 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBootstrapping Your Own Positive Sample: Contrastive Learning With Electronic Health Record Data
Paper and Code
Apr 07, 2021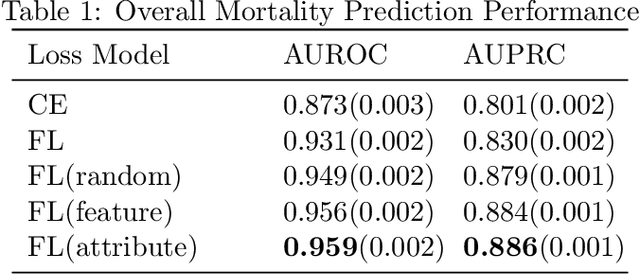



Electronic Health Record (EHR) data has been of tremendous utility in Artificial Intelligence (AI) for healthcare such as predicting future clinical events. These tasks, however, often come with many challenges when using classical machine learning models due to a myriad of factors including class imbalance and data heterogeneity (i.e., the complex intra-class variances). To address some of these research gaps, this paper leverages the exciting contrastive learning framework and proposes a novel contrastive regularized clinical classification model. The contrastive loss is found to substantially augment EHR-based prediction: it effectively characterizes the similar/dissimilar patterns (by its "push-and-pull" form), meanwhile mitigating the highly skewed class distribution by learning more balanced feature spaces (as also echoed by recent findings). In particular, when naively exporting the contrastive learning to the EHR data, one hurdle is in generating positive samples, since EHR data is not as amendable to data augmentation as image data. To this end, we have introduced two unique positive sampling strategies specifically tailored for EHR data: a feature-based positive sampling that exploits the feature space neighborhood structure to reinforce the feature learning; and an attribute-based positive sampling that incorporates pre-generated patient similarity metrics to define the sample proximity. Both sampling approaches are designed with an awareness of unique high intra-class variance in EHR data. Our overall framework yields highly competitive experimental results in predicting the mortality risk on real-world COVID-19 EHR data with a total of 5,712 patients admitted to a large, urban health system. Specifically, our method reaches a high AUROC prediction score of 0.959, which outperforms other baselines and alternatives: cross-entropy(0.873) and focal loss(0.931).