 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMRGazer: Decoding Eye Gaze Points from Functional Magnetic Resonance Imaging in Individual Space
Nov 27, 2023Eye-tracking research has proven valuable in understanding numerous cognitive functions. Recently, Frey et al. provided an exciting deep learning method for learning eye movements from fMRI data. However, it needed to co-register fMRI into standard space to obtain eyeballs masks, and thus required additional templates and was time consuming. To resolve this issue, in this paper, we propose a framework named MRGazer for predicting eye gaze points from fMRI in individual space. The MRGazer consisted of eyeballs extraction module and a residual network-based eye gaze prediction. Compared to the previous method, the proposed framework skips the fMRI co-registration step, simplifies the processing protocol and achieves end-to-end eye gaze regression. The proposed method achieved superior performance in a variety of eye movement tasks than the co-registration-based method, and delivered objective results within a shorter time (~ 0.02 Seconds for each volume) than prior method (~0.3 Seconds for each volume).
Attention module improves both performance and interpretability of 4D fMRI decoding neural network
Oct 03, 2021
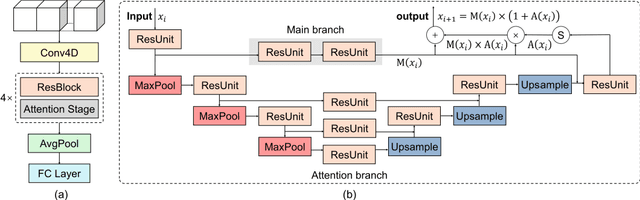

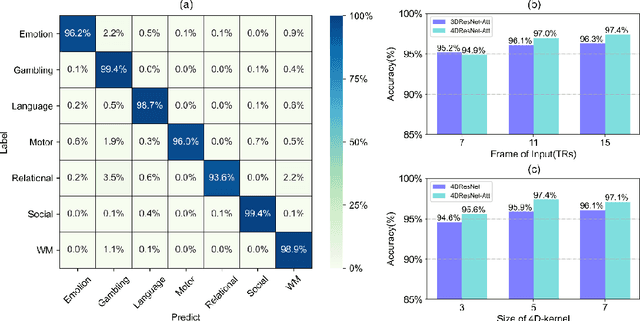
Decoding brain cognitive states from neuroimaging signals is an important topic in neuroscience. In recent years, deep neural networks (DNNs) have been recruited for multiple brain state decoding and achieved good performance. However, the open question of how to interpret the DNN black box remains unanswered. Capitalizing on advances in machine learning, we integrated attention modules into brain decoders to facilitate an in-depth interpretation of DNN channels. A 4D convolution operation was also included to extract temporo-spatial interaction within the fMRI signal. The experiments showed that the proposed model obtains a very high accuracy (97.4%) and outperforms previous researches on the 7 different task benchmarks from the Human Connectome Project (HCP) dataset. The visualization analysis further illustrated the hierarchical emergence of task-specific masks with depth. Finally, the model was retrained to regress individual traits within the HCP and to classify viewing images from the BOLD5000 dataset, respectively. Transfer learning also achieves good performance. A further visualization analysis shows that, after transfer learning, low-level attention masks remained similar to the source domain, whereas high-level attention masks changed adaptively. In conclusion, the proposed 4D model with attention module performed well and facilitated interpretation of DNNs, which is helpful for subsequent research.