 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge language models enabled multiagent ensemble method for efficient EHR data labeling
Paper and Code
Oct 21, 2024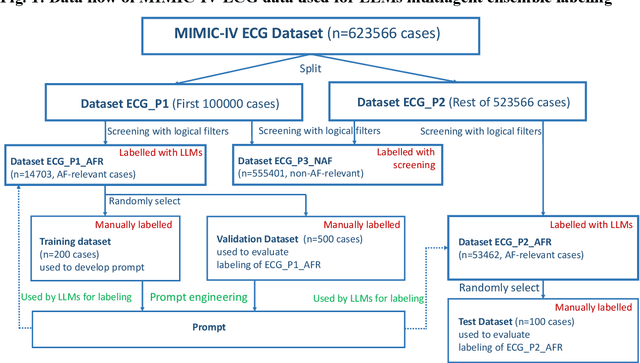
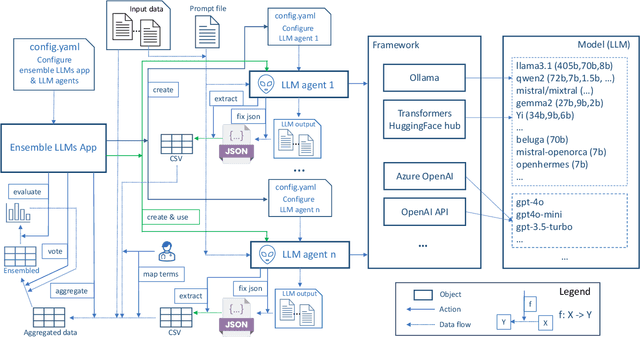
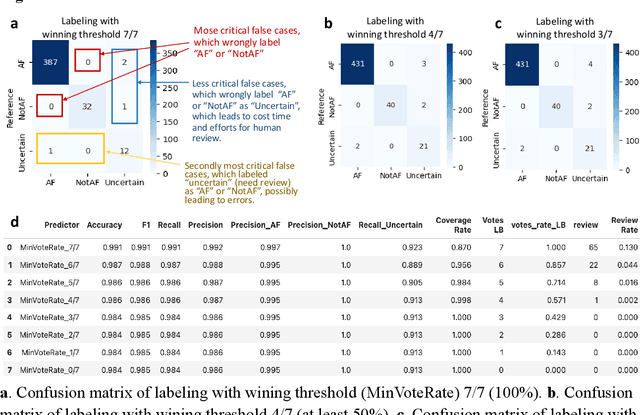
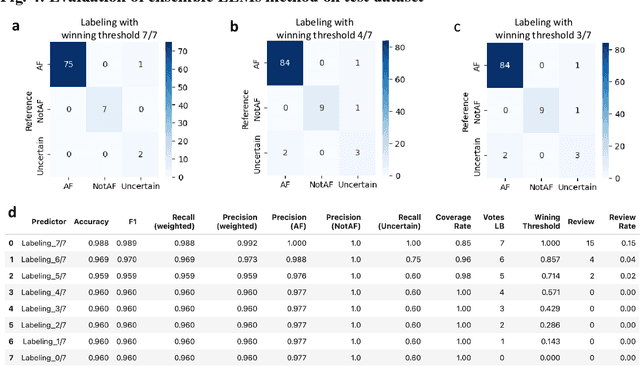
This study introduces a novel multiagent ensemble method powered by LLMs to address a key challenge in ML - data labeling, particularly in large-scale EHR datasets. Manual labeling of such datasets requires domain expertise and is labor-intensive, time-consuming, expensive, and error-prone. To overcome this bottleneck, we developed an ensemble LLMs method and demonstrated its effectiveness in two real-world tasks: (1) labeling a large-scale unlabeled ECG dataset in MIMIC-IV; (2) identifying social determinants of health (SDOH) from the clinical notes of EHR. Trading off benefits and cost, we selected a pool of diverse open source LLMs with satisfactory performance. We treat each LLM's prediction as a vote and apply a mechanism of majority voting with minimal winning threshold for ensemble. We implemented an ensemble LLMs application for EHR data labeling tasks. By using the ensemble LLMs and natural language processing, we labeled MIMIC-IV ECG dataset of 623,566 ECG reports with an estimated accuracy of 98.2%. We applied the ensemble LLMs method to identify SDOH from social history sections of 1,405 EHR clinical notes, also achieving competitive performance. Our experiments show that the ensemble LLMs can outperform individual LLM even the best commercial one, and the method reduces hallucination errors. From the research, we found that (1) the ensemble LLMs method significantly reduces the time and effort required for labeling large-scale EHR data, automating the process with high accuracy and quality; (2) the method generalizes well to other text data labeling tasks, as shown by its application to SDOH identification; (3) the ensemble of a group of diverse LLMs can outperform or match the performance of the best individual LLM; and (4) the ensemble method substantially reduces hallucination errors. This approach provides a scalable and efficient solution to data-labeling challenges.