 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Second Challenge on Real-World Face Restoration at NTIRE 2026: Methods and Results
Apr 12, 2026This paper provides a review of the NTIRE 2026 challenge on real-world face restoration, highlighting the proposed solutions and the resulting outcomes. The challenge focuses on generating natural and realistic outputs while maintaining identity consistency. Its goal is to advance state-of-the-art solutions for perceptual quality and realism, without imposing constraints on computational resources or training data. Performance is evaluated using a weighted image quality assessment (IQA) score and employs the AdaFace model as an identity checker. The competition attracted 96 registrants, with 10 teams submitting valid models; ultimately, 9 teams achieved valid scores in the final ranking. This collaborative effort advances the performance of real-world face restoration while offering an in-depth overview of the latest trends in the field.
Word length-aware text spotting: Enhancing detection and recognition in dense text image
Dec 25, 2023Scene text spotting is essential in various computer vision applications, enabling extracting and interpreting textual information from images. However, existing methods often neglect the spatial semantics of word images, leading to suboptimal detection recall rates for long and short words within long-tailed word length distributions that exist prominently in dense scenes. In this paper, we present WordLenSpotter, a novel word length-aware spotter for scene text image detection and recognition, improving the spotting capabilities for long and short words, particularly in the tail data of dense text images. We first design an image encoder equipped with a dilated convolutional fusion module to integrate multiscale text image features effectively. Then, leveraging the Transformer framework, we synergistically optimize text detection and recognition accuracy after iteratively refining text region image features using the word length prior. Specially, we design a Spatial Length Predictor module (SLP) using character count prior tailored to different word lengths to constrain the regions of interest effectively. Furthermore, we introduce a specialized word Length-aware Segmentation (LenSeg) proposal head, enhancing the network's capacity to capture the distinctive features of long and short terms within categories characterized by long-tailed distributions. Comprehensive experiments on public datasets and our dense text spotting dataset DSTD1500 demonstrate the superiority of our proposed methods, particularly in dense text image detection and recognition tasks involving long-tailed word length distributions encompassing a range of long and short words.
TANet: A new Paradigm for Global Face Super-resolution via Transformer-CNN Aggregation Network
Sep 16, 2021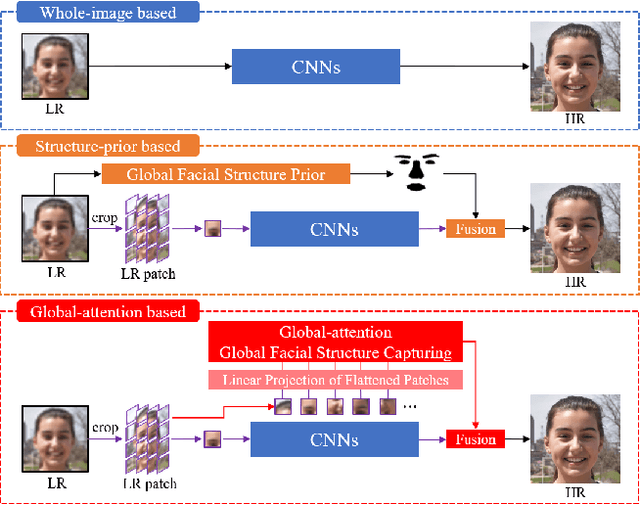
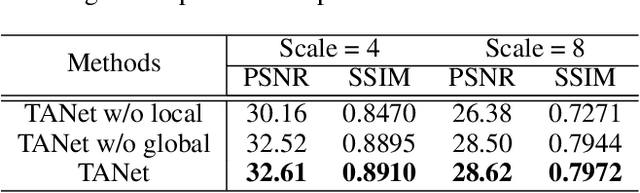
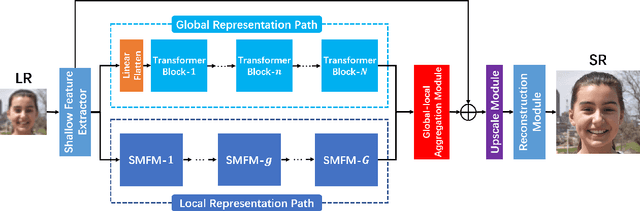
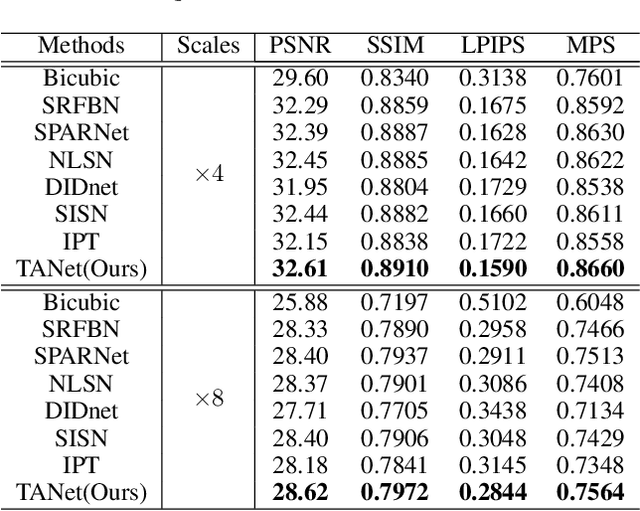
Recently, face super-resolution (FSR) methods either feed whole face image into convolutional neural networks (CNNs) or utilize extra facial priors (e.g., facial parsing maps, facial landmarks) to focus on facial structure, thereby maintaining the consistency of the facial structure while restoring facial details. However, the limited receptive fields of CNNs and inaccurate facial priors will reduce the naturalness and fidelity of the reconstructed face. In this paper, we propose a novel paradigm based on the self-attention mechanism (i.e., the core of Transformer) to fully explore the representation capacity of the facial structure feature. Specifically, we design a Transformer-CNN aggregation network (TANet) consisting of two paths, in which one path uses CNNs responsible for restoring fine-grained facial details while the other utilizes a resource-friendly Transformer to capture global information by exploiting the long-distance visual relation modeling. By aggregating the features from the above two paths, the consistency of global facial structure and fidelity of local facial detail restoration are strengthened simultaneously. Experimental results of face reconstruction and recognition verify that the proposed method can significantly outperform the state-of-the-art methods.
Multi-scale Self-calibrated Network for Image Light Source Transfer
Apr 18, 2021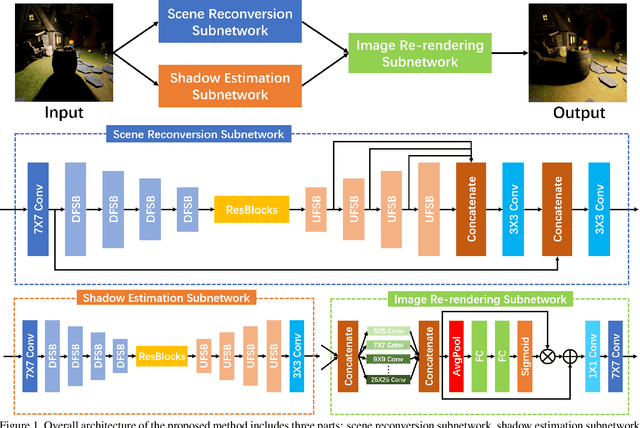
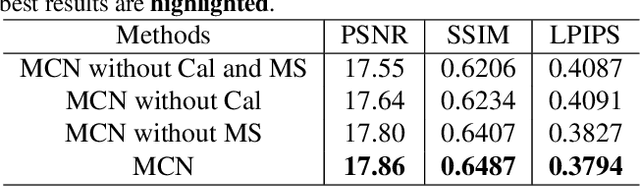
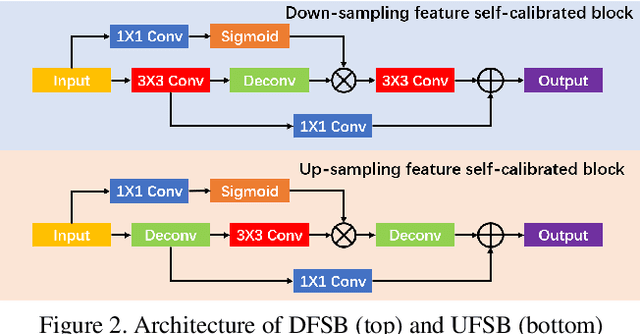
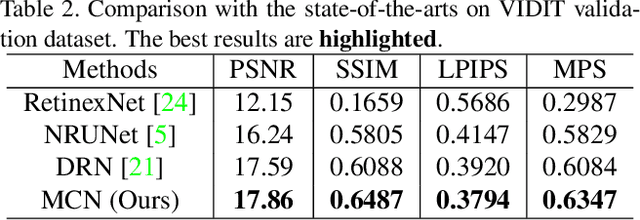
Image light source transfer (LLST), as the most challenging task in the domain of image relighting, has attracted extensive attention in recent years. In the latest research, LLST is decomposed three sub-tasks: scene reconversion, shadow estimation, and image re-rendering, which provides a new paradigm for image relighting. However, many problems for scene reconversion and shadow estimation tasks, including uncalibrated feature information and poor semantic information, are still unresolved, thereby resulting in insufficient feature representation. In this paper, we propose novel down-sampling feature self-calibrated block (DFSB) and up-sampling feature self-calibrated block (UFSB) as the basic blocks of feature encoder and decoder to calibrate feature representation iteratively because the LLST is similar to the recalibration of image light source. In addition, we fuse the multi-scale features of the decoder in scene reconversion task to further explore and exploit more semantic information, thereby providing more accurate primary scene structure for image re-rendering. Experimental results in the VIDIT dataset show that the proposed approach significantly improves the performance for LLST.
Face Hallucination Using Split-Attention in Split-Attention Network
Oct 22, 2020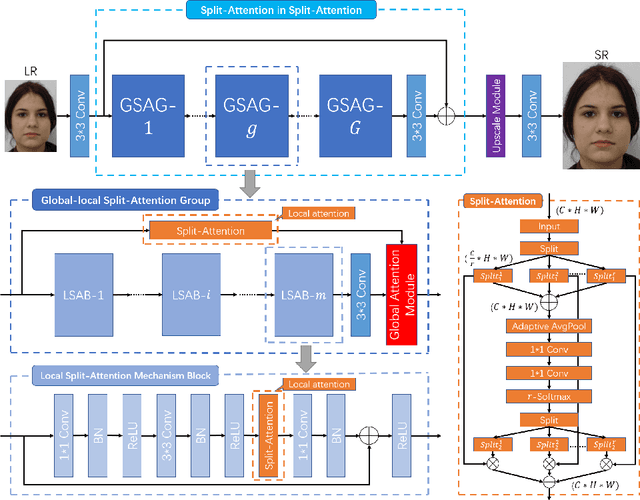


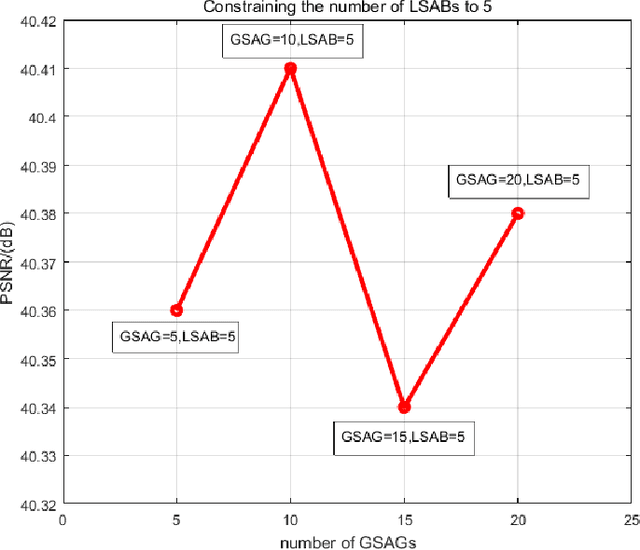
Face hallucination is a domain-specific super-resolution (SR), that generates high-resolution (HR) facial images from the observed one/multiple low-resolution (LR) input/s. Recently, convolutional neural networks(CNNs) are successfully applied into face hallucination to model the complex nonlinear mapping between HR and LR images. Although global attention mechanism equipped into CNNs naturally focus on the facial structure information, it always ignore the local and cross feature structure information, resulting in limited reconstruction performance. In order to solve this problem, we propose global-local split-attention mechanism and design a Split-Attention in Split-Attention (SIS) network to enable local attention across feature-map groups attaining global attention and to improve the ability of feature representations. SIS can generate and focus the local attention of neural network on the interaction of face key structure information in channel-level, thereby improve the performance of face image reconstruction. Experimental results show that the proposed approach consistently and significantly improves the reconstruction performances for face hallucination.
Feature-Driven Super-Resolution for Object Detection
Apr 01, 2020
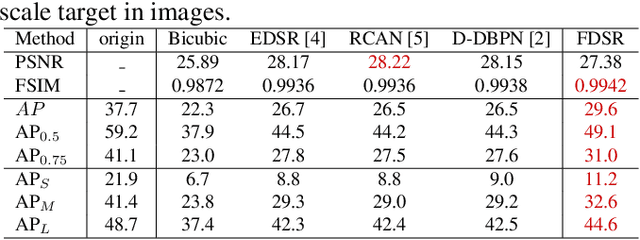
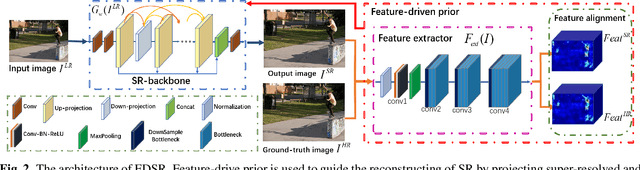
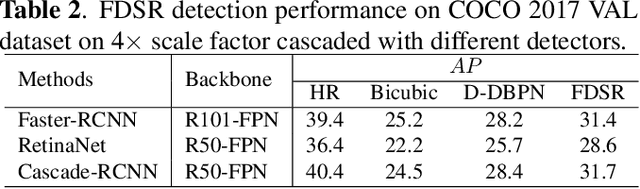
Although some convolutional neural networks (CNNs) based super-resolution (SR) algorithms yield good visual performances on single images recently. Most of them focus on perfect perceptual quality but ignore specific needs of subsequent detection task. This paper proposes a simple but powerful feature-driven super-resolution (FDSR) to improve the detection performance of low-resolution (LR) images. First, the proposed method uses feature-domain prior which extracts from an existing detector backbone to guide the HR image reconstruction. Then, with the aligned features, FDSR update SR parameters for better detection performance. Comparing with some state-of-the-art SR algorithms with 4$\times$ scale factor, FDSR outperforms the detection performance mAP on MS COCO validation, VOC2007 databases with good generalization to other detection networks.