 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge language models enabled multiagent ensemble method for efficient EHR data labeling
Oct 21, 2024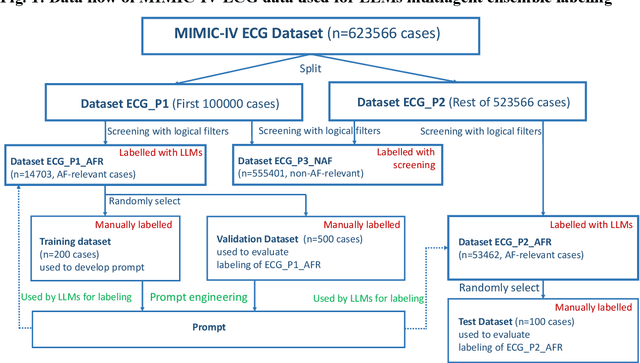
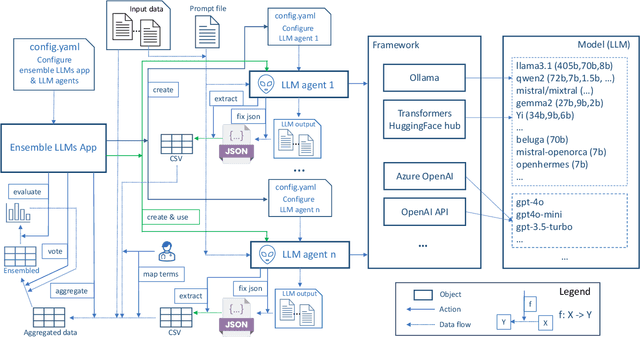
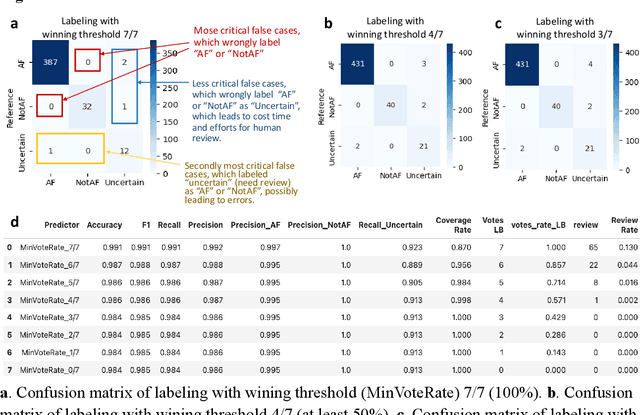
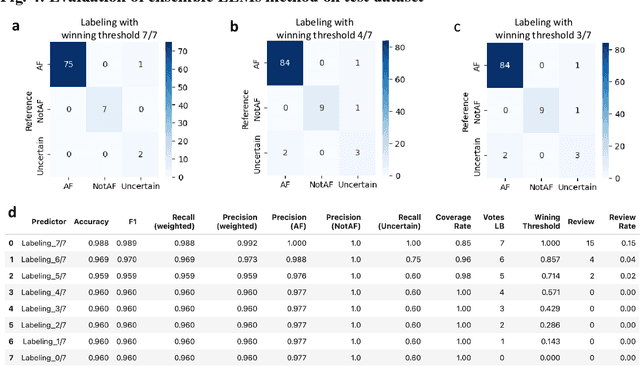
This study introduces a novel multiagent ensemble method powered by LLMs to address a key challenge in ML - data labeling, particularly in large-scale EHR datasets. Manual labeling of such datasets requires domain expertise and is labor-intensive, time-consuming, expensive, and error-prone. To overcome this bottleneck, we developed an ensemble LLMs method and demonstrated its effectiveness in two real-world tasks: (1) labeling a large-scale unlabeled ECG dataset in MIMIC-IV; (2) identifying social determinants of health (SDOH) from the clinical notes of EHR. Trading off benefits and cost, we selected a pool of diverse open source LLMs with satisfactory performance. We treat each LLM's prediction as a vote and apply a mechanism of majority voting with minimal winning threshold for ensemble. We implemented an ensemble LLMs application for EHR data labeling tasks. By using the ensemble LLMs and natural language processing, we labeled MIMIC-IV ECG dataset of 623,566 ECG reports with an estimated accuracy of 98.2%. We applied the ensemble LLMs method to identify SDOH from social history sections of 1,405 EHR clinical notes, also achieving competitive performance. Our experiments show that the ensemble LLMs can outperform individual LLM even the best commercial one, and the method reduces hallucination errors. From the research, we found that (1) the ensemble LLMs method significantly reduces the time and effort required for labeling large-scale EHR data, automating the process with high accuracy and quality; (2) the method generalizes well to other text data labeling tasks, as shown by its application to SDOH identification; (3) the ensemble of a group of diverse LLMs can outperform or match the performance of the best individual LLM; and (4) the ensemble method substantially reduces hallucination errors. This approach provides a scalable and efficient solution to data-labeling challenges.
Evaluate underdiagnosis and overdiagnosis bias of deep learning model on primary open-angle glaucoma diagnosis in under-served patient populations
Jan 29, 2023



In the United States, primary open-angle glaucoma (POAG) is the leading cause of blindness, especially among African American and Hispanic individuals. Deep learning has been widely used to detect POAG using fundus images as its performance is comparable to or even surpasses diagnosis by clinicians. However, human bias in clinical diagnosis may be reflected and amplified in the widely-used deep learning models, thus impacting their performance. Biases may cause (1) underdiagnosis, increasing the risks of delayed or inadequate treatment, and (2) overdiagnosis, which may increase individuals' stress, fear, well-being, and unnecessary/costly treatment. In this study, we examined the underdiagnosis and overdiagnosis when applying deep learning in POAG detection based on the Ocular Hypertension Treatment Study (OHTS) from 22 centers across 16 states in the United States. Our results show that the widely-used deep learning model can underdiagnose or overdiagnose underserved populations. The most underdiagnosed group is female younger (< 60 yrs) group, and the most overdiagnosed group is Black older (>=60 yrs) group. Biased diagnosis through traditional deep learning methods may delay disease detection, treatment and create burdens among under-served populations, thereby, raising ethical concerns about using deep learning models in ophthalmology clinics.
* 9 pages, 2 figures, Accepted by AMIA 2023 Informatics Summit
Bootstrapping Your Own Positive Sample: Contrastive Learning With Electronic Health Record Data
Apr 07, 2021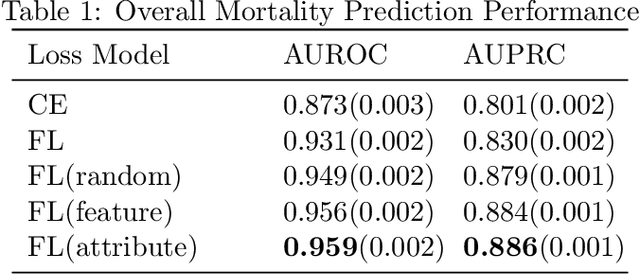



Electronic Health Record (EHR) data has been of tremendous utility in Artificial Intelligence (AI) for healthcare such as predicting future clinical events. These tasks, however, often come with many challenges when using classical machine learning models due to a myriad of factors including class imbalance and data heterogeneity (i.e., the complex intra-class variances). To address some of these research gaps, this paper leverages the exciting contrastive learning framework and proposes a novel contrastive regularized clinical classification model. The contrastive loss is found to substantially augment EHR-based prediction: it effectively characterizes the similar/dissimilar patterns (by its "push-and-pull" form), meanwhile mitigating the highly skewed class distribution by learning more balanced feature spaces (as also echoed by recent findings). In particular, when naively exporting the contrastive learning to the EHR data, one hurdle is in generating positive samples, since EHR data is not as amendable to data augmentation as image data. To this end, we have introduced two unique positive sampling strategies specifically tailored for EHR data: a feature-based positive sampling that exploits the feature space neighborhood structure to reinforce the feature learning; and an attribute-based positive sampling that incorporates pre-generated patient similarity metrics to define the sample proximity. Both sampling approaches are designed with an awareness of unique high intra-class variance in EHR data. Our overall framework yields highly competitive experimental results in predicting the mortality risk on real-world COVID-19 EHR data with a total of 5,712 patients admitted to a large, urban health system. Specifically, our method reaches a high AUROC prediction score of 0.959, which outperforms other baselines and alternatives: cross-entropy(0.873) and focal loss(0.931).
Contrastive Learning Improves Critical Event Prediction in COVID-19 Patients
Jan 11, 2021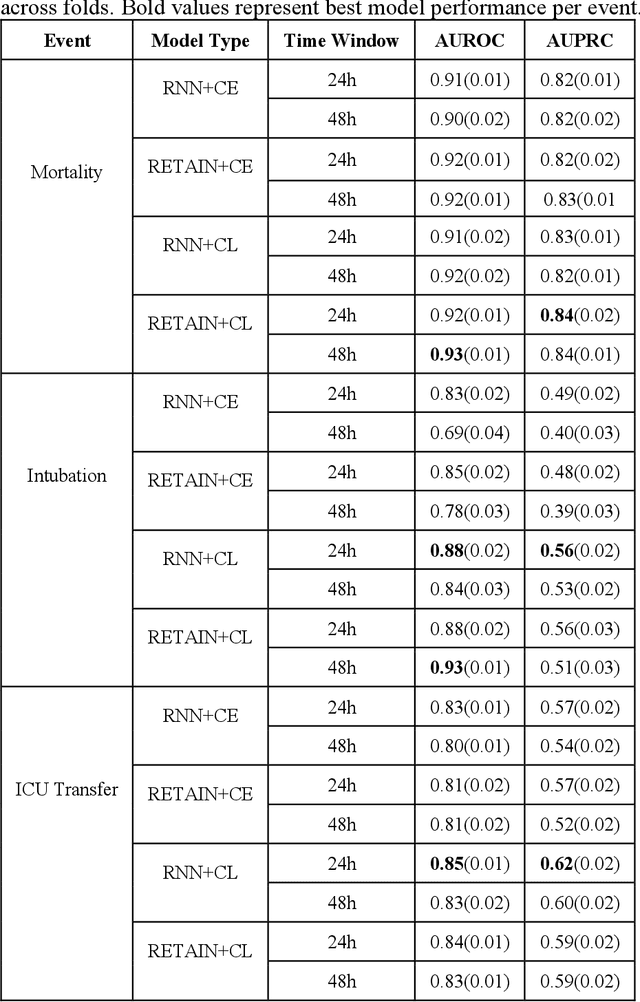
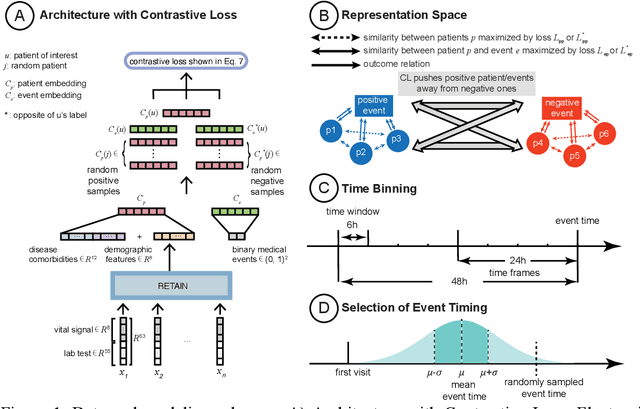
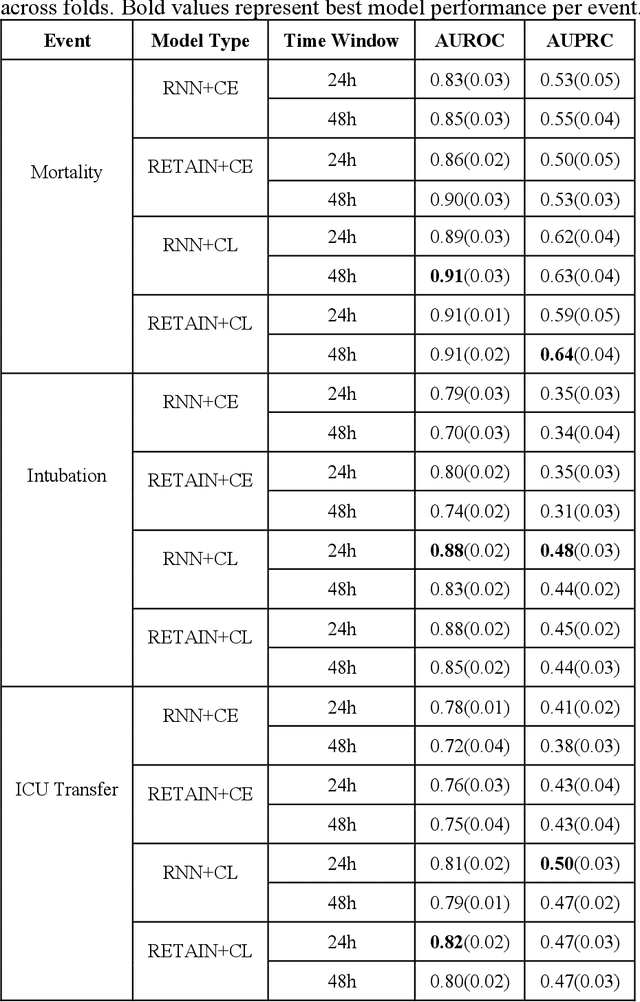
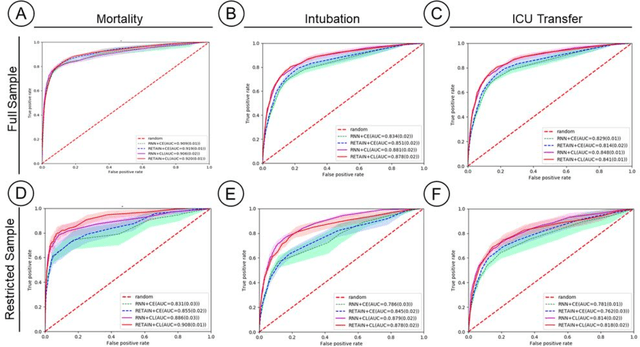
Machine Learning (ML) models typically require large-scale, balanced training data to be robust, generalizable, and effective in the context of healthcare. This has been a major issue for developing ML models for the coronavirus-disease 2019 (COVID-19) pandemic where data is highly imbalanced, particularly within electronic health records (EHR) research. Conventional approaches in ML use cross-entropy loss (CEL) that often suffers from poor margin classification. For the first time, we show that contrastive loss (CL) improves the performance of CEL especially for imbalanced EHR data and the related COVID-19 analyses. This study has been approved by the Institutional Review Board at the Icahn School of Medicine at Mount Sinai. We use EHR data from five hospitals within the Mount Sinai Health System (MSHS) to predict mortality, intubation, and intensive care unit (ICU) transfer in hospitalized COVID-19 patients over 24 and 48 hour time windows. We train two sequential architectures (RNN and RETAIN) using two loss functions (CEL and CL). Models are tested on full sample data set which contain all available data and restricted data set to emulate higher class imbalance.CL models consistently outperform CEL models with the restricted data set on these tasks with differences ranging from 0.04 to 0.15 for AUPRC and 0.05 to 0.1 for AUROC. For the restricted sample, only the CL model maintains proper clustering and is able to identify important features, such as pulse oximetry. CL outperforms CEL in instances of severe class imbalance, on three EHR outcomes with respect to three performance metrics: predictive power, clustering, and feature importance. We believe that the developed CL framework can be expanded and used for EHR ML work in general.
Deep Learning with Heterogeneous Graph Embeddings for Mortality Prediction from Electronic Health Records
Dec 28, 2020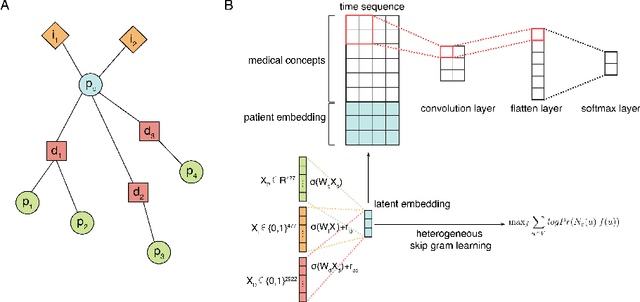
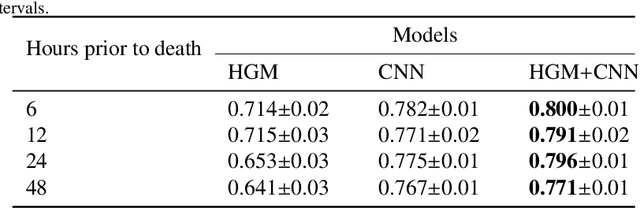
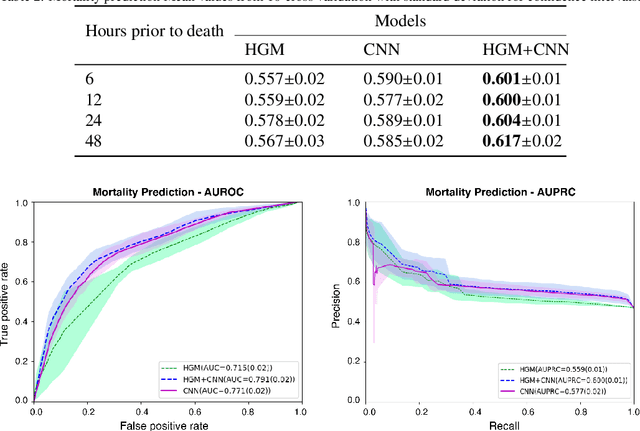
Computational prediction of in-hospital mortality in the setting of an intensive care unit can help clinical practitioners to guide care and make early decisions for interventions. As clinical data are complex and varied in their structure and components, continued innovation of modeling strategies is required to identify architectures that can best model outcomes. In this work, we train a Heterogeneous Graph Model (HGM) on Electronic Health Record data and use the resulting embedding vector as additional information added to a Convolutional Neural Network (CNN) model for predicting in-hospital mortality. We show that the additional information provided by including time as a vector in the embedding captures the relationships between medical concepts, lab tests, and diagnoses, which enhances predictive performance. We find that adding HGM to a CNN model increases the mortality prediction accuracy up to 4\%. This framework serves as a foundation for future experiments involving different EHR data types on important healthcare prediction tasks.
Biomedical Knowledge Graph Refinement and Completion using Graph Representation Learning and Top-K Similarity Measure
Dec 18, 2020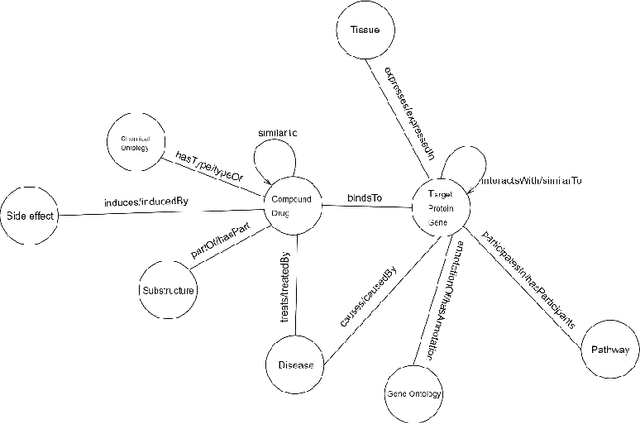

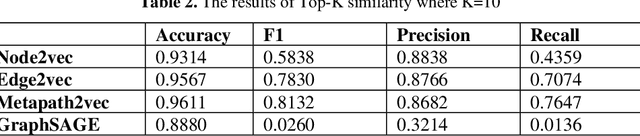
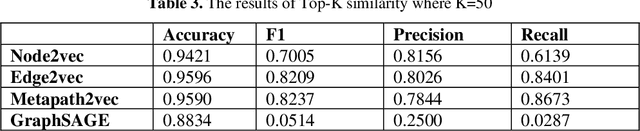
Knowledge Graphs have been one of the fundamental methods for integrating heterogeneous data sources. Integrating heterogeneous data sources is crucial, especially in the biomedical domain, where central data-driven tasks such as drug discovery rely on incorporating information from different biomedical databases. These databases contain various biological entities and relations such as proteins (PDB), genes (Gene Ontology), drugs (DrugBank), diseases (DDB), and protein-protein interactions (BioGRID). The process of semantically integrating heterogeneous biomedical databases is often riddled with imperfections. The quality of data-driven drug discovery relies on the accuracy of the mining methods used and the data's quality as well. Thus, having complete and refined biomedical knowledge graphs is central to achieving more accurate drug discovery outcomes. Here we propose using the latest graph representation learning and embedding models to refine and complete biomedical knowledge graphs. This preliminary work demonstrates learning discrete representations of the integrated biomedical knowledge graph Chem2Bio2RD [3]. We perform a knowledge graph completion and refinement task using a simple top-K cosine similarity measure between the learned embedding vectors to predict missing links between drugs and targets present in the data. We show that this simple procedure can be used alternatively to binary classifiers in link prediction.
Attribute2vec: Deep Network Embedding Through Multi-Filtering GCN
Apr 03, 2020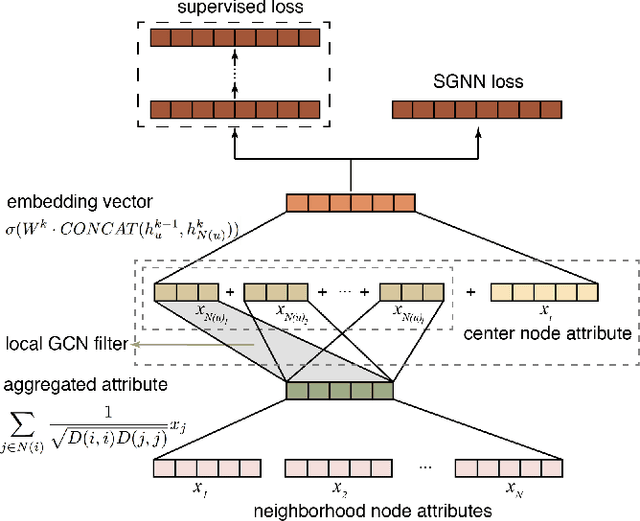
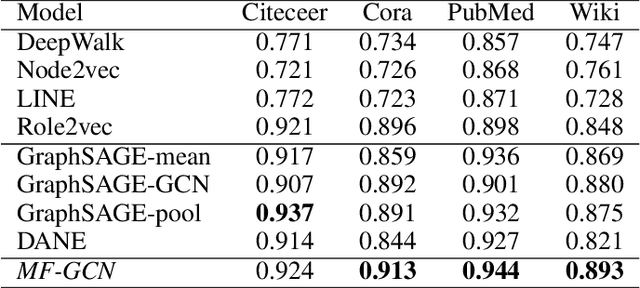
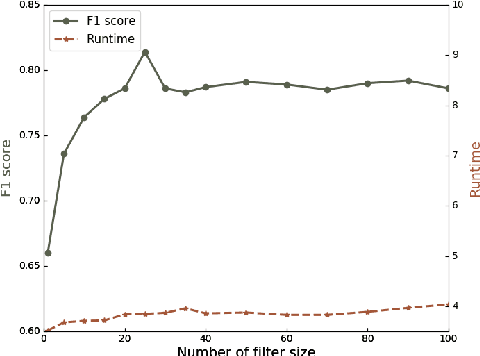
We present a multi-filtering Graph Convolution Neural Network (GCN) framework for network embedding task. It uses multiple local GCN filters to do feature extraction in every propagation layer. We show this approach could capture different important aspects of node features against the existing attribute embedding based method. We also show that with multi-filtering GCN approach, we can achieve significant improvement against baseline methods when training data is limited. We also perform many empirical experiments and demonstrate the benefit of using multiple filters against single filter as well as most current existing network embedding methods for both the link prediction and node classification tasks.