 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTANet: A new Paradigm for Global Face Super-resolution via Transformer-CNN Aggregation Network
Paper and Code
Sep 16, 2021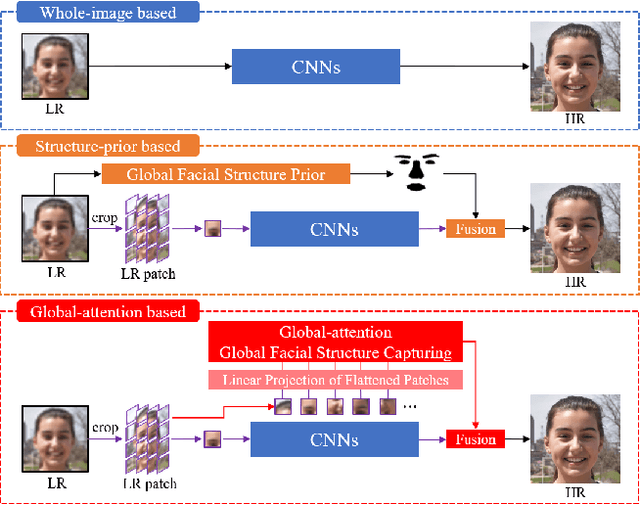
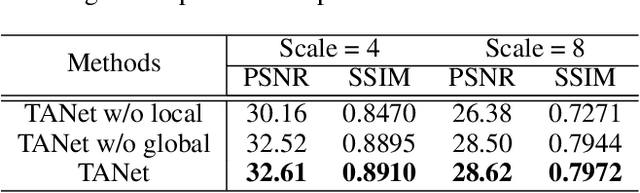
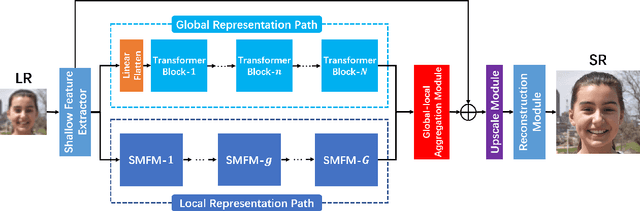
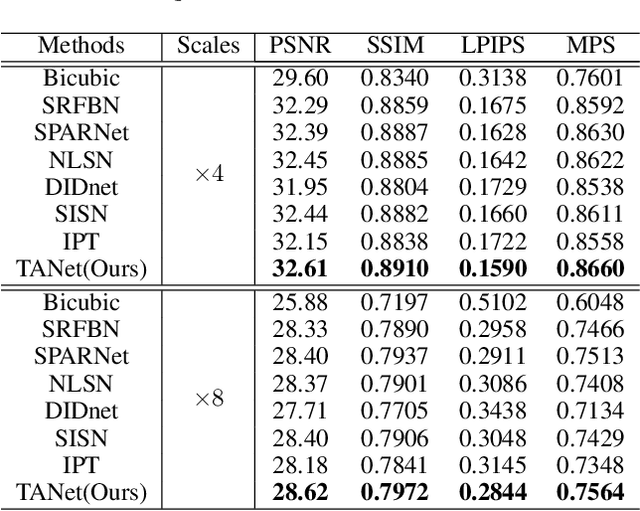
Recently, face super-resolution (FSR) methods either feed whole face image into convolutional neural networks (CNNs) or utilize extra facial priors (e.g., facial parsing maps, facial landmarks) to focus on facial structure, thereby maintaining the consistency of the facial structure while restoring facial details. However, the limited receptive fields of CNNs and inaccurate facial priors will reduce the naturalness and fidelity of the reconstructed face. In this paper, we propose a novel paradigm based on the self-attention mechanism (i.e., the core of Transformer) to fully explore the representation capacity of the facial structure feature. Specifically, we design a Transformer-CNN aggregation network (TANet) consisting of two paths, in which one path uses CNNs responsible for restoring fine-grained facial details while the other utilizes a resource-friendly Transformer to capture global information by exploiting the long-distance visual relation modeling. By aggregating the features from the above two paths, the consistency of global facial structure and fidelity of local facial detail restoration are strengthened simultaneously. Experimental results of face reconstruction and recognition verify that the proposed method can significantly outperform the state-of-the-art methods.