 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASGNet: Adaptive Spectrum Guidance Network for Automatic Polyp Segmentation
Apr 16, 2026Early identification and removal of polyps can reduce the risk of developing colorectal cancer. However, the diverse morphologies, complex backgrounds and often concealed nature of polyps make polyp segmentation in colonoscopy images highly challenging. Despite the promising performance of existing deep learning-based polyp segmentation methods, their perceptual capabilities remain biased toward local regions, mainly because of the strong spatial correlations between neighboring pixels in the spatial domain. This limitation makes it difficult to capture the complete polyp structures, ultimately leading to sub-optimal segmentation results. In this paper, we propose a novel adaptive spectrum guidance network, called ASGNet, which addresses the limitations of spatial perception by integrating spectral features with global attributes. Specifically, we first design a spectrum-guided non-local perception module that jointly aggregates local and global information, therefore enhancing the discriminability of polyp structures, and refining their boundaries. Moreover, we introduce a multi-source semantic extractor that integrates rich high-level semantic information to assist in the preliminary localization of polyps. Furthermore, we construct a dense cross-layer interaction decoder that effectively integrates diverse information from different layers and strengthens it to generate high-quality representations for accurate polyp segmentation. Extensive quantitative and qualitative results demonstrate the superiority of our ASGNet approach over 21 state-of-the-art methods across five widely-used polyp segmentation benchmarks. The code will be publicly available at: https://github.com/CSYSI/ASGNet.
Small but Mighty: Dynamic Wavelet Expert-Guided Fine-Tuning of Large-Scale Models for Optical Remote Sensing Object Segmentation
Jan 14, 2026Accurately localizing and segmenting relevant objects from optical remote sensing images (ORSIs) is critical for advancing remote sensing applications. Existing methods are typically built upon moderate-scale pre-trained models and employ diverse optimization strategies to achieve promising performance under full-parameter fine-tuning. In fact, deeper and larger-scale foundation models can provide stronger support for performance improvement. However, due to their massive number of parameters, directly adopting full-parameter fine-tuning leads to pronounced training difficulties, such as excessive GPU memory consumption and high computational costs, which result in extremely limited exploration of large-scale models in existing works. In this paper, we propose a novel dynamic wavelet expert-guided fine-tuning paradigm with fewer trainable parameters, dubbed WEFT, which efficiently adapts large-scale foundation models to ORSIs segmentation tasks by leveraging the guidance of wavelet experts. Specifically, we introduce a task-specific wavelet expert extractor to model wavelet experts from different perspectives and dynamically regulate their outputs, thereby generating trainable features enriched with task-specific information for subsequent fine-tuning. Furthermore, we construct an expert-guided conditional adapter that first enhances the fine-grained perception of frozen features for specific tasks by injecting trainable features, and then iteratively updates the information of both types of feature, allowing for efficient fine-tuning. Extensive experiments show that our WEFT not only outperforms 21 state-of-the-art (SOTA) methods on three ORSIs datasets, but also achieves optimal results in camouflage, natural, and medical scenarios. The source code is available at: https://github.com/CSYSI/WEFT.
United Domain Cognition Network for Salient Object Detection in Optical Remote Sensing Images
Nov 11, 2024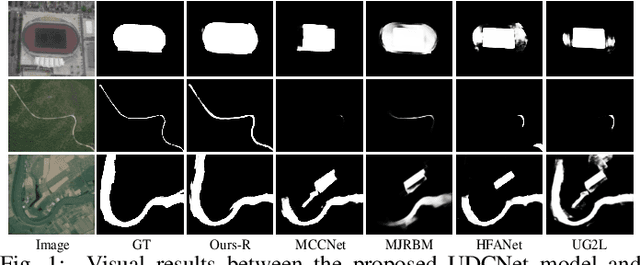



Recently, deep learning-based salient object detection (SOD) in optical remote sensing images (ORSIs) have achieved significant breakthroughs. We observe that existing ORSIs-SOD methods consistently center around optimizing pixel features in the spatial domain, progressively distinguishing between backgrounds and objects. However, pixel information represents local attributes, which are often correlated with their surrounding context. Even with strategies expanding the local region, spatial features remain biased towards local characteristics, lacking the ability of global perception. To address this problem, we introduce the Fourier transform that generate global frequency features and achieve an image-size receptive field. To be specific, we propose a novel United Domain Cognition Network (UDCNet) to jointly explore the global-local information in the frequency and spatial domains. Technically, we first design a frequency-spatial domain transformer block that mutually amalgamates the complementary local spatial and global frequency features to strength the capability of initial input features. Furthermore, a dense semantic excavation module is constructed to capture higher-level semantic for guiding the positioning of remote sensing objects. Finally, we devise a dual-branch joint optimization decoder that applies the saliency and edge branches to generate high-quality representations for predicting salient objects. Experimental results demonstrate the superiority of the proposed UDCNet method over 24 state-of-the-art models, through extensive quantitative and qualitative comparisons in three widely-used ORSIs-SOD datasets. The source code is available at: \href{https://github.com/CSYSI/UDCNet}{\color{blue} https://github.com/CSYSI/UDCNet}.
GLCONet: Learning Multi-source Perception Representation for Camouflaged Object Detection
Sep 15, 2024



Recently, biological perception has been a powerful tool for handling the camouflaged object detection (COD) task. However, most existing methods are heavily dependent on the local spatial information of diverse scales from convolutional operations to optimize initial features. A commonly neglected point in these methods is the long-range dependencies between feature pixels from different scale spaces that can help the model build a global structure of the object, inducing a more precise image representation. In this paper, we propose a novel Global-Local Collaborative Optimization Network, called GLCONet. Technically, we first design a collaborative optimization strategy from the perspective of multi-source perception to simultaneously model the local details and global long-range relationships, which can provide features with abundant discriminative information to boost the accuracy in detecting camouflaged objects. Furthermore, we introduce an adjacent reverse decoder that contains cross-layer aggregation and reverse optimization to integrate complementary information from different levels for generating high-quality representations. Extensive experiments demonstrate that the proposed GLCONet method with different backbones can effectively activate potentially significant pixels in an image, outperforming twenty state-of-the-art methods on three public COD datasets. The source code is available at: \https://github.com/CSYSI/GLCONet.
Frequency-Spatial Entanglement Learning for Camouflaged Object Detection
Sep 03, 2024



Camouflaged object detection has attracted a lot of attention in computer vision. The main challenge lies in the high degree of similarity between camouflaged objects and their surroundings in the spatial domain, making identification difficult. Existing methods attempt to reduce the impact of pixel similarity by maximizing the distinguishing ability of spatial features with complicated design, but often ignore the sensitivity and locality of features in the spatial domain, leading to sub-optimal results. In this paper, we propose a new approach to address this issue by jointly exploring the representation in the frequency and spatial domains, introducing the Frequency-Spatial Entanglement Learning (FSEL) method. This method consists of a series of well-designed Entanglement Transformer Blocks (ETB) for representation learning, a Joint Domain Perception Module for semantic enhancement, and a Dual-domain Reverse Parser for feature integration in the frequency and spatial domains. Specifically, the ETB utilizes frequency self-attention to effectively characterize the relationship between different frequency bands, while the entanglement feed-forward network facilitates information interaction between features of different domains through entanglement learning. Our extensive experiments demonstrate the superiority of our FSEL over 21 state-of-the-art methods, through comprehensive quantitative and qualitative comparisons in three widely-used datasets. The source code is available at: https://github.com/CSYSI/FSEL.