 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning Multilingual News for Stock Return Prediction
Oct 22, 2025News spreads rapidly across languages and regions, but translations may lose subtle nuances. We propose a method to align sentences in multilingual news articles using optimal transport, identifying semantically similar content across languages. We apply this method to align more than 140,000 pairs of Bloomberg English and Japanese news articles covering around 3500 stocks in Tokyo exchange over 2012-2024. Aligned sentences are sparser, more interpretable, and exhibit higher semantic similarity. Return scores constructed from aligned sentences show stronger correlations with realized stock returns, and long-short trading strategies based on these alignments achieve 10\% higher Sharpe ratios than analyzing the full text sample.
Deep-MacroFin: Informed Equilibrium Neural Network for Continuous Time Economic Models
Aug 19, 2024In this paper, we present Deep-MacroFin, a comprehensive framework designed to solve partial differential equations, with a particular focus on models in continuous time economics. This framework leverages deep learning methodologies, including conventional Multi-Layer Perceptrons and the newly developed Kolmogorov-Arnold Networks. It is optimized using economic information encapsulated by Hamilton-Jacobi-Bellman equations and coupled algebraic equations. The application of neural networks holds the promise of accurately resolving high-dimensional problems with fewer computational demands and limitations compared to standard numerical methods. This versatile framework can be readily adapted for elementary differential equations, and systems of differential equations, even in cases where the solutions may exhibit discontinuities. Importantly, it offers a more straightforward and user-friendly implementation than existing libraries.
Multi-scale Self-calibrated Network for Image Light Source Transfer
Apr 18, 2021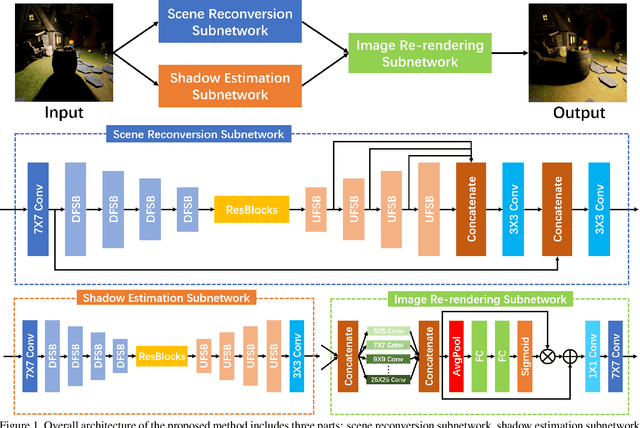
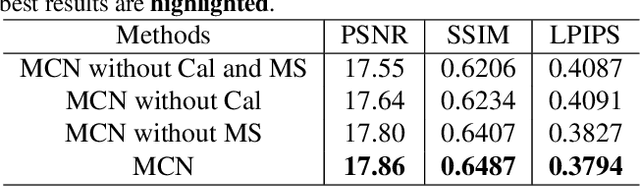
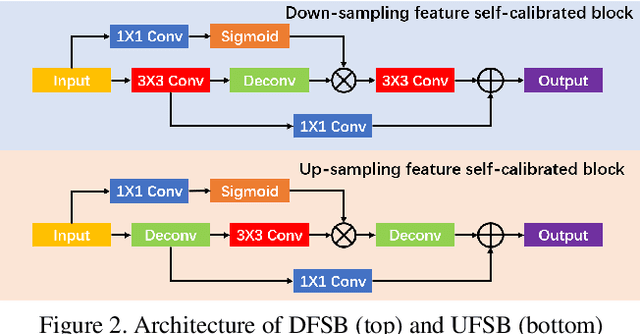
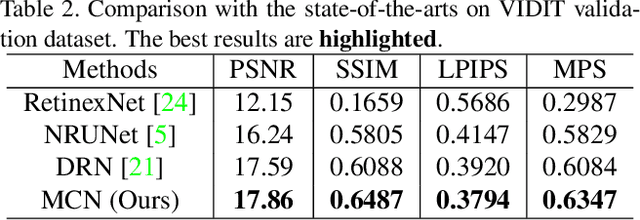
Image light source transfer (LLST), as the most challenging task in the domain of image relighting, has attracted extensive attention in recent years. In the latest research, LLST is decomposed three sub-tasks: scene reconversion, shadow estimation, and image re-rendering, which provides a new paradigm for image relighting. However, many problems for scene reconversion and shadow estimation tasks, including uncalibrated feature information and poor semantic information, are still unresolved, thereby resulting in insufficient feature representation. In this paper, we propose novel down-sampling feature self-calibrated block (DFSB) and up-sampling feature self-calibrated block (UFSB) as the basic blocks of feature encoder and decoder to calibrate feature representation iteratively because the LLST is similar to the recalibration of image light source. In addition, we fuse the multi-scale features of the decoder in scene reconversion task to further explore and exploit more semantic information, thereby providing more accurate primary scene structure for image re-rendering. Experimental results in the VIDIT dataset show that the proposed approach significantly improves the performance for LLST.