 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Video Object Segmentation with Simplified Framework
Paper and Code
Aug 19, 2023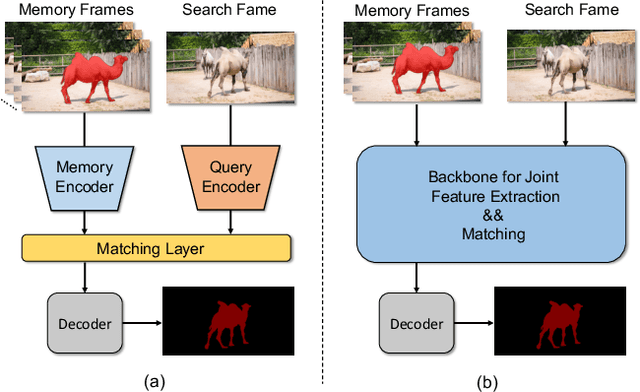
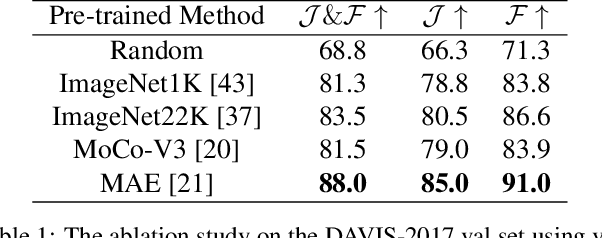
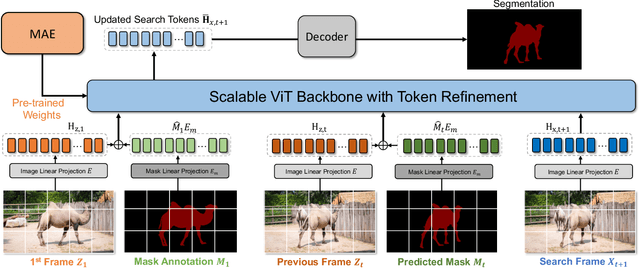
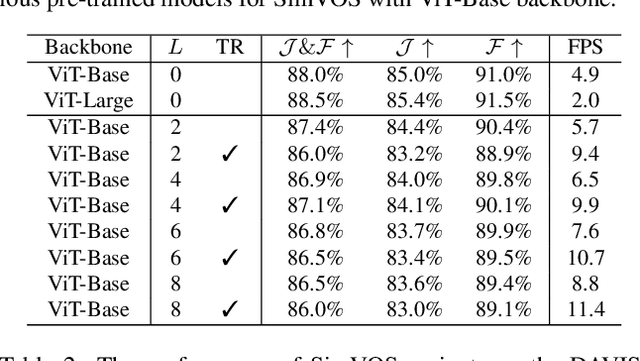
The current popular methods for video object segmentation (VOS) implement feature matching through several hand-crafted modules that separately perform feature extraction and matching. However, the above hand-crafted designs empirically cause insufficient target interaction, thus limiting the dynamic target-aware feature learning in VOS. To tackle these limitations, this paper presents a scalable Simplified VOS (SimVOS) framework to perform joint feature extraction and matching by leveraging a single transformer backbone. Specifically, SimVOS employs a scalable ViT backbone for simultaneous feature extraction and matching between query and reference features. This design enables SimVOS to learn better target-ware features for accurate mask prediction. More importantly, SimVOS could directly apply well-pretrained ViT backbones (e.g., MAE) for VOS, which bridges the gap between VOS and large-scale self-supervised pre-training. To achieve a better performance-speed trade-off, we further explore within-frame attention and propose a new token refinement module to improve the running speed and save computational cost. Experimentally, our SimVOS achieves state-of-the-art results on popular video object segmentation benchmarks, i.e., DAVIS-2017 (88.0% J&F), DAVIS-2016 (92.9% J&F) and YouTube-VOS 2019 (84.2% J&F), without applying any synthetic video or BL30K pre-training used in previous VOS approaches.