 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Video Object Segmentation with Simplified Framework
Aug 19, 2023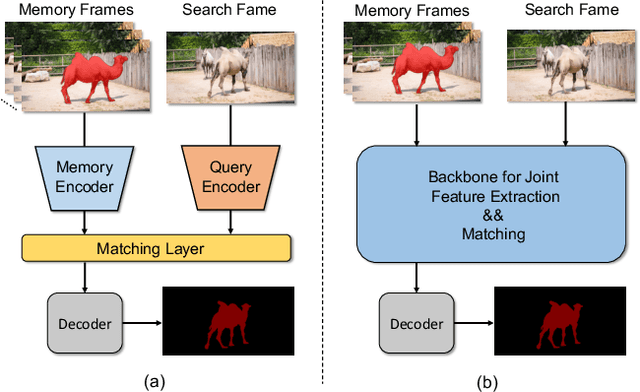
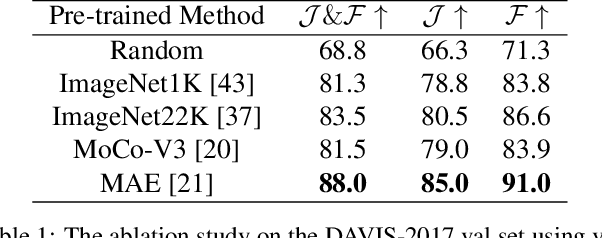
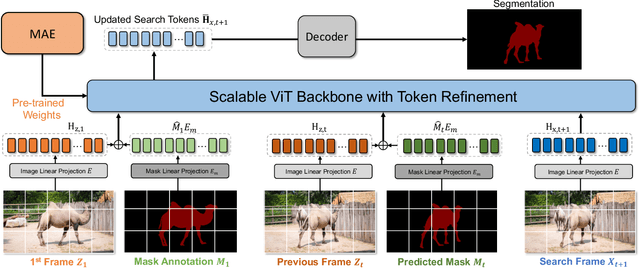
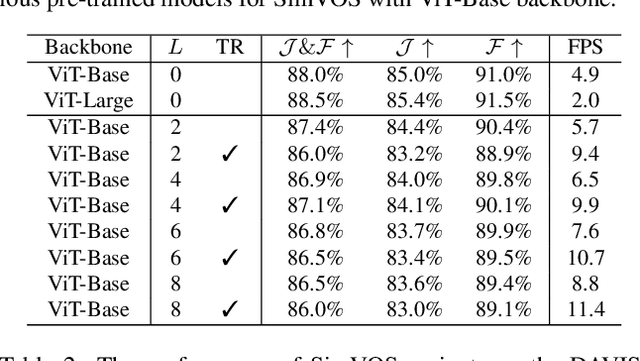
The current popular methods for video object segmentation (VOS) implement feature matching through several hand-crafted modules that separately perform feature extraction and matching. However, the above hand-crafted designs empirically cause insufficient target interaction, thus limiting the dynamic target-aware feature learning in VOS. To tackle these limitations, this paper presents a scalable Simplified VOS (SimVOS) framework to perform joint feature extraction and matching by leveraging a single transformer backbone. Specifically, SimVOS employs a scalable ViT backbone for simultaneous feature extraction and matching between query and reference features. This design enables SimVOS to learn better target-ware features for accurate mask prediction. More importantly, SimVOS could directly apply well-pretrained ViT backbones (e.g., MAE) for VOS, which bridges the gap between VOS and large-scale self-supervised pre-training. To achieve a better performance-speed trade-off, we further explore within-frame attention and propose a new token refinement module to improve the running speed and save computational cost. Experimentally, our SimVOS achieves state-of-the-art results on popular video object segmentation benchmarks, i.e., DAVIS-2017 (88.0% J&F), DAVIS-2016 (92.9% J&F) and YouTube-VOS 2019 (84.2% J&F), without applying any synthetic video or BL30K pre-training used in previous VOS approaches.
Edit Temporal-Consistent Videos with Image Diffusion Model
Aug 17, 2023



Large-scale text-to-image (T2I) diffusion models have been extended for text-guided video editing, yielding impressive zero-shot video editing performance. Nonetheless, the generated videos usually show spatial irregularities and temporal inconsistencies as the temporal characteristics of videos have not been faithfully modeled. In this paper, we propose an elegant yet effective Temporal-Consistent Video Editing (TCVE) method, to mitigate the temporal inconsistency challenge for robust text-guided video editing. In addition to the utilization of a pretrained 2D Unet for spatial content manipulation, we establish a dedicated temporal Unet architecture to faithfully capture the temporal coherence of the input video sequences. Furthermore, to establish coherence and interrelation between the spatial-focused and temporal-focused components, a cohesive joint spatial-temporal modeling unit is formulated. This unit effectively interconnects the temporal Unet with the pretrained 2D Unet, thereby enhancing the temporal consistency of the generated video output while simultaneously preserving the capacity for video content manipulation. Quantitative experimental results and visualization results demonstrate that TCVE achieves state-of-the-art performance in both video temporal consistency and video editing capability, surpassing existing benchmarks in the field.
Improved Fine-tuning by Leveraging Pre-training Data: Theory and Practice
Nov 24, 2021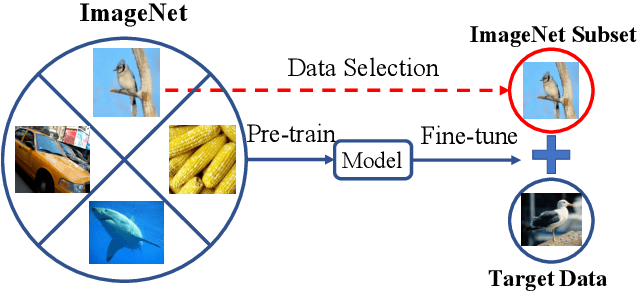
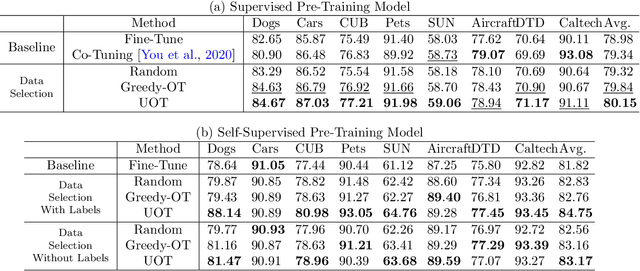
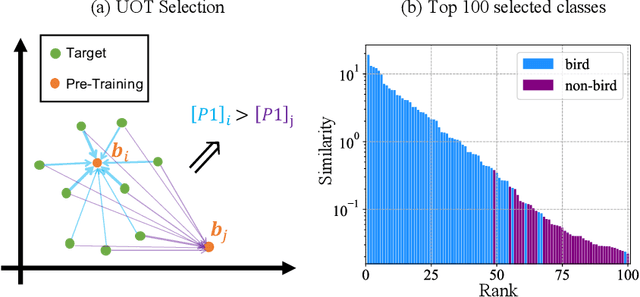

As a dominant paradigm, fine-tuning a pre-trained model on the target data is widely used in many deep learning applications, especially for small data sets. However, recent studies have empirically shown that training from scratch has the final performance that is no worse than this pre-training strategy once the number of training iterations is increased in some vision tasks. In this work, we revisit this phenomenon from the perspective of generalization analysis which is popular in learning theory. Our result reveals that the final prediction precision may have a weak dependency on the pre-trained model especially in the case of large training iterations. The observation inspires us to leverage pre-training data for fine-tuning, since this data is also available for fine-tuning. The generalization result of using pre-training data shows that the final performance on a target task can be improved when the appropriate pre-training data is included in fine-tuning. With the insight of the theoretical finding, we propose a novel selection strategy to select a subset from pre-training data to help improve the generalization on the target task. Extensive experimental results for image classification tasks on 8 benchmark data sets verify the effectiveness of the proposed data selection based fine-tuning pipeline.
Crowd Counting by Adaptively Fusing Predictions from an Image Pyramid
Sep 20, 2018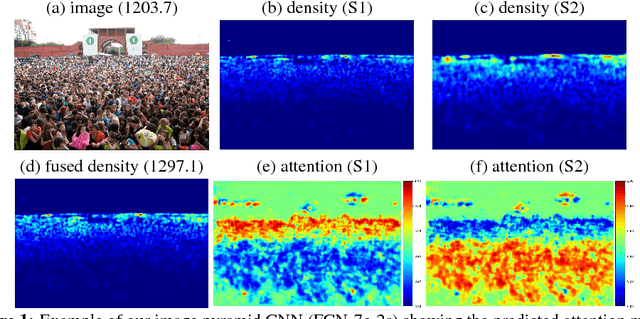
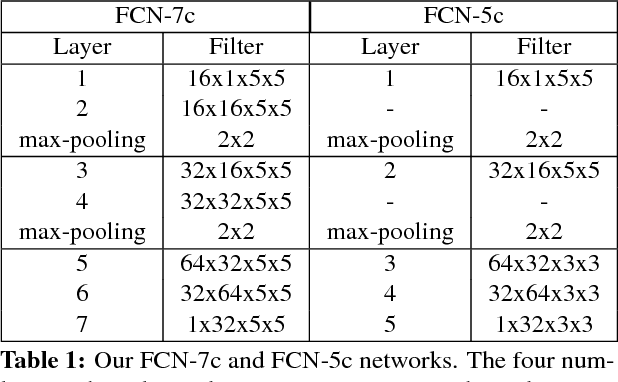
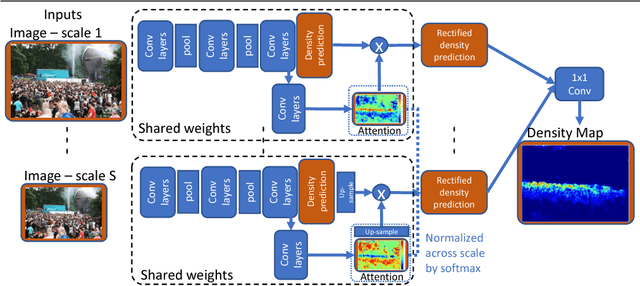
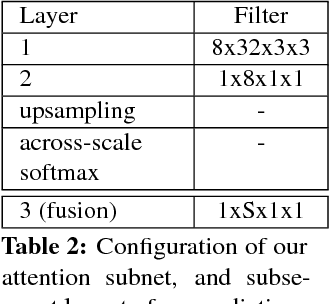
Because of the powerful learning capability of deep neural networks, counting performance via density map estimation has improved significantly during the past several years. However, it is still very challenging due to severe occlusion, large scale variations, and perspective distortion. Scale variations (from image to image) coupled with perspective distortion (within one image) result in huge scale changes of the object size. Earlier methods based on convolutional neural networks (CNN) typically did not handle this scale variation explicitly, until Hydra-CNN and MCNN. MCNN uses three columns, each with different filter sizes, to extract features at different scales. In this paper, in contrast to using filters of different sizes, we utilize an image pyramid to deal with scale variations. It is more effective and efficient to resize the input fed into the network, as compared to using larger filter sizes. Secondly, we adaptively fuse the predictions from different scales (using adaptively changing per-pixel weights), which makes our method adapt to scale changes within an image. The adaptive fusing is achieved by generating an across-scale attention map, which softly selects a suitable scale for each pixel, followed by a 1x1 convolution. Extensive experiments on three popular datasets show very compelling results.