 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLCONet: Learning Multi-source Perception Representation for Camouflaged Object Detection
Sep 15, 2024



Recently, biological perception has been a powerful tool for handling the camouflaged object detection (COD) task. However, most existing methods are heavily dependent on the local spatial information of diverse scales from convolutional operations to optimize initial features. A commonly neglected point in these methods is the long-range dependencies between feature pixels from different scale spaces that can help the model build a global structure of the object, inducing a more precise image representation. In this paper, we propose a novel Global-Local Collaborative Optimization Network, called GLCONet. Technically, we first design a collaborative optimization strategy from the perspective of multi-source perception to simultaneously model the local details and global long-range relationships, which can provide features with abundant discriminative information to boost the accuracy in detecting camouflaged objects. Furthermore, we introduce an adjacent reverse decoder that contains cross-layer aggregation and reverse optimization to integrate complementary information from different levels for generating high-quality representations. Extensive experiments demonstrate that the proposed GLCONet method with different backbones can effectively activate potentially significant pixels in an image, outperforming twenty state-of-the-art methods on three public COD datasets. The source code is available at: \https://github.com/CSYSI/GLCONet.
Frequency-Spatial Entanglement Learning for Camouflaged Object Detection
Sep 03, 2024



Camouflaged object detection has attracted a lot of attention in computer vision. The main challenge lies in the high degree of similarity between camouflaged objects and their surroundings in the spatial domain, making identification difficult. Existing methods attempt to reduce the impact of pixel similarity by maximizing the distinguishing ability of spatial features with complicated design, but often ignore the sensitivity and locality of features in the spatial domain, leading to sub-optimal results. In this paper, we propose a new approach to address this issue by jointly exploring the representation in the frequency and spatial domains, introducing the Frequency-Spatial Entanglement Learning (FSEL) method. This method consists of a series of well-designed Entanglement Transformer Blocks (ETB) for representation learning, a Joint Domain Perception Module for semantic enhancement, and a Dual-domain Reverse Parser for feature integration in the frequency and spatial domains. Specifically, the ETB utilizes frequency self-attention to effectively characterize the relationship between different frequency bands, while the entanglement feed-forward network facilitates information interaction between features of different domains through entanglement learning. Our extensive experiments demonstrate the superiority of our FSEL over 21 state-of-the-art methods, through comprehensive quantitative and qualitative comparisons in three widely-used datasets. The source code is available at: https://github.com/CSYSI/FSEL.
Semi-Supervised Video Inpainting with Cycle Consistency Constraints
Aug 14, 2022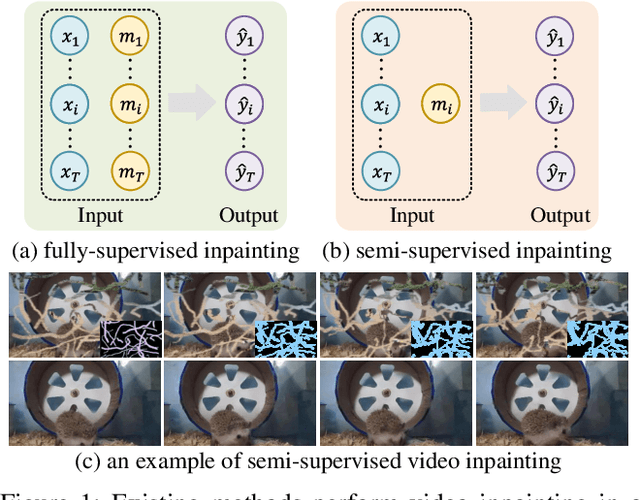
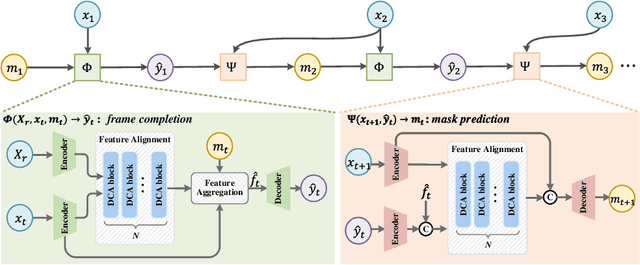

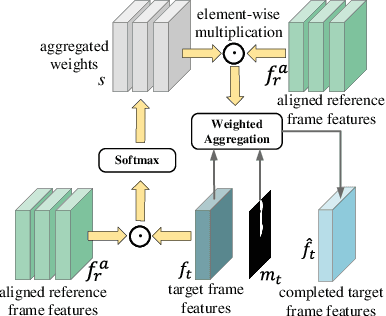
Deep learning-based video inpainting has yielded promising results and gained increasing attention from researchers. Generally, these methods usually assume that the corrupted region masks of each frame are known and easily obtained. However, the annotation of these masks are labor-intensive and expensive, which limits the practical application of current methods. Therefore, we expect to relax this assumption by defining a new semi-supervised inpainting setting, making the networks have the ability of completing the corrupted regions of the whole video using the annotated mask of only one frame. Specifically, in this work, we propose an end-to-end trainable framework consisting of completion network and mask prediction network, which are designed to generate corrupted contents of the current frame using the known mask and decide the regions to be filled of the next frame, respectively. Besides, we introduce a cycle consistency loss to regularize the training parameters of these two networks. In this way, the completion network and the mask prediction network can constrain each other, and hence the overall performance of the trained model can be maximized. Furthermore, due to the natural existence of prior knowledge (e.g., corrupted contents and clear borders), current video inpainting datasets are not suitable in the context of semi-supervised video inpainting. Thus, we create a new dataset by simulating the corrupted video of real-world scenarios. Extensive experimental results are reported to demonstrate the superiority of our model in the video inpainting task. Remarkably, although our model is trained in a semi-supervised manner, it can achieve comparable performance as fully-supervised methods.