerial images. We experimentally find three gaps between general and oriented object detection in semi-supervised learning: 1) Sampling inconsistency: the common center sampling is not suitable for oriented objects with larger aspect ratios when selecting positive labels from labeled data. 2) Assignment inconsistency: balancing the precision and localization quality of oriented pseudo-boxes poses greater challenges which introduces more noise when selecting positive labels from unlabeled data. 3) Confidence inconsistency: there exists more mismatch between the predicted classification and localization qualities when considering oriented objects, affecting the selection of pseudo-labels. Therefore, we propose a Multi-clue Consistency Learning (MCL) framework to bridge gaps between general and oriented objects in semi-supervised detection. Specifically, considering various shapes of rotated objects, the Gaussian Center Assignment is specially designed to select the pixel-level positive labels from labeled data. We then introduce the Scale-aware Label Assignment to select pixel-level pseudo-labels instead of unreliable pseudo-boxes, which is a divide-and-rule strategy suited for objects with various scales. The Consistent Confidence Soft Label is adopted to further boost the detector by maintaining the alignment of the predicted results. Comprehensive experiments on DOTA-v1.5 and DOTA-v1.0 benchmarks demonstrate that our proposed MCL can achieve state-of-the-art performance in the semi-supervised oriented object detection task.
Big-model Driven Few-shot Continual Learning
Sep 02, 2023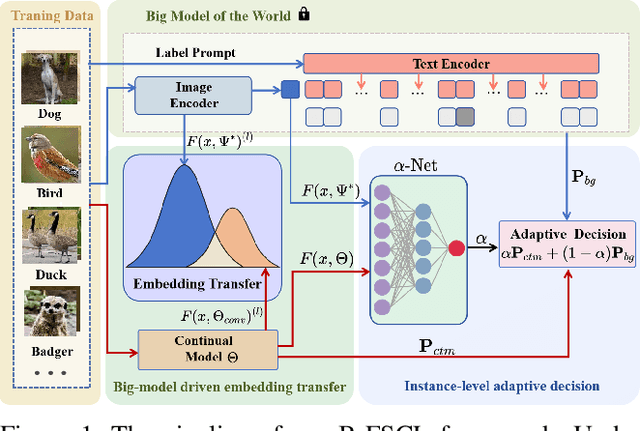
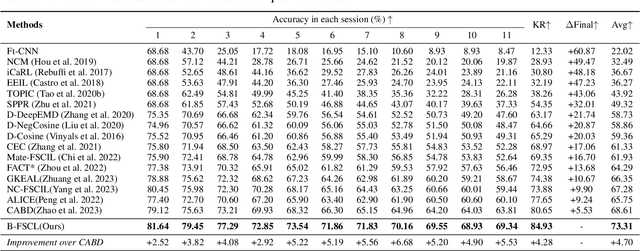
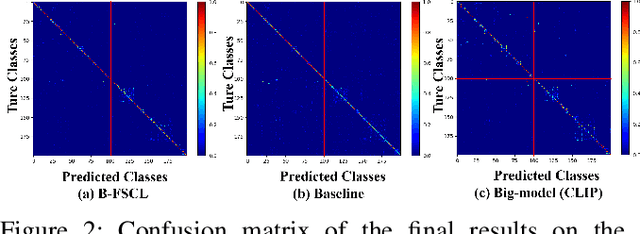
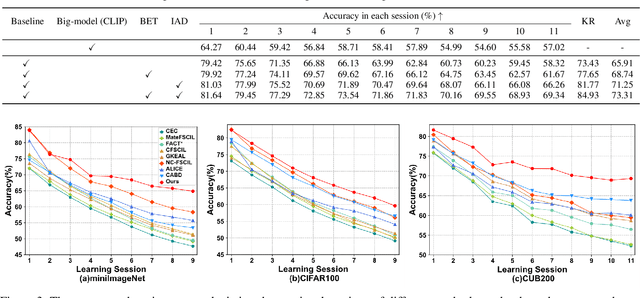
Few-shot continual learning (FSCL) has attracted intensive attention and achieved some advances in recent years, but now it is difficult to again make a big stride in accuracy due to the limitation of only few-shot incremental samples. Inspired by distinctive human cognition ability in life learning, in this work, we propose a novel Big-model driven Few-shot Continual Learning (B-FSCL) framework to gradually evolve the model under the traction of the world's big-models (like human accumulative knowledge). Specifically, we perform the big-model driven transfer learning to leverage the powerful encoding capability of these existing big-models, which can adapt the continual model to a few of newly added samples while avoiding the over-fitting problem. Considering that the big-model and the continual model may have different perceived results for the identical images, we introduce an instance-level adaptive decision mechanism to provide the high-level flexibility cognitive support adjusted to varying samples. In turn, the adaptive decision can be further adopted to optimize the parameters of the continual model, performing the adaptive distillation of big-model's knowledge information. Experimental results of our proposed B-FSCL on three popular datasets (including CIFAR100, minilmageNet and CUB200) completely surpass all state-of-the-art FSCL methods.