 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Fine-tuning by Leveraging Pre-training Data: Theory and Practice
Paper and Code
Nov 24, 2021
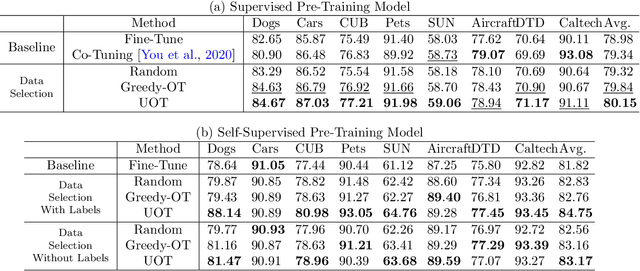
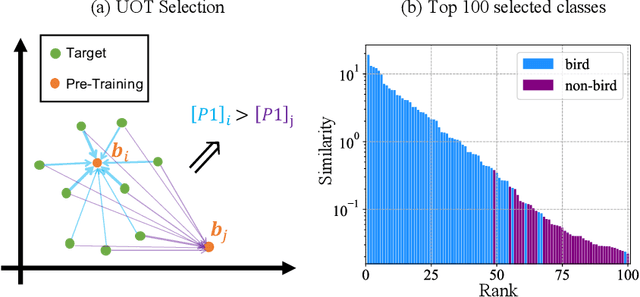

As a dominant paradigm, fine-tuning a pre-trained model on the target data is widely used in many deep learning applications, especially for small data sets. However, recent studies have empirically shown that training from scratch has the final performance that is no worse than this pre-training strategy once the number of training iterations is increased in some vision tasks. In this work, we revisit this phenomenon from the perspective of generalization analysis which is popular in learning theory. Our result reveals that the final prediction precision may have a weak dependency on the pre-trained model especially in the case of large training iterations. The observation inspires us to leverage pre-training data for fine-tuning, since this data is also available for fine-tuning. The generalization result of using pre-training data shows that the final performance on a target task can be improved when the appropriate pre-training data is included in fine-tuning. With the insight of the theoretical finding, we propose a novel selection strategy to select a subset from pre-training data to help improve the generalization on the target task. Extensive experimental results for image classification tasks on 8 benchmark data sets verify the effectiveness of the proposed data selection based fine-tuning pipeline.